 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNERDA-Con: Extending NER models for Continual Learning -- Integrating Distinct Tasks and Updating Distribution Shifts
Paper and Code


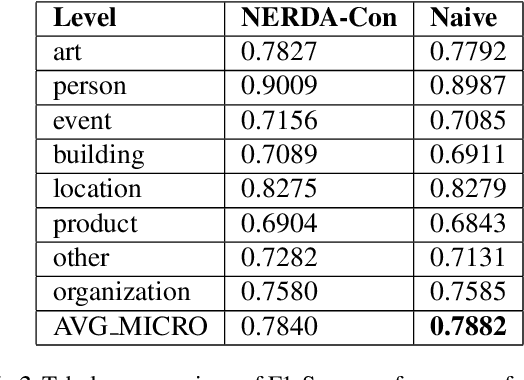

With increasing applications in areas such as biomedical information extraction pipelines and social media analytics, Named Entity Recognition (NER) has become an indispensable tool for knowledge extraction. However, with the gradual shift in language structure and vocabulary, NERs are plagued with distribution shifts, making them redundant or not as profitable without re-training. Re-training NERs based on Large Language Models (LLMs) from scratch over newly acquired data poses economic disadvantages. In contrast, re-training only with newly acquired data will result in Catastrophic Forgetting of previously acquired knowledge. Therefore, we propose NERDA-Con, a pipeline for training NERs with LLM bases by incorporating the concept of Elastic Weight Consolidation (EWC) into the NER fine-tuning NERDA pipeline. As we believe our work has implications to be utilized in the pipeline of continual learning and NER, we open-source our code as well as provide the fine-tuning library of the same name NERDA-Con at https://github.com/SupritiVijay/NERDA-Con and https://pypi.org/project/NERDA-Con/.