 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe PokeAgent Challenge: Competitive and Long-Context Learning at Scale
Mar 17, 2026We present the PokeAgent Challenge, a large-scale benchmark for decision-making research built on Pokemon's multi-agent battle system and expansive role-playing game (RPG) environment. Partial observability, game-theoretic reasoning, and long-horizon planning remain open problems for frontier AI, yet few benchmarks stress all three simultaneously under realistic conditions. PokeAgent targets these limitations at scale through two complementary tracks: our Battling Track, which calls for strategic reasoning and generalization under partial observability in competitive Pokemon battles, and our Speedrunning Track, which requires long-horizon planning and sequential decision-making in the Pokemon RPG. Our Battling Track supplies a dataset of 20M+ battle trajectories alongside a suite of heuristic, RL, and LLM-based baselines capable of high-level competitive play. Our Speedrunning Track provides the first standardized evaluation framework for RPG speedrunning, including an open-source multi-agent orchestration system for modular, reproducible comparisons of harness-based LLM approaches. Our NeurIPS 2025 competition validates both the quality of our resources and the research community's interest in Pokemon, with over 100 teams competing across both tracks and winning solutions detailed in our paper. Participant submissions and our baselines reveal considerable gaps between generalist (LLM), specialist (RL), and elite human performance. Analysis against the BenchPress evaluation matrix shows that Pokemon battling is nearly orthogonal to standard LLM benchmarks, measuring capabilities not captured by existing suites and positioning Pokemon as an unsolved benchmark that can drive RL and LLM research forward. We transition to a living benchmark with a live leaderboard for Battling and self-contained evaluation for Speedrunning at https://pokeagentchallenge.com.
Concept-Based Interpretable Reinforcement Learning with Limited to No Human Labels
Jul 22, 2024



Recent advances in reinforcement learning (RL) have predominantly leveraged neural network-based policies for decision-making, yet these models often lack interpretability, posing challenges for stakeholder comprehension and trust. Concept bottleneck models offer an interpretable alternative by integrating human-understandable concepts into neural networks. However, a significant limitation in prior work is the assumption that human annotations for these concepts are readily available during training, necessitating continuous real-time input from human annotators. To overcome this limitation, we introduce a novel training scheme that enables RL algorithms to efficiently learn a concept-based policy by only querying humans to label a small set of data, or in the extreme case, without any human labels. Our algorithm, LICORICE, involves three main contributions: interleaving concept learning and RL training, using a concept ensembles to actively select informative data points for labeling, and decorrelating the concept data with a simple strategy. We show how LICORICE reduces manual labeling efforts to to 500 or fewer concept labels in three environments. Finally, we present an initial study to explore how we can use powerful vision-language models to infer concepts from raw visual inputs without explicit labels at minimal cost to performance.
Interpretability in Action: Exploratory Analysis of VPT, a Minecraft Agent
Jul 16, 2024



Understanding the mechanisms behind decisions taken by large foundation models in sequential decision making tasks is critical to ensuring that such systems operate transparently and safely. In this work, we perform exploratory analysis on the Video PreTraining (VPT) Minecraft playing agent, one of the largest open-source vision-based agents. We aim to illuminate its reasoning mechanisms by applying various interpretability techniques. First, we analyze the attention mechanism while the agent solves its training task - crafting a diamond pickaxe. The agent pays attention to the last four frames and several key-frames further back in its six-second memory. This is a possible mechanism for maintaining coherence in a task that takes 3-10 minutes, despite the short memory span. Secondly, we perform various interventions, which help us uncover a worrying case of goal misgeneralization: VPT mistakenly identifies a villager wearing brown clothes as a tree trunk when the villager is positioned stationary under green tree leaves, and punches it to death.
Unifying Interpretability and Explainability for Alzheimer's Disease Progression Prediction
Jun 11, 2024Reinforcement learning (RL) has recently shown promise in predicting Alzheimer's disease (AD) progression due to its unique ability to model domain knowledge. However, it is not clear which RL algorithms are well-suited for this task. Furthermore, these methods are not inherently explainable, limiting their applicability in real-world clinical scenarios. Our work addresses these two important questions. Using a causal, interpretable model of AD, we first compare the performance of four contemporary RL algorithms in predicting brain cognition over 10 years using only baseline (year 0) data. We then apply SHAP (SHapley Additive exPlanations) to explain the decisions made by each algorithm in the model. Our approach combines interpretability with explainability to provide insights into the key factors influencing AD progression, offering both global and individual, patient-level analysis. Our findings show that only one of the RL methods is able to satisfactorily model disease progression, but the post-hoc explanations indicate that all methods fail to properly capture the importance of amyloid accumulation, one of the pathological hallmarks of Alzheimer's disease. Our work aims to merge predictive accuracy with transparency, assisting clinicians and researchers in enhancing disease progression modeling for informed healthcare decisions. Code is available at https://github.com/rfali/xrlad.
PATIENT-Ψ: Using Large Language Models to Simulate Patients for Training Mental Health Professionals
May 30, 2024Mental illness remains one of the most critical public health issues, with a significant gap between the available mental health support and patient needs. Many mental health professionals highlight a disconnect between their training and real-world patient interactions, leaving some trainees feeling unprepared and potentially affecting their early career success. In this paper, we propose PATIENT-{\Psi}, a novel patient simulation framework for cognitive behavior therapy (CBT) training. To build PATIENT-{\Psi}, we constructed diverse patient profiles and their corresponding cognitive models based on CBT principles, and then used large language models (LLMs) programmed with the patient cognitive models to act as a simulated therapy patient. We propose an interactive training scheme, PATIENT-{\Psi}-TRAINER, for mental health trainees to practice a key skill in CBT -- formulating the cognitive model of the patient -- through role-playing a therapy session with PATIENT-{\Psi}. To evaluate PATIENT-{\Psi}, we conducted a user study of 4 mental health trainees and 10 experts. The results demonstrate that practice using PATIENT-{\Psi}-TRAINER greatly enhances the perceived skill acquisition and confidence of the trainees beyond existing forms of training such as textbooks, videos, and role-play with non-patients. Based on the experts' perceptions, PATIENT-{\Psi} is perceived to be closer to real patient interactions than GPT-4, and PATIENT-{\Psi}-TRAINER holds strong promise to improve trainee competencies. Our pioneering patient simulation training framework, using LLMs, holds great potential to enhance and advance mental health training, ultimately leading to improved patient care and outcomes. We will release all our data, code, and the training platform.
BEDD: The MineRL BASALT Evaluation and Demonstrations Dataset for Training and Benchmarking Agents that Solve Fuzzy Tasks
Dec 05, 2023



