 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Symmetric Alignment: Spectral Diagnostics of Modality Imbalance in Vision-Language Models in the Medical Domain
Jun 03, 2026Vision-Language Models (VLMs) struggle when applied to medical image-text data, yet the tools available to diagnose this failure remain limited. Existing representation alignment metrics are symmetric, collapsing both modalities into a single score and hiding which modality drives cross-modal degradation. We introduce the Spectral Alignment Score (SAS), an asymmetric metric that projects both modalities onto the principal eigenbasis of an anchor modality and computes eigenvalue-weighted per-eigenmode correlations, resulting in directional scores whose difference quantifies modality information imbalance. We embed SAS within a benchmarking framework evaluating 15 VLMs across natural and medical image-text datasets alongside 6 alignment metrics and bidirectional retrieval. Our experiments show that medical images retain richer structural information than their paired clinical reports, a directional asymmetry invisible to all competing metrics, and that SAS achieves the strongest zero-label correlation with retrieval performance in the medical domain, positioning it as a practical diagnostic tool for clinical deployment. Code is available at this URL: https://github.com/iamalegambetti/medical-vlms-assessment.
CRB-Based Waveform Optimization for MIMO ISAC Systems With One-Bit ADCs
Apr 08, 2026This paper studies the transmit waveform optimization for a quantized multiple-input multiple-output (MIMO) integrated sensing and communication (ISAC) system, where one-bit analog-to-digital converters (ADCs) are employed to enable a low-cost and power-efficient hardware implementation. Focusing on the parameter estimation task, we propose two novel Cramér-Rao bounds (CRBs) for both point-like target (PT) and extended target (ET) to characterize the impact of quantization distortion on the estimation accuracy, where associated estimation methods are also developed to approach these theoretical CRBs. Moreover, with the goal of jointly enhancing the sensing and communication performances, we formulate the bi-criterion ISAC waveform optimization problem by minimizing the derived CRB objectives subject to a communication symbol error probability (SEP) constraint and a total power constraint, which, due to the high nonlinearity of the one-bit CRBs, are extremely nonconvex. To yield a high-quality suboptimal solution, we develop an efficient alternating direction method of multipliers (ADMM) framework which exploits the majorization-minimization (MM) technique to address the nonconvex issue. Simulation results verify that the one-bit CRBs are tight for characterizing the quantized estimation performance and the proposed estimation methods also show clear performance advantages over the existing benchmark schemes. Furthermore, a flexible trade-off between the CRB and the SEP performance can be achieved by the developed ADMM framework, demonstrating the effectiveness of the optimized ISAC waveform.
Situated, Dynamic, and Subjective: Envisioning the Design of Theory-of-Mind-Enabled Everyday AI with Industry Practitioners
Feb 11, 2026Theory of Mind (ToM) -- the ability to infer what others are thinking (e.g., intentions) from observable cues -- is traditionally considered fundamental to human social interactions. This has sparked growing efforts in building and benchmarking AI's ToM capability, yet little is known about how such capability could translate into the design and experience of everyday user-facing AI products and services. We conducted 13 co-design sessions with 26 U.S.-based AI practitioners to envision, reflect, and distill design recommendations for ToM-enabled everyday AI products and services that are both future-looking and grounded in the realities of AI design and development practices. Analysis revealed three interrelated design recommendations: ToM-enabled AI should 1) be situated in the social context that shape users' mental states, 2) be responsive to the dynamic nature of mental states, and 3) be attuned to subjective individual differences. We surface design tensions within each recommendation that reveal a broader gap between practitioners' envisioned futures of ToM-enabled AI and the realities of current AI design and development practices. These findings point toward the need to move beyond static, inference-driven approach to ToM and toward designing ToM as a pervasive capability that supports continuous human-AI interaction loops.
