 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurb Your Carbon Emissions: Benchmarking Carbon Emissions in Machine Translation
Oct 11, 2021
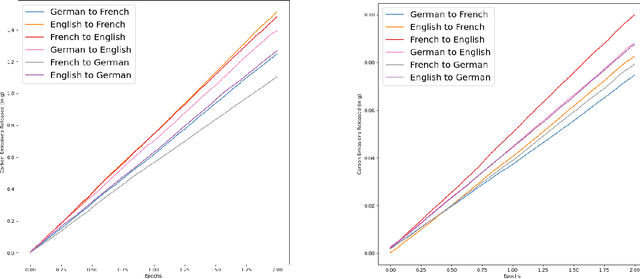
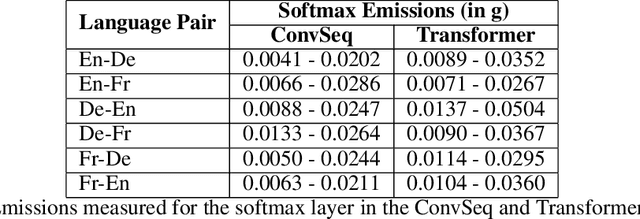

In recent times, there has been definitive progress in the field of NLP, with its applications growing as the utility of our language models increases with advances in their performance. However, these models require a large amount of computational power and data to train, consequently leading to large carbon footprints. Therefore, it is imperative that we study the carbon efficiency and look for alternatives to reduce the overall environmental impact of training models, in particular large language models. In our work, we assess the performance of models for machine translation, across multiple language pairs to assess the difference in computational power required to train these models for each of these language pairs and examine the various components of these models to analyze aspects of our pipeline that can be optimized to reduce these carbon emissions.