 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama-3.1-FoundationAI-SecurityLLM-Reasoning-8B Technical Report
Jan 28, 2026We present Foundation-Sec-8B-Reasoning, the first open-source native reasoning model for cybersecurity. Built upon our previously released Foundation-Sec-8B base model (derived from Llama-3.1-8B-Base), the model is trained through a two-stage process combining supervised fine-tuning (SFT) and reinforcement learning from verifiable rewards (RLVR). Our training leverages proprietary reasoning data spanning cybersecurity analysis, instruction-following, and mathematical reasoning. Evaluation across 10 cybersecurity benchmarks and 10 general-purpose benchmarks demonstrates performance competitive with significantly larger models on cybersecurity tasks while maintaining strong general capabilities. The model shows effective generalization on multi-hop reasoning tasks and strong safety performance when deployed with appropriate system prompts and guardrails. This work demonstrates that domain-specialized reasoning models can achieve strong performance on specialized tasks while maintaining broad general capabilities. We release the model publicly at https://huggingface.co/fdtn-ai/Foundation-Sec-8B-Reasoning.
Think Before You Retrieve: Learning Test-Time Adaptive Search with Small Language Models
Nov 10, 2025Effective information retrieval requires reasoning over partial evidence and refining strategies as information emerges. Yet current approaches fall short: neural retrievers lack reasoning capabilities, large language models (LLMs) provide semantic depth but at prohibitive cost, and query rewriting or decomposition limits improvement to static transformations. As a result, existing methods fail to capture the iterative dynamics of exploration, feedback, and revision that complex user queries demand. We introduce Orion, a training framework that enables compact models (350M-1.2B parameters) to perform iterative retrieval through learned search strategies. Orion combines: (1) synthetic trajectory generation and supervised fine-tuning to encourage diverse exploration patterns in models, (2) reinforcement learning (RL) that rewards effective query refinement and backtracking behaviors, and (3) inference-time beam search algorithms that exploit the self-reflection capabilities learned during RL. Despite using only 3% of the training data available, our 1.2B model achieves 77.6% success on SciFact (vs. 72.6% for prior retrievers), 25.2% on BRIGHT (vs. 22.1%), 63.2% on NFCorpus (vs. 57.8%), and remains competitive on FEVER, HotpotQA, and MSMarco. It outperforms retrievers up to 200-400x larger on five of six benchmarks. These findings suggest that retrieval performance can emerge from learned strategies, not just model scale, when models are trained to search, reflect, and revise.
Llama-3.1-FoundationAI-SecurityLLM-Base-8B Technical Report
Apr 28, 2025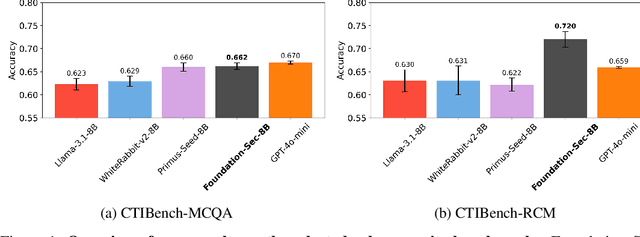
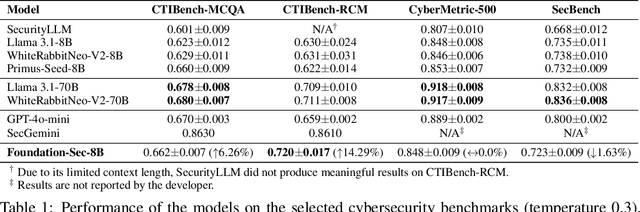
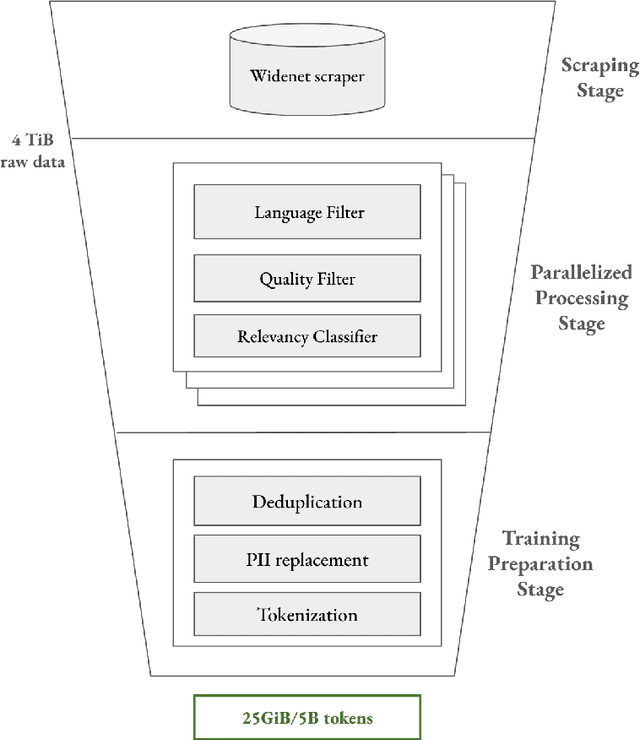