The MineRL BASALT competition has served to catalyze advances in learning from human feedback through four hard-to-specify tasks in Minecraft, such as create and photograph a waterfall. Given the completion of two years of BASALT competitions, we offer to the community a formalized benchmark through the BASALT Evaluation and Demonstrations Dataset (BEDD), which serves as a resource for algorithm development and performance assessment. BEDD consists of a collection of 26 million image-action pairs from nearly 14,000 videos of human players completing the BASALT tasks in Minecraft. It also includes over 3,000 dense pairwise human evaluations of human and algorithmic agents. These comparisons serve as a fixed, preliminary leaderboard for evaluating newly-developed algorithms. To enable this comparison, we present a streamlined codebase for benchmarking new algorithms against the leaderboard. In addition to presenting these datasets, we conduct a detailed analysis of the data from both datasets to guide algorithm development and evaluation. The released code and data are available at https://github.com/minerllabs/basalt-benchmark .
Bi-level Latent Variable Model for Sample-Efficient Multi-Agent Reinforcement Learning
Apr 12, 2023



Despite their potential in real-world applications, multi-agent reinforcement learning (MARL) algorithms often suffer from high sample complexity. To address this issue, we present a novel model-based MARL algorithm, BiLL (Bi-Level Latent Variable Model-based Learning), that learns a bi-level latent variable model from high-dimensional inputs. At the top level, the model learns latent representations of the global state, which encode global information relevant to behavior learning. At the bottom level, it learns latent representations for each agent, given the global latent representations from the top level. The model generates latent trajectories to use for policy learning. We evaluate our algorithm on complex multi-agent tasks in the challenging SMAC and Flatland environments. Our algorithm outperforms state-of-the-art model-free and model-based baselines in sample efficiency, including on two extremely challenging Super Hard SMAC maps.
Towards Solving Fuzzy Tasks with Human Feedback: A Retrospective of the MineRL BASALT 2022 Competition
Mar 23, 2023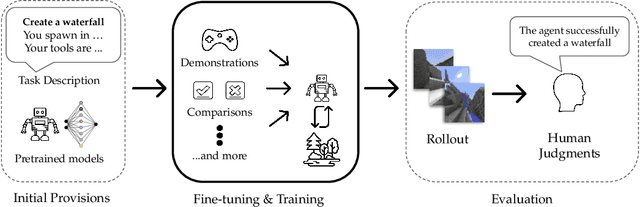

