 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Spatiotemporal Inference with Biased Scan Attention Transformer Neural Processes
Jun 10, 2025Neural Processes (NPs) are a rapidly evolving class of models designed to directly model the posterior predictive distribution of stochastic processes. While early architectures were developed primarily as a scalable alternative to Gaussian Processes (GPs), modern NPs tackle far more complex and data hungry applications spanning geology, epidemiology, climate, and robotics. These applications have placed increasing pressure on the scalability of these models, with many architectures compromising accuracy for scalability. In this paper, we demonstrate that this tradeoff is often unnecessary, particularly when modeling fully or partially translation invariant processes. We propose a versatile new architecture, the Biased Scan Attention Transformer Neural Process (BSA-TNP), which introduces Kernel Regression Blocks (KRBlocks), group-invariant attention biases, and memory-efficient Biased Scan Attention (BSA). BSA-TNP is able to: (1) match or exceed the accuracy of the best models while often training in a fraction of the time, (2) exhibit translation invariance, enabling learning at multiple resolutions simultaneously, (3) transparently model processes that evolve in both space and time, (4) support high dimensional fixed effects, and (5) scale gracefully -- running inference with over 1M test points with 100K context points in under a minute on a single 24GB GPU.
DeepRV: pre-trained spatial priors for accelerated disease mapping
Mar 27, 2025



Recently introduced prior-encoding deep generative models (e.g., PriorVAE, $\pi$VAE, and PriorCVAE) have emerged as powerful tools for scalable Bayesian inference by emulating complex stochastic processes like Gaussian processes (GPs). However, these methods remain largely a proof-of-concept and inaccessible to practitioners. We propose DeepRV, a lightweight, decoder-only approach that accelerates training, and enhances real-world applicability in comparison to current VAE-based prior encoding approaches. Leveraging probabilistic programming frameworks (e.g., NumPyro) for inference, DeepRV achieves significant speedups while also improving the quality of parameter inference, closely matching full MCMC sampling. We showcase its effectiveness in process emulation and spatial analysis of the UK using simulated data, gender-wise cancer mortality rates for individuals under 50, and HIV prevalence in Zimbabwe. To bridge the gap between theory and practice, we provide a user-friendly API, enabling scalable and efficient Bayesian inference.
Uncertainty-Aware Regression for Socio-Economic Estimation via Multi-View Remote Sensing
Nov 21, 2024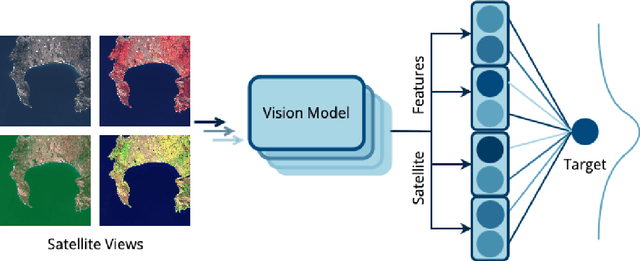


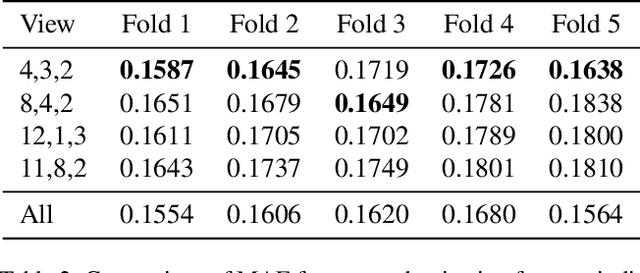
Remote sensing imagery offers rich spectral data across extensive areas for Earth observation. Many attempts have been made to leverage these data with transfer learning to develop scalable alternatives for estimating socio-economic conditions, reducing reliance on expensive survey-collected data. However, much of this research has primarily focused on daytime satellite imagery due to the limitation that most pre-trained models are trained on 3-band RGB images. Consequently, modeling techniques for spectral bands beyond the visible spectrum have not been thoroughly investigated. Additionally, quantifying uncertainty in remote sensing regression has been less explored, yet it is essential for more informed targeting and iterative collection of ground truth survey data. In this paper, we introduce a novel framework that leverages generic foundational vision models to process remote sensing imagery using combinations of three spectral bands to exploit multi-spectral data. We also employ methods such as heteroscedastic regression and Bayesian modeling to generate uncertainty estimates for the predictions. Experimental results demonstrate that our method outperforms existing models that use RGB or multi-spectral models with unstructured band usage. Moreover, our framework helps identify uncertain predictions, guiding future ground truth data acquisition.
Transformer Neural Processes -- Kernel Regression
Nov 19, 2024



Stochastic processes model various natural phenomena from disease transmission to stock prices, but simulating and quantifying their uncertainty can be computationally challenging. For example, modeling a Gaussian Process with standard statistical methods incurs an $\mathcal{O}(n^3)$ penalty, and even using state-of-the-art Neural Processes (NPs) incurs an $\mathcal{O}(n^2)$ penalty due to the attention mechanism. We introduce the Transformer Neural Process - Kernel Regression (TNP-KR), a new architecture that incorporates a novel transformer block we call a Kernel Regression Block (KRBlock), which reduces the computational complexity of attention in transformer-based Neural Processes (TNPs) from $\mathcal{O}((n_C+n_T)^2)$ to $O(n_C^2+n_Cn_T)$ by eliminating masked computations, where $n_C$ is the number of context, and $n_T$ is the number of test points, respectively, and a fast attention variant that further reduces all attention calculations to $\mathcal{O}(n_C)$ in space and time complexity. In benchmarks spanning such tasks as meta-regression, Bayesian optimization, and image completion, we demonstrate that the full variant matches the performance of state-of-the-art methods while training faster and scaling two orders of magnitude higher in number of test points, and the fast variant nearly matches that performance while scaling to millions of both test and context points on consumer hardware.