As transformer-based large language models (LLMs) increasingly permeate society, they have revolutionized domains such as software engineering, creative writing, and digital arts. However, their adoption in cybersecurity remains limited due to challenges like scarcity of specialized training data and complexity of representing cybersecurity-specific knowledge. To address these gaps, we present Foundation-Sec-8B, a cybersecurity-focused LLM built on the Llama 3.1 architecture and enhanced through continued pretraining on a carefully curated cybersecurity corpus. We evaluate Foundation-Sec-8B across both established and new cybersecurity benchmarks, showing that it matches Llama 3.1-70B and GPT-4o-mini in certain cybersecurity-specific tasks. By releasing our model to the public, we aim to accelerate progress and adoption of AI-driven tools in both public and private cybersecurity contexts.
When Neutral Summaries are not that Neutral: Quantifying Political Neutrality in LLM-Generated News Summaries
Oct 13, 2024



In an era where societal narratives are increasingly shaped by algorithmic curation, investigating the political neutrality of LLMs is an important research question. This study presents a fresh perspective on quantifying the political neutrality of LLMs through the lens of abstractive text summarization of polarizing news articles. We consider five pressing issues in current US politics: abortion, gun control/rights, healthcare, immigration, and LGBTQ+ rights. Via a substantial corpus of 20,344 news articles, our study reveals a consistent trend towards pro-Democratic biases in several well-known LLMs, with gun control and healthcare exhibiting the most pronounced biases (max polarization differences of -9.49% and -6.14%, respectively). Further analysis uncovers a strong convergence in the vocabulary of the LLM outputs for these divisive topics (55% overlap for Democrat-leaning representations, 52% for Republican). Being months away from a US election of consequence, we consider our findings important.
FRACTURED-SORRY-Bench: Framework for Revealing Attacks in Conversational Turns Undermining Refusal Efficacy and Defenses over SORRY-Bench
Aug 28, 2024

This paper introduces FRACTURED-SORRY-Bench, a framework for evaluating the safety of Large Language Models (LLMs) against multi-turn conversational attacks. Building upon the SORRY-Bench dataset, we propose a simple yet effective method for generating adversarial prompts by breaking down harmful queries into seemingly innocuous sub-questions. Our approach achieves a maximum increase of +46.22\% in Attack Success Rates (ASRs) across GPT-4, GPT-4o, GPT-4o-mini, and GPT-3.5-Turbo models compared to baseline methods. We demonstrate that this technique poses a challenge to current LLM safety measures and highlights the need for more robust defenses against subtle, multi-turn attacks.
Unified Locational Differential Privacy Framework
May 06, 2024



