 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain specific ontologies from Linked Open Data (LOD)
May 28, 2025Logical and probabilistic reasoning tasks that require a deeper knowledge of semantics are increasingly relying on general purpose ontologies such as Wikidata and DBpedia. However, tasks such as entity disambiguation and linking may benefit from domain specific knowledge graphs, which make it more efficient to consume the knowledge and easier to extend with proprietary content. We discuss our experience bootstrapping one such ontology for IT with a domain-agnostic pipeline, and extending it using domain-specific glossaries.
Argument-Aware Approach To Event Linking
Mar 22, 2024Event linking connects event mentions in text with relevant nodes in a knowledge base (KB). Prior research in event linking has mainly borrowed methods from entity linking, overlooking the distinct features of events. Compared to the extensively explored entity linking task, events have more complex structures and can be more effectively distinguished by examining their associated arguments. Moreover, the information-rich nature of events leads to the scarcity of event KBs. This emphasizes the need for event linking models to identify and classify event mentions not in the KB as ``out-of-KB,'' an area that has received limited attention. In this work, we tackle these challenges by introducing an argument-aware approach. First, we improve event linking models by augmenting input text with tagged event argument information, facilitating the recognition of key information about event mentions. Subsequently, to help the model handle ``out-of-KB'' scenarios, we synthesize out-of-KB training examples from in-KB instances through controlled manipulation of event arguments. Our experiment across two test datasets showed significant enhancements in both in-KB and out-of-KB scenarios, with a notable 22% improvement in out-of-KB evaluations.
Using Image Captions and Multitask Learning for Recommending Query Reformulations
Mar 02, 2020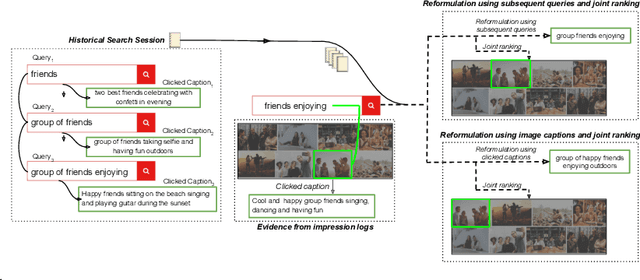
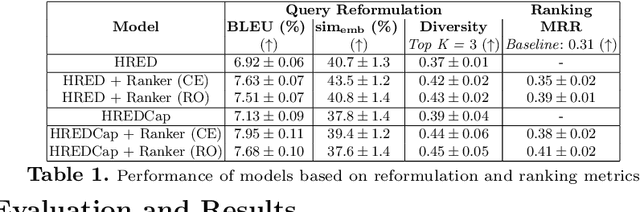
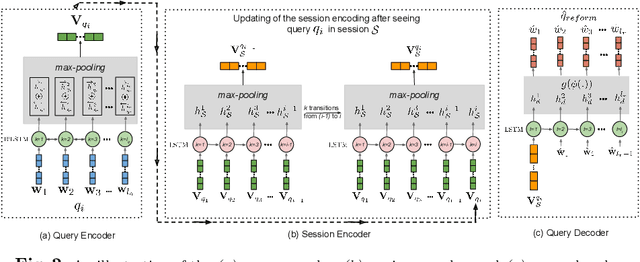
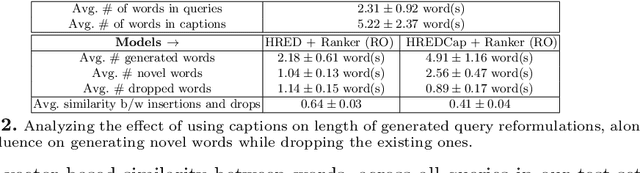
Interactive search sessions often contain multiple queries, where the user submits a reformulated version of the previous query in response to the original results. We aim to enhance the query recommendation experience for a commercial image search engine. Our proposed methodology incorporates current state-of-the-art practices from relevant literature -- the use of generation-based sequence-to-sequence models that capture session context, and a multitask architecture that simultaneously optimizes the ranking of results. We extend this setup by driving the learning of such a model with captions of clicked images as the target, instead of using the subsequent query within the session. Since these captions tend to be linguistically richer, the reformulation mechanism can be seen as assistance to construct more descriptive queries. In addition, via the use of a pairwise loss for the secondary ranking task, we show that the generated reformulations are more diverse.