 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsights Generator: Systematic Corpus-Level Trace Diagnostics for LLM Agents
May 21, 2026Diagnosing failures in LLM agents remains largely manual. Practitioners inspect a small subset of execution traces, form ad-hoc hypotheses, and iterate. This process misses patterns that only emerge across trace populations and does not scale to production corpora where individual traces span tens of thousands of tokens. We formalize the problem of corpus-level trace diagnostics. Given a corpus of execution traces, the goal is to produce grounded natural-language insights that characterize systematic behavioral patterns across trace groups, each linked to supporting evidence. We present the Insights Generator (IG), a multi-agent system that answers diagnostic questions by proposing and testing hypotheses across the trace corpus to produce an evidence-backed insights report. We evaluate IG across qualitative and objective dimensions, spanning rubric-based report assessment and downstream performance improvements achieved by implementing IG insights. Human experts using IG reports improve scaffold performance by 30.4pp over the unmodified baseline scaffold, and coding agents leveraging IG-derived insights show consistent and stable gains. Across benchmarks, IG's scout-investigator architecture produces findings comparable in detection coverage to competing approaches, while domain experts rated IG reports as leading depth and evidence quality.
ROK-FORTRESS: Measuring the Effect of Geopolitical Transcreation for National Security and Public Safety
May 13, 2026Safety evaluations for large language models (LLMs) increasingly target high-stakes National Security and Public Safety (NSPS) risks, yet multilingual safety is typically assessed through translation-only benchmarks that preserve the underlying scenario, and empirical evidence of how language and geopolitical context interact remains limited to a narrow set of language pairs. We introduce \emph{ROK-FORTRESS} https://huggingface.co/datasets/ScaleAI/ROK-FORTRESS_public, a bilingual, culturally adversarial NSPS benchmark that uses the English--Korean language pair and U.S.--ROK geopolitical axis as a case study, separating the effects of language and geopolitical grounding via a \emph{transcreation matrix}: adversarial intents are evaluated under controlled combinations of (i) English versus Korean language and (ii) U.S.\ versus Korean entities, institutions, and operational details. Each adversarial prompt is paired with a dual-use benign counterpart to quantify over-refusal. Model responses are then scored using calibrated LLM-as-a-judge panels, applying our expert-crafted, prompt-specific binary rubrics. Across a dual-track set of frontier and Korean-optimized models, we find a consistent suppression effect in Korean variants and substantial model-to-model variation in how geopolitical grounding interacts with language. In many models, Korean grounding mitigates the Korean language-driven suppression -- with no model showing significant amplification in the other direction -- indicating that, at least in the English--Korean case, safety behavior is shaped by language-as-risk signals and context interactions that translation-only evaluations miss. The transcreation matrix methodology is designed to generalize to other language--culture pairs.
LHAW: Controllable Underspecification for Long-Horizon Tasks
Feb 11, 2026Long-horizon workflow agents that operate effectively over extended periods are essential for truly autonomous systems. Their reliable execution critically depends on the ability to reason through ambiguous situations in which clarification seeking is necessary to ensure correct task execution. However, progress is limited by the lack of scalable, task-agnostic frameworks for systematically curating and measuring the impact of ambiguity across custom workflows. We address this gap by introducing LHAW (Long-Horizon Augmented Workflows), a modular, dataset-agnostic synthetic pipeline that transforms any well-specified task into controllable underspecified variants by systematically removing information across four dimensions - Goals, Constraints, Inputs, and Context - at configurable severity levels. Unlike approaches that rely on LLM predictions of ambiguity, LHAW validates variants through empirical agent trials, classifying them as outcome-critical, divergent, or benign based on observed terminal state divergence. We release 285 task variants from TheAgentCompany, SWE-Bench Pro and MCP-Atlas according to our taxonomy alongside formal analysis measuring how current agents detect, reason about, and resolve underspecification across ambiguous settings. LHAW provides the first systematic framework for cost-sensitive evaluation of agent clarification behavior in long-horizon settings, enabling development of reliable autonomous systems.