Aggregating statistics over geographical regions is important for many applications, such as analyzing income, election results, and disease spread. However, the sensitive nature of this data necessitates strong privacy protections to safeguard individuals. In this work, we present a unified locational differential privacy (DP) framework to enable private aggregation of various data types, including one-hot encoded, boolean, float, and integer arrays, over geographical regions. Our framework employs local DP mechanisms such as randomized response, the exponential mechanism, and the Gaussian mechanism. We evaluate our approach on four datasets representing significant location data aggregation scenarios. Results demonstrate the utility of our framework in providing formal DP guarantees while enabling geographical data analysis.
Are Chatbots Ready for Privacy-Sensitive Applications? An Investigation into Input Regurgitation and Prompt-Induced Sanitization
May 24, 2023



LLM-powered chatbots are becoming widely adopted in applications such as healthcare, personal assistants, industry hiring decisions, etc. In many of these cases, chatbots are fed sensitive, personal information in their prompts, as samples for in-context learning, retrieved records from a database, or as part of the conversation. The information provided in the prompt could directly appear in the output, which might have privacy ramifications if there is sensitive information there. As such, in this paper, we aim to understand the input copying and regurgitation capabilities of these models during inference and how they can be directly instructed to limit this copying by complying with regulations such as HIPAA and GDPR, based on their internal knowledge of them. More specifically, we find that when ChatGPT is prompted to summarize cover letters of a 100 candidates, it would retain personally identifiable information (PII) verbatim in 57.4% of cases, and we find this retention to be non-uniform between different subgroups of people, based on attributes such as gender identity. We then probe ChatGPT's perception of privacy-related policies and privatization mechanisms by directly instructing it to provide compliant outputs and observe a significant omission of PII from output.
#maskUp: Selective Attribute Encryption for Sensitive Vocalization for English language on Social Media Platforms
Nov 16, 2022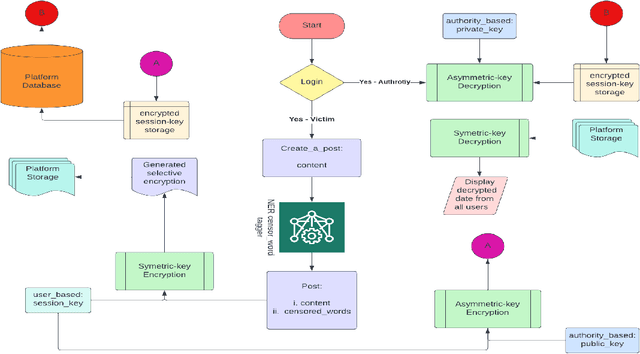



