 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Spatiotemporal Inference with Biased Scan Attention Transformer Neural Processes
Jun 10, 2025Neural Processes (NPs) are a rapidly evolving class of models designed to directly model the posterior predictive distribution of stochastic processes. While early architectures were developed primarily as a scalable alternative to Gaussian Processes (GPs), modern NPs tackle far more complex and data hungry applications spanning geology, epidemiology, climate, and robotics. These applications have placed increasing pressure on the scalability of these models, with many architectures compromising accuracy for scalability. In this paper, we demonstrate that this tradeoff is often unnecessary, particularly when modeling fully or partially translation invariant processes. We propose a versatile new architecture, the Biased Scan Attention Transformer Neural Process (BSA-TNP), which introduces Kernel Regression Blocks (KRBlocks), group-invariant attention biases, and memory-efficient Biased Scan Attention (BSA). BSA-TNP is able to: (1) match or exceed the accuracy of the best models while often training in a fraction of the time, (2) exhibit translation invariance, enabling learning at multiple resolutions simultaneously, (3) transparently model processes that evolve in both space and time, (4) support high dimensional fixed effects, and (5) scale gracefully -- running inference with over 1M test points with 100K context points in under a minute on a single 24GB GPU.
Transformer Neural Processes -- Kernel Regression
Nov 19, 2024



Stochastic processes model various natural phenomena from disease transmission to stock prices, but simulating and quantifying their uncertainty can be computationally challenging. For example, modeling a Gaussian Process with standard statistical methods incurs an $\mathcal{O}(n^3)$ penalty, and even using state-of-the-art Neural Processes (NPs) incurs an $\mathcal{O}(n^2)$ penalty due to the attention mechanism. We introduce the Transformer Neural Process - Kernel Regression (TNP-KR), a new architecture that incorporates a novel transformer block we call a Kernel Regression Block (KRBlock), which reduces the computational complexity of attention in transformer-based Neural Processes (TNPs) from $\mathcal{O}((n_C+n_T)^2)$ to $O(n_C^2+n_Cn_T)$ by eliminating masked computations, where $n_C$ is the number of context, and $n_T$ is the number of test points, respectively, and a fast attention variant that further reduces all attention calculations to $\mathcal{O}(n_C)$ in space and time complexity. In benchmarks spanning such tasks as meta-regression, Bayesian optimization, and image completion, we demonstrate that the full variant matches the performance of state-of-the-art methods while training faster and scaling two orders of magnitude higher in number of test points, and the fast variant nearly matches that performance while scaling to millions of both test and context points on consumer hardware.
KidSat: satellite imagery to map childhood poverty dataset and benchmark
Jul 08, 2024


Satellite imagery has emerged as an important tool to analyse demographic, health, and development indicators. While various deep learning models have been built for these tasks, each is specific to a particular problem, with few standard benchmarks available. We propose a new dataset pairing satellite imagery and high-quality survey data on child poverty to benchmark satellite feature representations. Our dataset consists of 33,608 images, each 10 km $\times$ 10 km, from 19 countries in Eastern and Southern Africa in the time period 1997-2022. As defined by UNICEF, multidimensional child poverty covers six dimensions and it can be calculated from the face-to-face Demographic and Health Surveys (DHS) Program . As part of the benchmark, we test spatial as well as temporal generalization, by testing on unseen locations, and on data after the training years. Using our dataset we benchmark multiple models, from low-level satellite imagery models such as MOSAIKS , to deep learning foundation models, which include both generic vision models such as Self-Distillation with no Labels (DINOv2) models and specific satellite imagery models such as SatMAE. We provide open source code for building the satellite dataset, obtaining ground truth data from DHS and running various models assessed in our work.
BOLLWM: A real-world dataset for bollworm pest monitoring from cotton fields in India
Apr 03, 2023
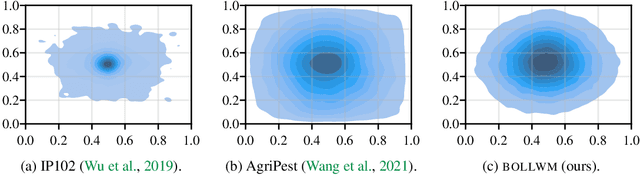


This paper presents a dataset of agricultural pest images captured over five years by thousands of small holder farmers and farming extension workers across India. The dataset has been used to support a mobile application that relies on artificial intelligence to assist farmers with pest management decisions. Creation came from a mix of organized data collection, and from mobile application usage that was less controlled. This makes the dataset unique within the pest detection community, exhibiting a number of characteristics that place it closer to other non-agricultural objected detection datasets. This not only makes the dataset applicable to future pest management applications, it opens the door for a wide variety of other research agendas.
