 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Risks in Weak-to-Strong Alignment: A Bias-Variance Perspective
Apr 28, 2026Weak-to-strong alignment offers a promising route to scalable supervision, but it can fail when a strong model becomes confidently wrong on examples that lie in the weak teacher's blind spots. Understanding such failures requires going beyond aggregate accuracy, since weak-to-strong errors depend not only on whether the strong model disagrees with its teacher, but also on how confidence and uncertainty are distributed across examples. In this work, we analyze weak-to-strong alignment through a bias-variance-covariance lens that connects misfit theory to practical post-training pipelines. We derive a misfit-based upper bound on weak-to-strong population risk and study its empirical components using continuous confidence scores. We evaluate four weak-to-strong pipelines spanning supervised fine-tuning (SFT), reinforcement learning from human feedback (RLHF), and reinforcement learning from AI feedback (RLAIF) on the PKU-SafeRLHF and HH-RLHF datasets. Using a blind-spot deception metric that isolates cases where the strong model is confidently wrong while the weak model is uncertain, we find that strong-model variance is the strongest empirical predictor of deception across our settings. Covariance provides additional but weaker information, indicating that weak-strong dependence matters, but does not by itself explain the observed failures. These results suggest that strong-model variance can serve as an early-warning signal for weak-to-strong deception, while blind-spot evaluation helps distinguish whether failures are inherited from weak supervision or arise in regions of weak-model uncertainty.
CREATE: Testing LLMs for Associative Creativity
Mar 10, 2026A key component of creativity is associative reasoning: the ability to draw novel yet meaningful connections between concepts. We introduce CREATE, a benchmark designed to evaluate models' capacity for creative associative reasoning. CREATE requires models to generate sets of paths connecting concepts in a model's parametric knowledge. Paths should have high specificity (distinctiveness and closeness of the concept connection) and high diversity (dissimilarity from other paths), and models are scored more highly if they produce a larger set of strong, diverse paths. This task shares demands of real creativity tasks like hypothesis generation, including an extremely large search space, but enables collection of a sizable benchmark with objective answer grading. Evaluation of frontier models shows that the strongest models achieve higher creative utility than others, with the high multiplicity of answers and complexity of the search making benchmark saturation difficult to achieve. Furthermore, our results illustrate that thinking models are not always more effective on our task, even with high token budgets. Recent approaches for creative prompting give some but limited additional improvement. CREATE provides a sandbox for developing new methods to improve models' capacity for associative creativity.
Interpreting and Mitigating Unwanted Uncertainty in LLMs
Oct 26, 2025Despite their impressive capabilities, Large Language Models (LLMs) exhibit unwanted uncertainty, a phenomenon where a model changes a previously correct answer into an incorrect one when re-prompted. This behavior undermines trust and poses serious risks in high-stakes domains. In this work, we investigate the mechanisms that drive this phenomenon. We adapt the Needle-in-a-Haystack retrieval framework and integrate a Flip-style re-evaluation prompt to simulate realistic answer-flipping scenarios. We find that retrieval heads are not primarily responsible for avoiding uncertainty. Instead, we identify a small set of non-retrieval attention heads that disproportionately attend to misleading tokens in uncertain contexts. Masking these heads yields significant improvements, reducing flip behavior by up to 15% without introducing incoherence or overcorrection. However, when tested for downstream tasks, we observe trade-offs with flip behavior. Our findings contribute to the growing field of mechanistic interpretability and present a simple yet effective technique for mitigating uncertainty-driven failure modes in LLMs.
Can LLMs $\textit{understand}$ Math? -- Exploring the Pitfalls in Mathematical Reasoning
May 21, 2025Large language models (LLMs) demonstrate considerable potential in various natural language tasks but face significant challenges in mathematical reasoning, particularly in executing precise, multi-step logic. However, current evaluation frameworks judge their performance solely based on accuracy, which only accounts for the final answer. This study explores these pitfalls by employing a novel evaluation framework. We propose an evaluation metric called the MAPLE score, which holistically quantifies reasoning misalignment by integrating error rates, redundancy, and validity.
RankAug: Augmented data ranking for text classification
Nov 08, 2023Research on data generation and augmentation has been focused majorly on enhancing generation models, leaving a notable gap in the exploration and refinement of methods for evaluating synthetic data. There are several text similarity metrics within the context of generated data filtering which can impact the performance of specific Natural Language Understanding (NLU) tasks, specifically focusing on intent and sentiment classification. In this study, we propose RankAug, a text-ranking approach that detects and filters out the top augmented texts in terms of being most similar in meaning with lexical and syntactical diversity. Through experiments conducted on multiple datasets, we demonstrate that the judicious selection of filtering techniques can yield a substantial improvement of up to 35% in classification accuracy for under-represented classes.
