 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuardrail Baselines for Unlearning in LLMs
Paper and Code
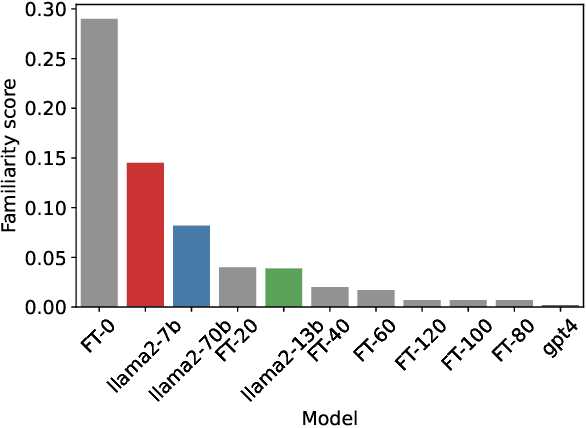
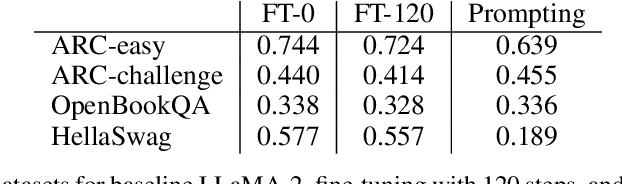
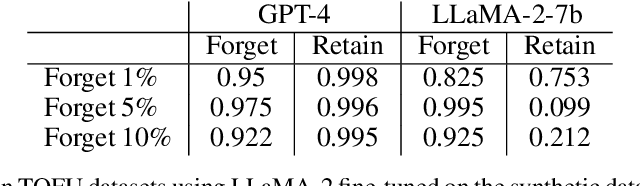
Recent work has demonstrated that fine-tuning is a promising approach to `unlearn' concepts from large language models. However, fine-tuning can be expensive, as it requires both generating a set of examples and running iterations of fine-tuning to update the model. In this work, we show that simple guardrail-based approaches such as prompting and filtering can achieve unlearning results comparable to fine-tuning. We recommend that researchers investigate these lightweight baselines when evaluating the performance of more computationally intensive fine-tuning methods. While we do not claim that methods such as prompting or filtering are universal solutions to the problem of unlearning, our work suggests the need for evaluation metrics that can better separate the power of guardrails vs. fine-tuning, and highlights scenarios where guardrails themselves may be advantageous for unlearning, such as in generating examples for fine-tuning or unlearning when only API access is available.