A Case for Rejection in Low Resource ML Deployment
Aug 15, 2022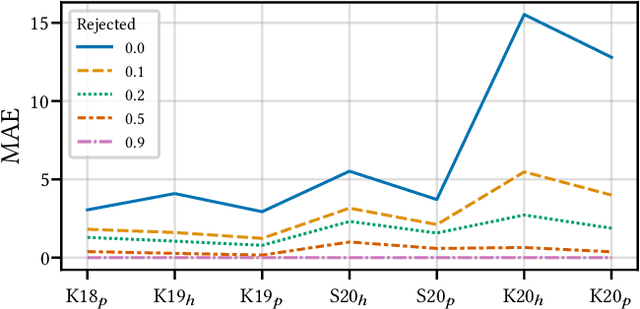
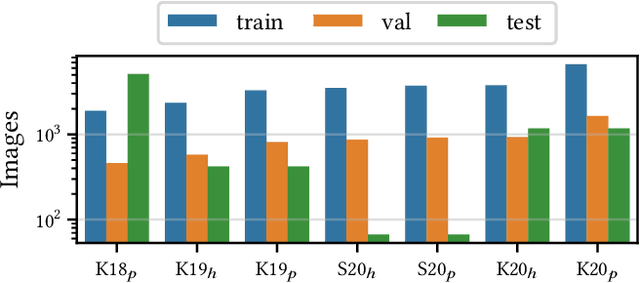
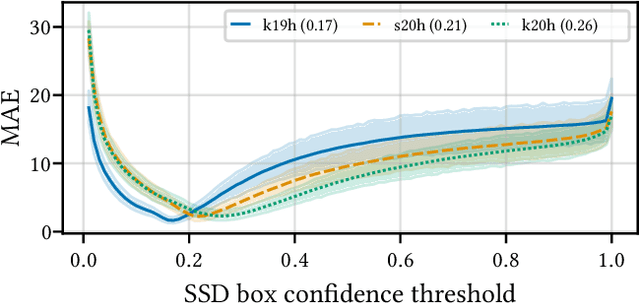
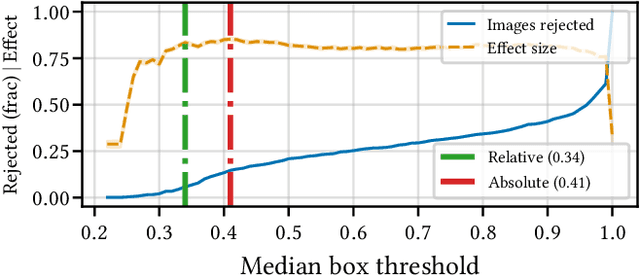
Building reliable AI decision support systems requires a robust set of data on which to train models; both with respect to quantity and diversity. Obtaining such datasets can be difficult in resource limited settings, or for applications in early stages of deployment. Sample rejection is one way to work around this challenge, however much of the existing work in this area is ill-suited for such scenarios. This paper substantiates that position and proposes a simple solution as a proof of concept baseline.