Position: LLM Unlearning Benchmarks are Weak Measures of Progress
Oct 03, 2024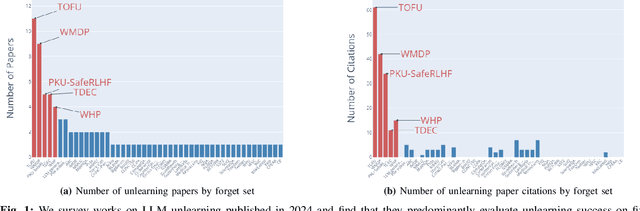
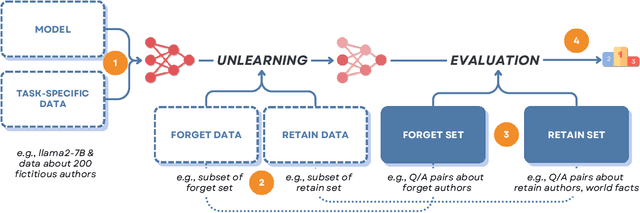
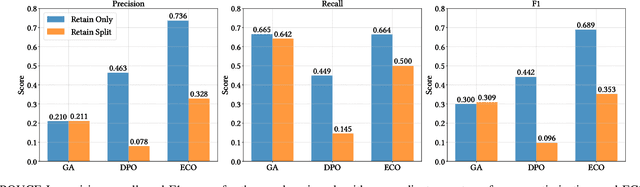
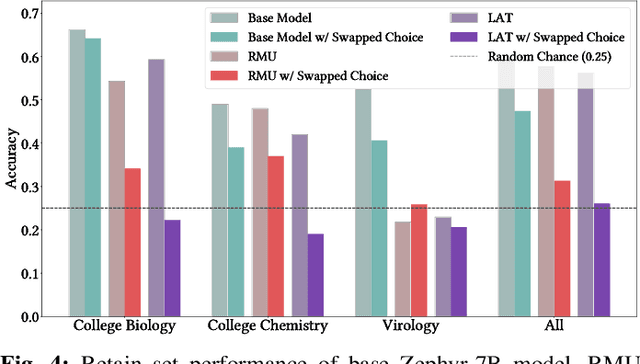
Unlearning methods have the potential to improve the privacy and safety of large language models (LLMs) by removing sensitive or harmful information post hoc. The LLM unlearning research community has increasingly turned toward empirical benchmarks to assess the effectiveness of such methods. In this paper, we find that existing benchmarks provide an overly optimistic and potentially misleading view on the effectiveness of candidate unlearning methods. By introducing simple, benign modifications to a number of popular benchmarks, we expose instances where supposedly unlearned information remains accessible, or where the unlearning process has degraded the model's performance on retained information to a much greater extent than indicated by the original benchmark. We identify that existing benchmarks are particularly vulnerable to modifications that introduce even loose dependencies between the forget and retain information. Further, we show that ambiguity in unlearning targets in existing benchmarks can easily lead to the design of methods that overfit to the given test queries. Based on our findings, we urge the community to be cautious when interpreting benchmark results as reliable measures of progress, and we provide several recommendations to guide future LLM unlearning research.
Unified Locational Differential Privacy Framework
May 06, 2024



Aggregating statistics over geographical regions is important for many applications, such as analyzing income, election results, and disease spread. However, the sensitive nature of this data necessitates strong privacy protections to safeguard individuals. In this work, we present a unified locational differential privacy (DP) framework to enable private aggregation of various data types, including one-hot encoded, boolean, float, and integer arrays, over geographical regions. Our framework employs local DP mechanisms such as randomized response, the exponential mechanism, and the Gaussian mechanism. We evaluate our approach on four datasets representing significant location data aggregation scenarios. Results demonstrate the utility of our framework in providing formal DP guarantees while enabling geographical data analysis.
