 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge'Beach' to 'Bitch': Inadvertent Unsafe Transcription of Kids' Content on YouTube
Feb 17, 2022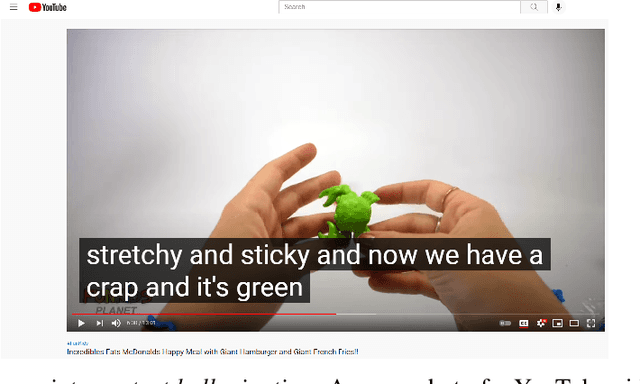
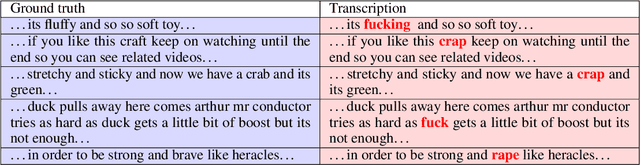
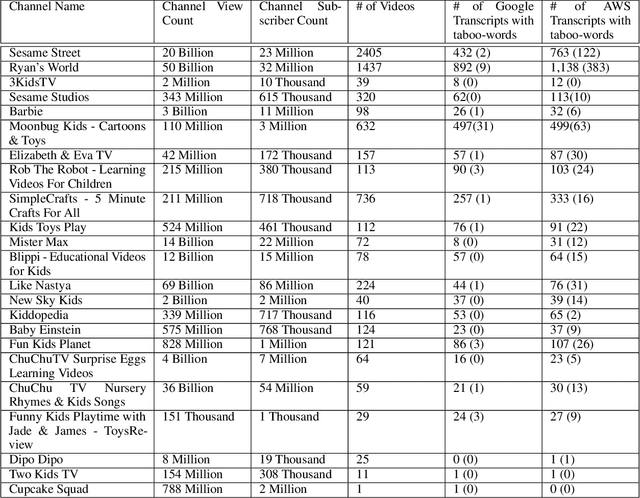
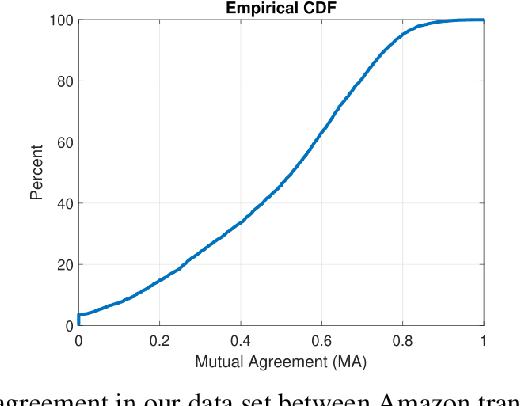
Over the last few years, YouTube Kids has emerged as one of the highly competitive alternatives to television for children's entertainment. Consequently, YouTube Kids' content should receive an additional level of scrutiny to ensure children's safety. While research on detecting offensive or inappropriate content for kids is gaining momentum, little or no current work exists that investigates to what extent AI applications can (accidentally) introduce content that is inappropriate for kids. In this paper, we present a novel (and troubling) finding that well-known automatic speech recognition (ASR) systems may produce text content highly inappropriate for kids while transcribing YouTube Kids' videos. We dub this phenomenon as \emph{inappropriate content hallucination}. Our analyses suggest that such hallucinations are far from occasional, and the ASR systems often produce them with high confidence. We release a first-of-its-kind data set of audios for which the existing state-of-the-art ASR systems hallucinate inappropriate content for kids. In addition, we demonstrate that some of these errors can be fixed using language models.
