 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially Robust Prototypical Few-shot Segmentation with Neural-ODEs
Oct 07, 2022Few-shot Learning (FSL) methods are being adopted in settings where data is not abundantly available. This is especially seen in medical domains where the annotations are expensive to obtain. Deep Neural Networks have been shown to be vulnerable to adversarial attacks. This is even more severe in the case of FSL due to the lack of a large number of training examples. In this paper, we provide a framework to make few-shot segmentation models adversarially robust in the medical domain where such attacks can severely impact the decisions made by clinicians who use them. We propose a novel robust few-shot segmentation framework, Prototypical Neural Ordinary Differential Equation (PNODE), that provides defense against gradient-based adversarial attacks. We show that our framework is more robust compared to traditional adversarial defense mechanisms such as adversarial training. Adversarial training involves increased training time and shows robustness to limited types of attacks depending on the type of adversarial examples seen during training. Our proposed framework generalises well to common adversarial attacks like FGSM, PGD and SMIA while having the model parameters comparable to the existing few-shot segmentation models. We show the effectiveness of our proposed approach on three publicly available multi-organ segmentation datasets in both in-domain and cross-domain settings by attacking the support and query sets without the need for ad-hoc adversarial training.
ExCode-Mixed: Explainable Approaches towards Sentiment Analysis on Code-Mixed Data using BERT models
Sep 25, 2021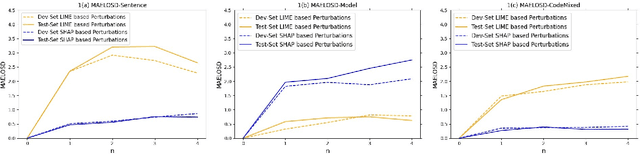
The increasing use of social media sites in countries like India has given rise to large volumes of code-mixed data. Sentiment analysis of this data can provide integral insights into people's perspectives and opinions. Developing robust explainability techniques which explain why models make their predictions becomes essential. In this paper, we propose an adequate methodology to integrate explainable approaches into code-mixed sentiment analysis.
Towards Quantifying the Carbon Emissions of Differentially Private Machine Learning
Jul 14, 2021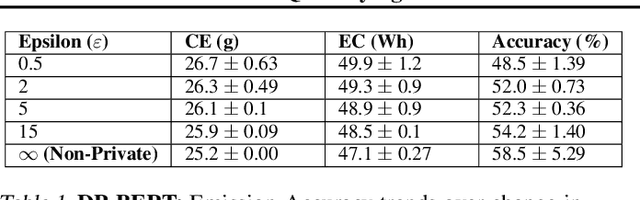
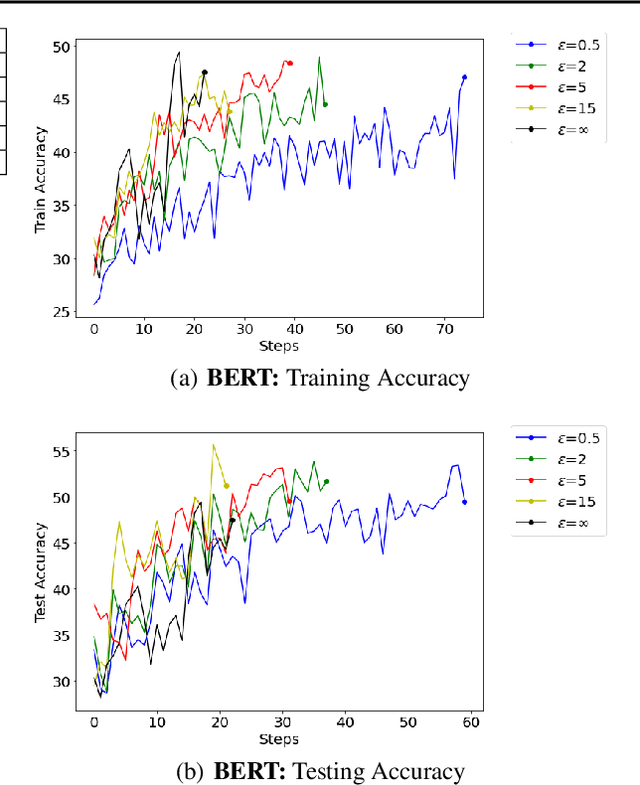
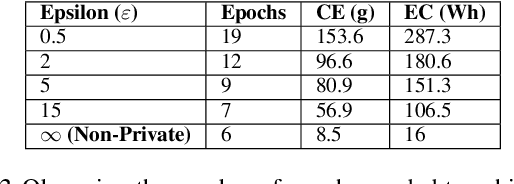
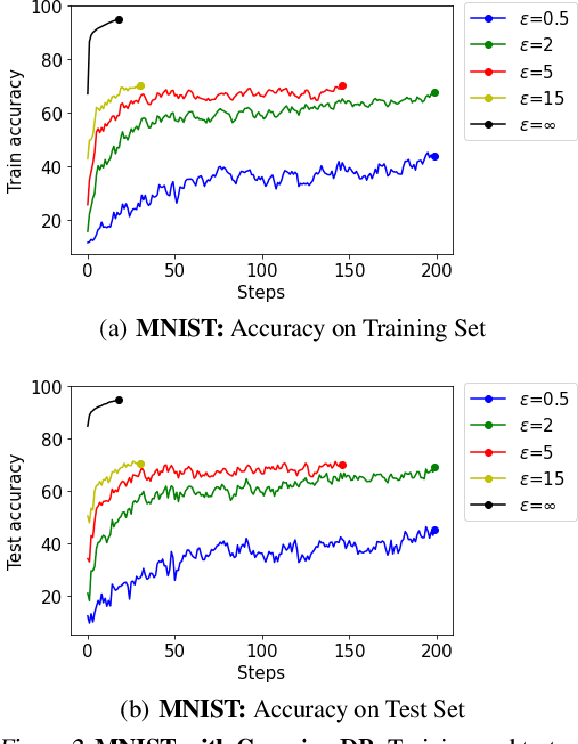
In recent years, machine learning techniques utilizing large-scale datasets have achieved remarkable performance. Differential privacy, by means of adding noise, provides strong privacy guarantees for such learning algorithms. The cost of differential privacy is often a reduced model accuracy and a lowered convergence speed. This paper investigates the impact of differential privacy on learning algorithms in terms of their carbon footprint due to either longer run-times or failed experiments. Through extensive experiments, further guidance is provided on choosing the noise levels which can strike a balance between desired privacy levels and reduced carbon emissions.