Impact of data-splits on generalization: Identifying COVID-19 from cough and context
Jun 05, 2021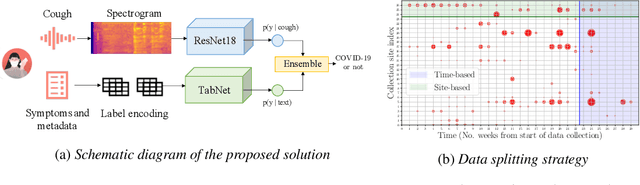

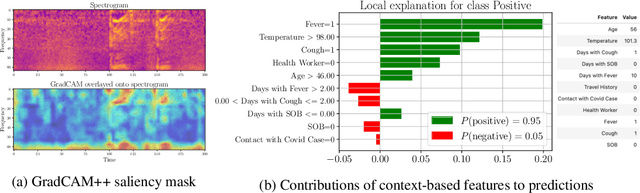
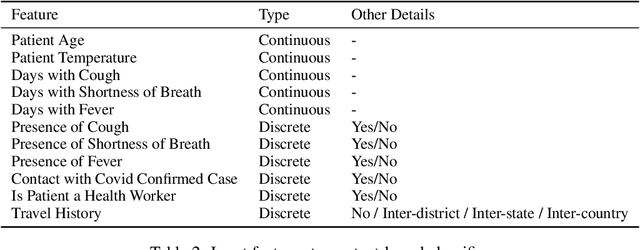
Rapidly scaling screening, testing and quarantine has shown to be an effective strategy to combat the COVID-19 pandemic. We consider the application of deep learning techniques to distinguish individuals with COVID from non-COVID by using data acquirable from a phone. Using cough and context (symptoms and meta-data) represent such a promising approach. Several independent works in this direction have shown promising results. However, none of them report performance across clinically relevant data splits. Specifically, the performance where the development and test sets are split in time (retrospective validation) and across sites (broad validation). Although there is meaningful generalization across these splits the performance significantly varies (up to 0.1 AUC score). In addition, we study the performance of symptomatic and asymptomatic individuals across these three splits. Finally, we show that our model focuses on meaningful features of the input, cough bouts for cough and relevant symptoms for context. The code and checkpoints are available at https://github.com/WadhwaniAI/cough-against-covid
Using Image Captions and Multitask Learning for Recommending Query Reformulations
Mar 02, 2020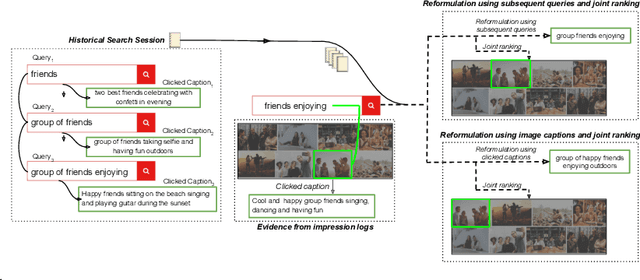
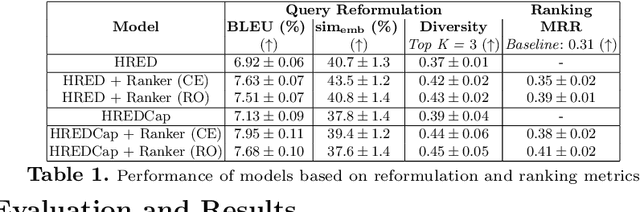
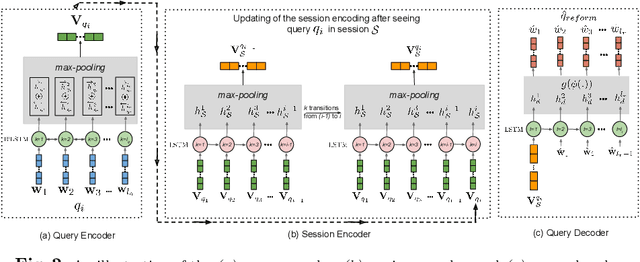
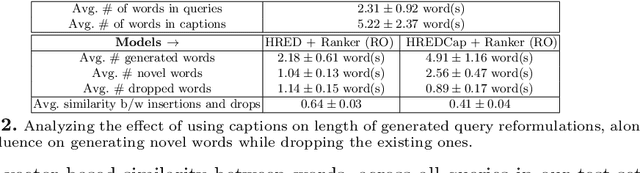
Interactive search sessions often contain multiple queries, where the user submits a reformulated version of the previous query in response to the original results. We aim to enhance the query recommendation experience for a commercial image search engine. Our proposed methodology incorporates current state-of-the-art practices from relevant literature -- the use of generation-based sequence-to-sequence models that capture session context, and a multitask architecture that simultaneously optimizes the ranking of results. We extend this setup by driving the learning of such a model with captions of clicked images as the target, instead of using the subsequent query within the session. Since these captions tend to be linguistically richer, the reformulation mechanism can be seen as assistance to construct more descriptive queries. In addition, via the use of a pairwise loss for the secondary ranking task, we show that the generated reformulations are more diverse.