 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Differentially Private Synthetic Data Generation in High-Stakes Domains
Oct 10, 2024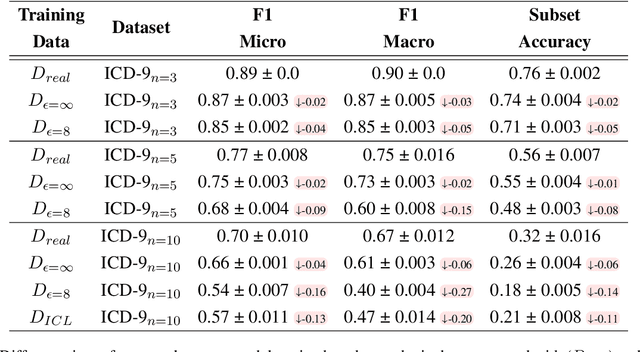


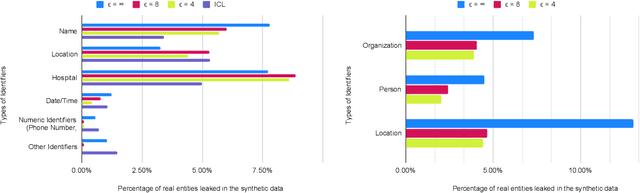
The difficulty of anonymizing text data hinders the development and deployment of NLP in high-stakes domains that involve private data, such as healthcare and social services. Poorly anonymized sensitive data cannot be easily shared with annotators or external researchers, nor can it be used to train public models. In this work, we explore the feasibility of using synthetic data generated from differentially private language models in place of real data to facilitate the development of NLP in these domains without compromising privacy. In contrast to prior work, we generate synthetic data for real high-stakes domains, and we propose and conduct use-inspired evaluations to assess data quality. Our results show that prior simplistic evaluations have failed to highlight utility, privacy, and fairness issues in the synthetic data. Overall, our work underscores the need for further improvements to synthetic data generation for it to be a viable way to enable privacy-preserving data sharing.
A Case for Rejection in Low Resource ML Deployment
Aug 15, 2022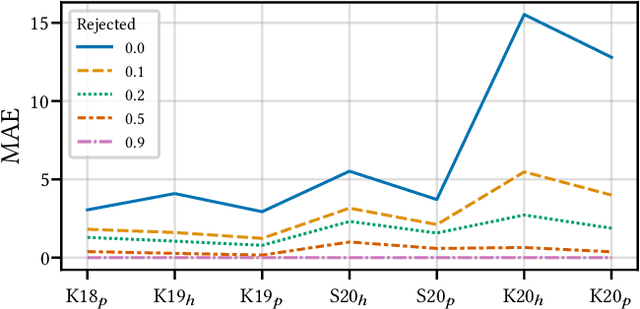
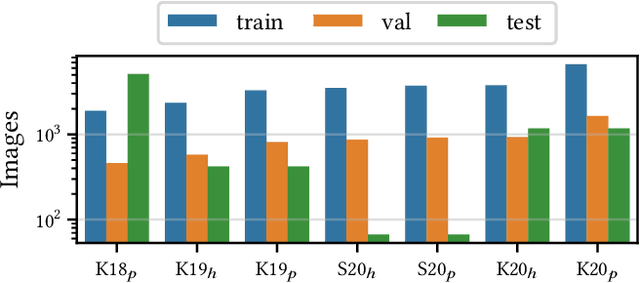
Building reliable AI decision support systems requires a robust set of data on which to train models; both with respect to quantity and diversity. Obtaining such datasets can be difficult in resource limited settings, or for applications in early stages of deployment. Sample rejection is one way to work around this challenge, however much of the existing work in this area is ill-suited for such scenarios. This paper substantiates that position and proposes a simple solution as a proof of concept baseline.