* 16 pages, preprint for ACM CHI 2026 Conference
Large Language Models in Peer-Run Community Behavioral Health Services: Understanding Peer Specialists and Service Users' Perspectives on Opportunities, Risks, and Mitigation Strategies
Feb 09, 2026Peer-run organizations (PROs) provide critical, recovery-based behavioral health support rooted in lived experience. As large language models (LLMs) enter this domain, their scale, conversationality, and opacity introduce new challenges for situatedness, trust, and autonomy. Partnering with Collaborative Support Programs of New Jersey (CSPNJ), a statewide PRO in the Northeastern United States, we used comicboarding, a co-design method, to conduct workshops with 16 peer specialists and 10 service users exploring perceptions of integrating an LLM-based recommendation system into peer support. Findings show that depending on how LLMs are introduced, constrained, and co-used, they can reconfigure in-room dynamics by sustaining, undermining, or amplifying the relational authority that grounds peer support. We identify opportunities, risks, and mitigation strategies across three tensions: bridging scale and locality, protecting trust and relational dynamics, and preserving peer autonomy amid efficiency gains. We contribute design implications that center lived-experience-in-the-loop, reframe trust as co-constructed, and position LLMs not as clinical tools but as relational collaborators in high-stakes, community-led care.
MM-SCALE: Grounded Multimodal Moral Reasoning via Scalar Judgment and Listwise Alignment
Feb 03, 2026Vision-Language Models (VLMs) continue to struggle to make morally salient judgments in multimodal and socially ambiguous contexts. Prior works typically rely on binary or pairwise supervision, which often fail to capture the continuous and pluralistic nature of human moral reasoning. We present MM-SCALE (Multimodal Moral Scale), a large-scale dataset for aligning VLMs with human moral preferences through 5-point scalar ratings and explicit modality grounding. Each image-scenario pair is annotated with moral acceptability scores and grounded reasoning labels by humans using an interface we tailored for data collection, enabling listwise preference optimization over ranked scenario sets. By moving from discrete to scalar supervision, our framework provides richer alignment signals and finer calibration of multimodal moral reasoning. Experiments show that VLMs fine-tuned on MM-SCALE achieve higher ranking fidelity and more stable safety calibration than those trained with binary signals.
Unveiling Hidden Threats: Using Fractal Triggers to Boost Stealthiness of Distributed Backdoor Attacks in Federated Learning
Nov 12, 2025Traditional distributed backdoor attacks (DBA) in federated learning improve stealthiness by decomposing global triggers into sub-triggers, which however requires more poisoned data to maintian the attck strength and hence increases the exposure risk. To overcome this defect, This paper proposes a novel method, namely Fractal-Triggerred Distributed Backdoor Attack (FTDBA), which leverages the self-similarity of fractals to enhance the feature strength of sub-triggers and hence significantly reduce the required poisoning volume for the same attack strength. To address the detectability of fractal structures in the frequency and gradient domains, we introduce a dynamic angular perturbation mechanism that adaptively adjusts perturbation intensity across the training phases to balance efficiency and stealthiness. Experiments show that FTDBA achieves a 92.3\% attack success rate with only 62.4\% of the poisoning volume required by traditional DBA methods, while reducing the detection rate by 22.8\% and KL divergence by 41.2\%. This study presents a low-exposure, high-efficiency paradigm for federated backdoor attacks and expands the application of fractal features in adversarial sample generation.
Structuralist Approach to AI Literary Criticism: Leveraging Greimas Semiotic Square for Large Language Models
Jun 26, 2025Large Language Models (LLMs) excel in understanding and generating text but struggle with providing professional literary criticism for works with profound thoughts and complex narratives. This paper proposes GLASS (Greimas Literary Analysis via Semiotic Square), a structured analytical framework based on Greimas Semiotic Square (GSS), to enhance LLMs' ability to conduct in-depth literary analysis. GLASS facilitates the rapid dissection of narrative structures and deep meanings in narrative works. We propose the first dataset for GSS-based literary criticism, featuring detailed analyses of 48 works. Then we propose quantitative metrics for GSS-based literary criticism using the LLM-as-a-judge paradigm. Our framework's results, compared with expert criticism across multiple works and LLMs, show high performance. Finally, we applied GLASS to 39 classic works, producing original and high-quality analyses that address existing research gaps. This research provides an AI-based tool for literary research and education, offering insights into the cognitive mechanisms underlying literary engagement.