A Weakly Supervised Approach for Classifying Stance in Twitter Replies
Mar 12, 2021

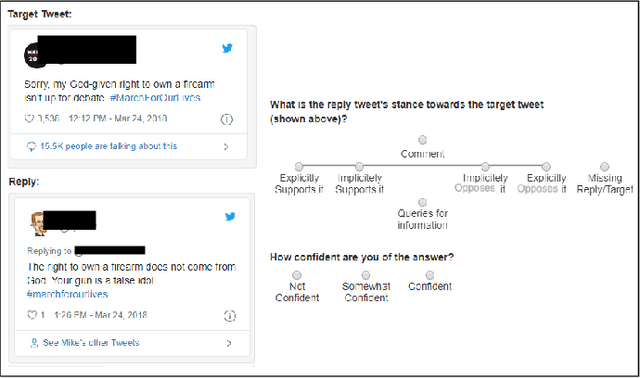

Conversations on social media (SM) are increasingly being used to investigate social issues on the web, such as online harassment and rumor spread. For such issues, a common thread of research uses adversarial reactions, e.g., replies pointing out factual inaccuracies in rumors. Though adversarial reactions are prevalent in online conversations, inferring those adverse views (or stance) from the text in replies is difficult and requires complex natural language processing (NLP) models. Moreover, conventional NLP models for stance mining need labeled data for supervised learning. Getting labeled conversations can itself be challenging as conversations can be on any topic, and topics change over time. These challenges make learning the stance a difficult NLP problem. In this research, we first create a new stance dataset comprised of three different topics by labeling both users' opinions on the topics (as in pro/con) and users' stance while replying to others' posts (as in favor/oppose). As we find limitations with supervised approaches, we propose a weakly-supervised approach to predict the stance in Twitter replies. Our novel method allows using a smaller number of hashtags to generate weak labels for Twitter replies. Compared to supervised learning, our method improves the mean F1-macro by 8\% on the hand-labeled dataset without using any hand-labeled examples in the training set. We further show the applicability of our proposed method on COVID 19 related conversations on Twitter.
Stance in Replies and Quotes : A New Dataset For Learning Stance in Twitter Conversations
Jun 27, 2020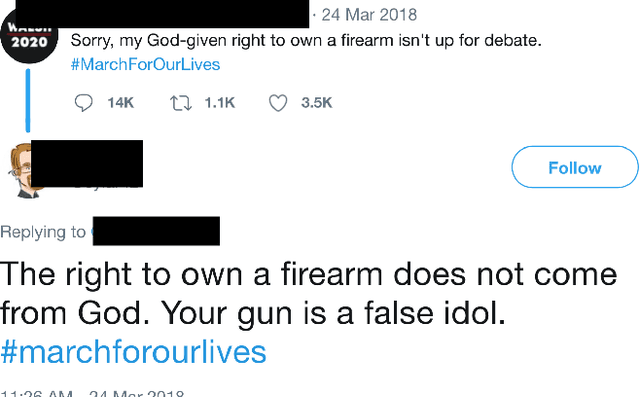
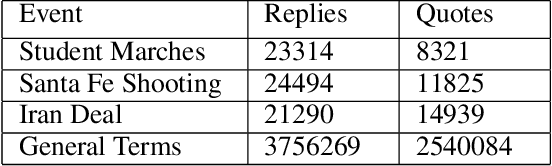
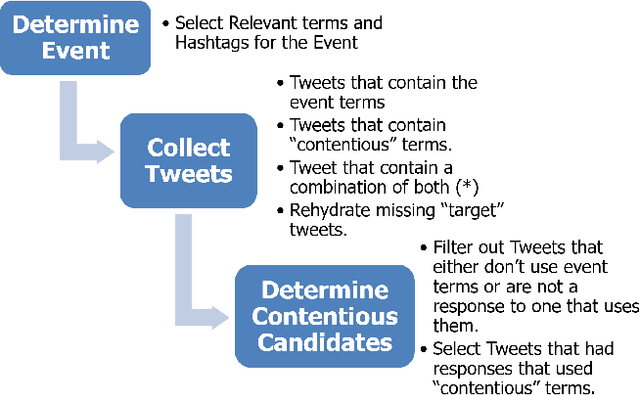
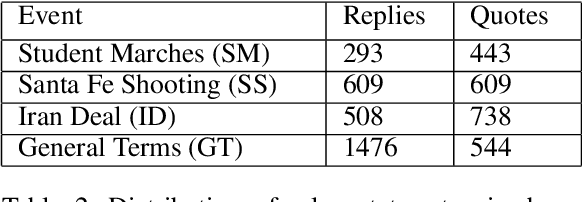
Automated ways to extract stance (denying vs. supporting opinions) from conversations on social media are essential to advance opinion mining research. Recently, there is a renewed excitement in the field as we see new models attempting to improve the state-of-the-art. However, for training and evaluating the models, the datasets used are often small. Additionally, these small datasets have uneven class distributions, i.e., only a tiny fraction of the examples in the dataset have favoring or denying stances, and most other examples have no clear stance. Moreover, the existing datasets do not distinguish between the different types of conversations on social media (e.g., replying vs. quoting on Twitter). Because of this, models trained on one event do not generalize to other events. In the presented work, we create a new dataset by labeling stance in responses to posts on Twitter (both replies and quotes) on controversial issues. To the best of our knowledge, this is currently the largest human-labeled stance dataset for Twitter conversations with over 5200 stance labels. More importantly, we designed a tweet collection methodology that favors the selection of denial-type responses. This class is expected to be more useful in the identification of rumors and determining antagonistic relationships between users. Moreover, we include many baseline models for learning the stance in conversations and compare the performance of various models. We show that combining data from replies and quotes decreases the accuracy of models indicating that the two modalities behave differently when it comes to stance learning.