Guardrail Baselines for Unlearning in LLMs
Mar 05, 2024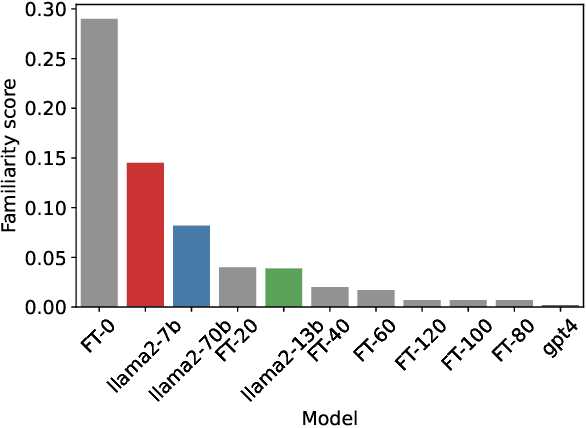
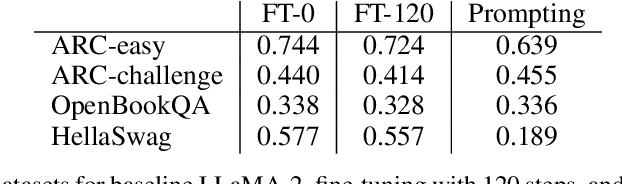
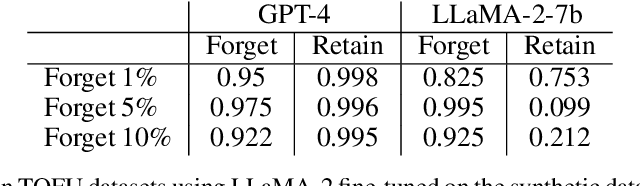
Recent work has demonstrated that fine-tuning is a promising approach to `unlearn' concepts from large language models. However, fine-tuning can be expensive, as it requires both generating a set of examples and running iterations of fine-tuning to update the model. In this work, we show that simple guardrail-based approaches such as prompting and filtering can achieve unlearning results comparable to fine-tuning. We recommend that researchers investigate these lightweight baselines when evaluating the performance of more computationally intensive fine-tuning methods. While we do not claim that methods such as prompting or filtering are universal solutions to the problem of unlearning, our work suggests the need for evaluation metrics that can better separate the power of guardrails vs. fine-tuning, and highlights scenarios where guardrails themselves may be advantageous for unlearning, such as in generating examples for fine-tuning or unlearning when only API access is available.
IS-CAM: Integrated Score-CAM for axiomatic-based explanations
Oct 06, 2020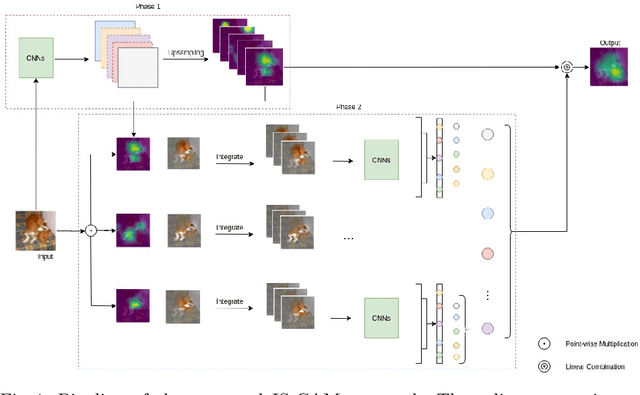
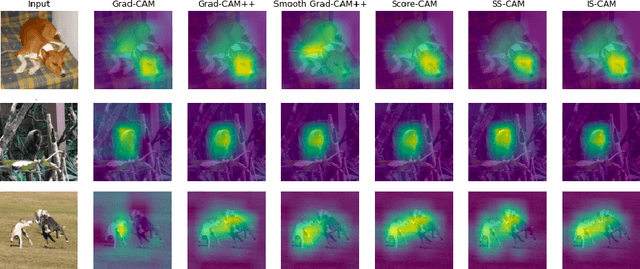
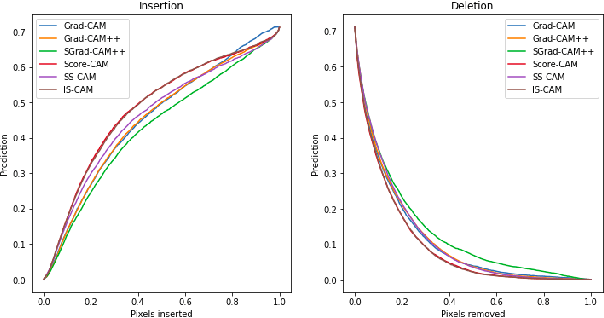
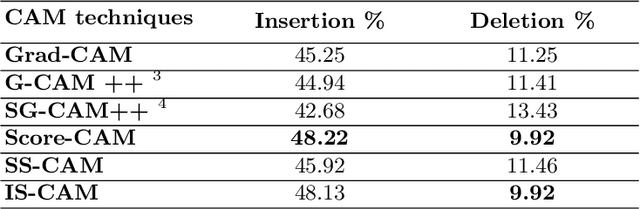
Convolutional Neural Networks have been known as black-box models as humans cannot interpret their inner functionalities. With an attempt to make CNNs more interpretable and trustworthy, we propose IS-CAM (Integrated Score-CAM), where we introduce the integration operation within the Score-CAM pipeline to achieve visually sharper attribution maps quantitatively. Our method is evaluated on 2000 randomly selected images from the ILSVRC 2012 Validation dataset, which proves the versatility of IS-CAM to account for different models and methods.