Social media has become a platform for people to stand up and raise their voices against social and criminal acts. Vocalization of such information has allowed the investigation and identification of criminals. However, revealing such sensitive information may jeopardize the victim's safety. We propose #maskUp, a safe method for information communication in a secure fashion to the relevant authorities, discouraging potential bullying of the victim. This would ensure security by conserving their privacy through natural language processing supplemented with selective encryption for sensitive attribute masking. To our knowledge, this is the first work that aims to protect the privacy of the victims by masking their private details as well as emboldening them to come forward to report crimes. The use of masking technology allows only binding authorities to view/un-mask this data. We construct and evaluate the proposed methodology on continual learning tasks, allowing practical implementation of the same in a real-world scenario. #maskUp successfully demonstrates this integration on sample datasets validating the presented objective.
AdaptKeyBERT: An Attention-Based approach towards Few-Shot & Zero-Shot Domain Adaptation of KeyBERT
Nov 16, 2022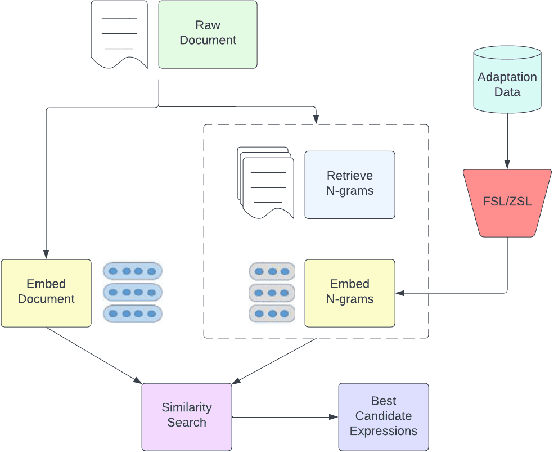
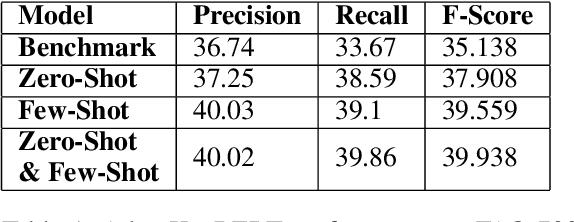
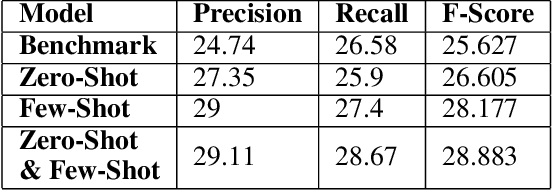
Keyword extraction has been an important topic for modern natural language processing. With its applications ranging from ontology generation, fact verification in summarized text, and recommendation systems. While it has had significant data-intensive applications, it is often hampered when the data set is small. Downstream training for keyword extractors is a lengthy process and requires a significant amount of data. Recently, Few-shot Learning (FSL) and Zero-Shot Learning (ZSL) have been proposed to tackle this problem. Therefore, we propose AdaptKeyBERT, a pipeline for training keyword extractors with LLM bases by incorporating the concept of regularized attention into a pre-training phase for downstream domain adaptation. As we believe our work has implications to be utilized in the pipeline of FSL/ZSL and keyword extraction, we open-source our code as well as provide the fine-tuning library of the same name AdaptKeyBERT at https://github.com/AmanPriyanshu/AdaptKeyBERT.
NERDA-Con: Extending NER models for Continual Learning -- Integrating Distinct Tasks and Updating Distribution Shifts
Jun 28, 2022

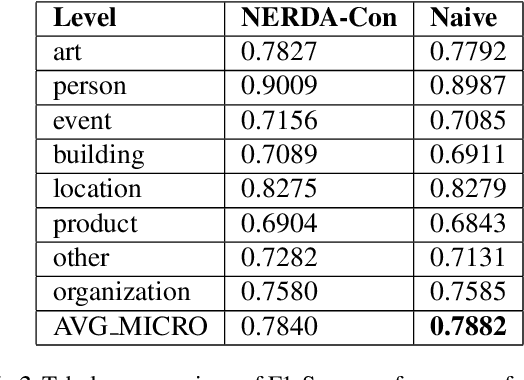

With increasing applications in areas such as biomedical information extraction pipelines and social media analytics, Named Entity Recognition (NER) has become an indispensable tool for knowledge extraction. However, with the gradual shift in language structure and vocabulary, NERs are plagued with distribution shifts, making them redundant or not as profitable without re-training. Re-training NERs based on Large Language Models (LLMs) from scratch over newly acquired data poses economic disadvantages. In contrast, re-training only with newly acquired data will result in Catastrophic Forgetting of previously acquired knowledge. Therefore, we propose NERDA-Con, a pipeline for training NERs with LLM bases by incorporating the concept of Elastic Weight Consolidation (EWC) into the NER fine-tuning NERDA pipeline. As we believe our work has implications to be utilized in the pipeline of continual learning and NER, we open-source our code as well as provide the fine-tuning library of the same name NERDA-Con at https://github.com/SupritiVijay/NERDA-Con and https://pypi.org/project/NERDA-Con/.