Interpretability of Fine-grained Classification of Sadness and Depression
Mar 20, 2022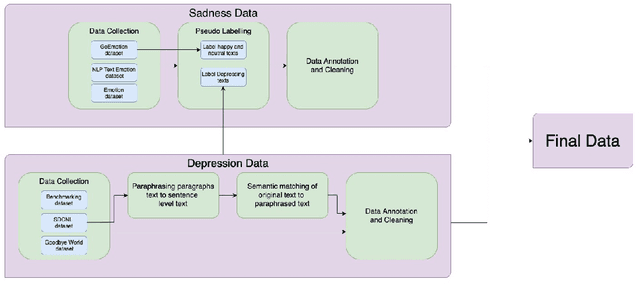


While sadness is a human emotion that people experience at certain times throughout their lives, inflicting them with emotional disappointment and pain, depression is a longer term mental illness which impairs social, occupational, and other vital regions of functioning making it a much more serious issue and needs to be catered to at the earliest. NLP techniques can be utilized for the detection and subsequent diagnosis of these emotions. Most of the open sourced data on the web deal with sadness as a part of depression, as an emotion even though the difference in severity of both is huge. Thus, we create our own novel dataset illustrating the difference between the two. In this paper, we aim to highlight the difference between the two and highlight how interpretable our models are to distinctly label sadness and depression. Due to the sensitive nature of such information, privacy measures need to be taken for handling and training of such data. Hence, we also explore the effect of Federated Learning (FL) on contextualised language models.
Privacy enabled Financial Text Classification using Differential Privacy and Federated Learning
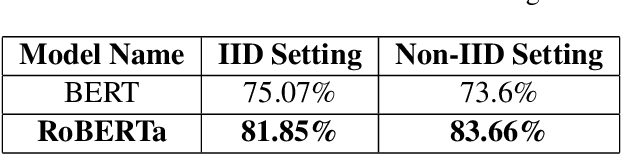
Oct 04, 2021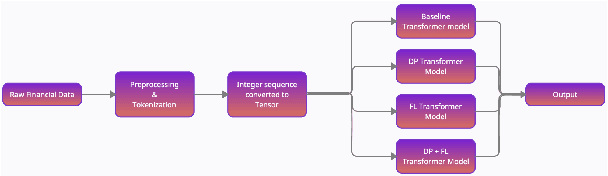
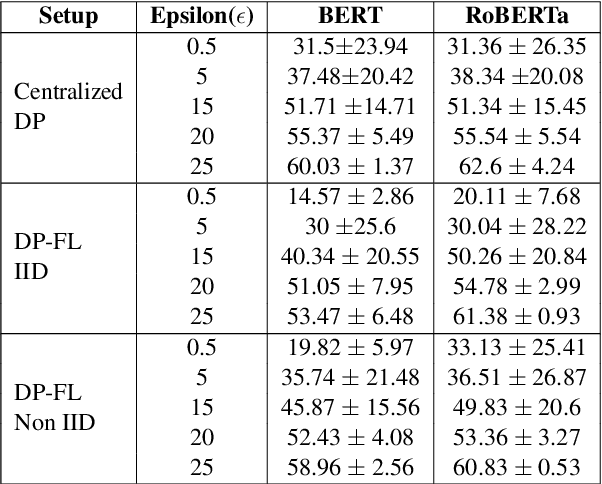
Privacy is important considering the financial Domain as such data is highly confidential and sensitive. Natural Language Processing (NLP) techniques can be applied for text classification and entity detection purposes in financial domains such as customer feedback sentiment analysis, invoice entity detection, categorisation of financial documents by type etc. Due to the sensitive nature of such data, privacy measures need to be taken for handling and training large models with such data. In this work, we propose a contextualized transformer (BERT and RoBERTa) based text classification model integrated with privacy features such as Differential Privacy (DP) and Federated Learning (FL). We present how to privately train NLP models and desirable privacy-utility tradeoffs and evaluate them on the Financial Phrase Bank dataset.
Benchmarking Differential Privacy and Federated Learning for BERT Models
Jun 26, 2021
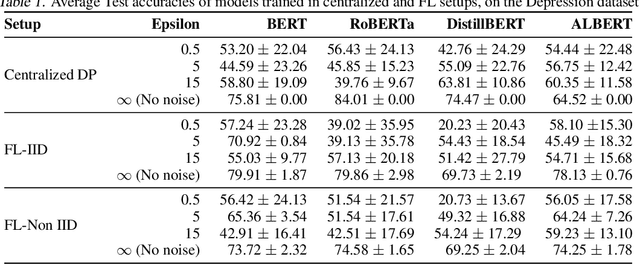
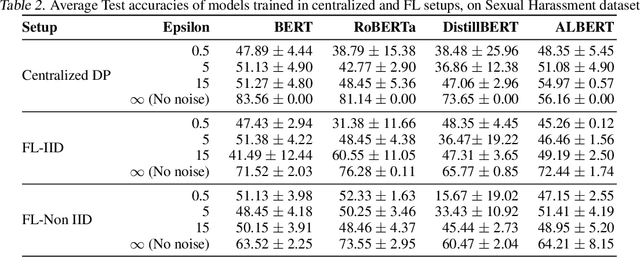
Natural Language Processing (NLP) techniques can be applied to help with the diagnosis of medical conditions such as depression, using a collection of a person's utterances. Depression is a serious medical illness that can have adverse effects on how one feels, thinks, and acts, which can lead to emotional and physical problems. Due to the sensitive nature of such data, privacy measures need to be taken for handling and training models with such data. In this work, we study the effects that the application of Differential Privacy (DP) has, in both a centralized and a Federated Learning (FL) setup, on training contextualized language models (BERT, ALBERT, RoBERTa and DistilBERT). We offer insights on how to privately train NLP models and what architectures and setups provide more desirable privacy utility trade-offs. We envisage this work to be used in future healthcare and mental health studies to keep medical history private. Therefore, we provide an open-source implementation of this work.