AI LEGO: Scaffolding Cross-Functional Collaboration in Industrial Responsible AI Practices during Early Design Stages
May 15, 2025Responsible AI (RAI) efforts increasingly emphasize the importance of addressing potential harms early in the AI development lifecycle through social-technical lenses. However, in cross-functional industry teams, this work is often stalled by a persistent knowledge handoff challenge: the difficulty of transferring high-level, early-stage technical design rationales from technical experts to non-technical or user-facing roles for ethical evaluation and harm identification. Through literature review and a co-design study with 8 practitioners, we unpack how this challenge manifests -- technical design choices are rarely handed off in ways that support meaningful engagement by non-technical roles; collaborative workflows lack shared, visual structures to support mutual understanding; and non-technical practitioners are left without scaffolds for systematic harm evaluation. Existing tools like JIRA or Google Docs, while useful for product tracking, are ill-suited for supporting joint harm identification across roles, often requiring significant extra effort to align understanding. To address this, we developed AI LEGO, a web-based prototype that supports cross-functional AI practitioners in effectively facilitating knowledge handoff and identifying harmful design choices in the early design stages. Technical roles use interactive blocks to draft development plans, while non-technical roles engage with those blocks through stage-specific checklists and LLM-driven persona simulations to surface potential harms. In a study with 18 cross-functional practitioners, AI LEGO increased the volume and likelihood of harms identified compared to baseline worksheets. Participants found that its modular structure and persona prompts made harm identification more accessible, fostering clearer and more collaborative RAI practices in early design.
POET: Supporting Prompting Creativity and Personalization with Automated Expansion of Text-to-Image Generation
Apr 18, 2025
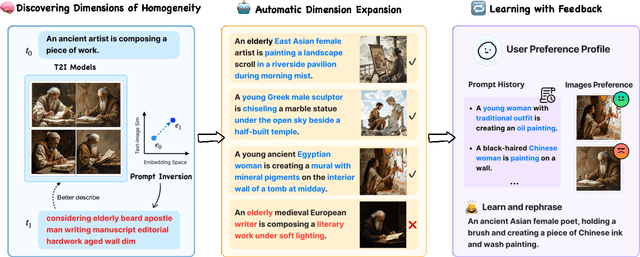


State-of-the-art visual generative AI tools hold immense potential to assist users in the early ideation stages of creative tasks -- offering the ability to generate (rather than search for) novel and unprecedented (instead of existing) images of considerable quality that also adhere to boundless combinations of user specifications. However, many large-scale text-to-image systems are designed for broad applicability, yielding conventional output that may limit creative exploration. They also employ interaction methods that may be difficult for beginners. Given that creative end users often operate in diverse, context-specific ways that are often unpredictable, more variation and personalization are necessary. We introduce POET, a real-time interactive tool that (1) automatically discovers dimensions of homogeneity in text-to-image generative models, (2) expands these dimensions to diversify the output space of generated images, and (3) learns from user feedback to personalize expansions. An evaluation with 28 users spanning four creative task domains demonstrated POET's ability to generate results with higher perceived diversity and help users reach satisfaction in fewer prompts during creative tasks, thereby prompting them to deliberate and reflect more on a wider range of possible produced results during the co-creative process. Focusing on visual creativity, POET offers a first glimpse of how interaction techniques of future text-to-image generation tools may support and align with more pluralistic values and the needs of end users during the ideation stages of their work.
Rethinking Theory of Mind Benchmarks for LLMs: Towards A User-Centered Perspective
Apr 15, 2025The last couple of years have witnessed emerging research that appropriates Theory-of-Mind (ToM) tasks designed for humans to benchmark LLM's ToM capabilities as an indication of LLM's social intelligence. However, this approach has a number of limitations. Drawing on existing psychology and AI literature, we summarize the theoretical, methodological, and evaluation limitations by pointing out that certain issues are inherently present in the original ToM tasks used to evaluate human's ToM, which continues to persist and exacerbated when appropriated to benchmark LLM's ToM. Taking a human-computer interaction (HCI) perspective, these limitations prompt us to rethink the definition and criteria of ToM in ToM benchmarks in a more dynamic, interactional approach that accounts for user preferences, needs, and experiences with LLMs in such evaluations. We conclude by outlining potential opportunities and challenges towards this direction.