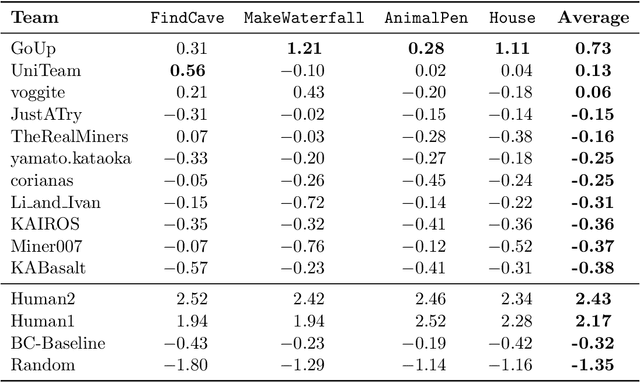
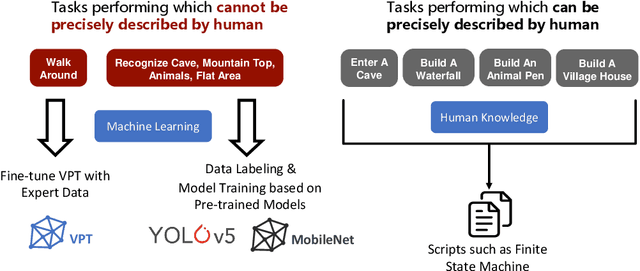
To facilitate research in the direction of fine-tuning foundation models from human feedback, we held the MineRL BASALT Competition on Fine-Tuning from Human Feedback at NeurIPS 2022. The BASALT challenge asks teams to compete to develop algorithms to solve tasks with hard-to-specify reward functions in Minecraft. Through this competition, we aimed to promote the development of algorithms that use human feedback as channels to learn the desired behavior. We describe the competition and provide an overview of the top solutions. We conclude by discussing the impact of the competition and future directions for improvement.
Navigates Like Me: Understanding How People Evaluate Human-Like AI in Video Games
Mar 02, 2023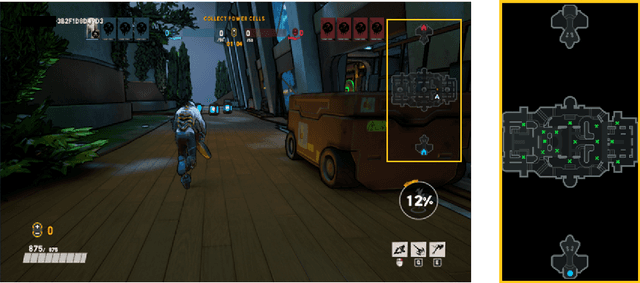
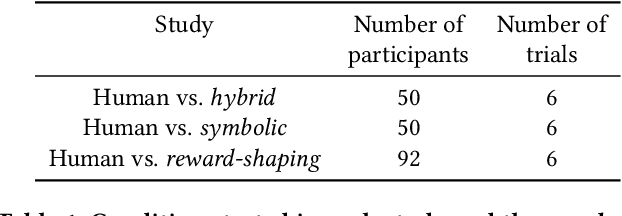
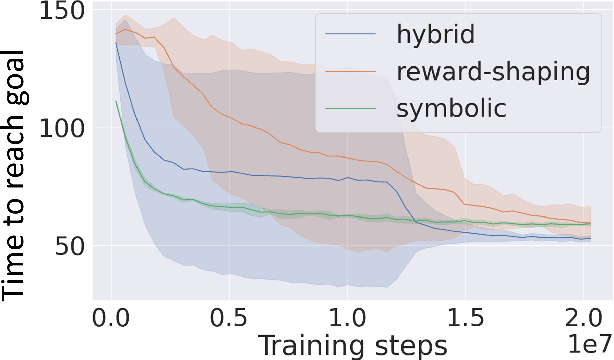

We aim to understand how people assess human likeness in navigation produced by people and artificially intelligent (AI) agents in a video game. To this end, we propose a novel AI agent with the goal of generating more human-like behavior. We collect hundreds of crowd-sourced assessments comparing the human-likeness of navigation behavior generated by our agent and baseline AI agents with human-generated behavior. Our proposed agent passes a Turing Test, while the baseline agents do not. By passing a Turing Test, we mean that human judges could not quantitatively distinguish between videos of a person and an AI agent navigating. To understand what people believe constitutes human-like navigation, we extensively analyze the justifications of these assessments. This work provides insights into the characteristics that people consider human-like in the context of goal-directed video game navigation, which is a key step for further improving human interactions with AI agents.
UniMASK: Unified Inference in Sequential Decision Problems
Nov 20, 2022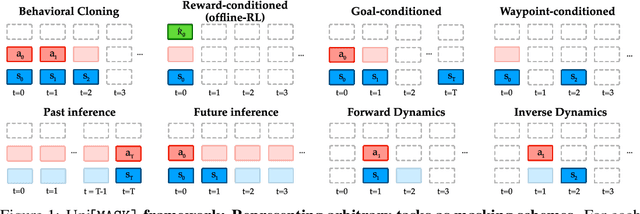
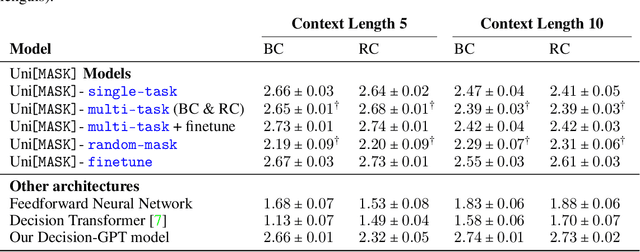
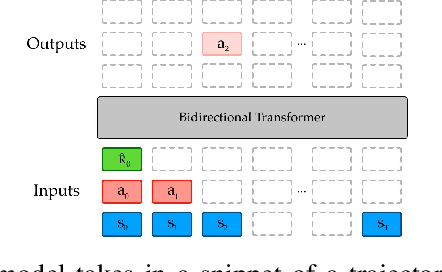
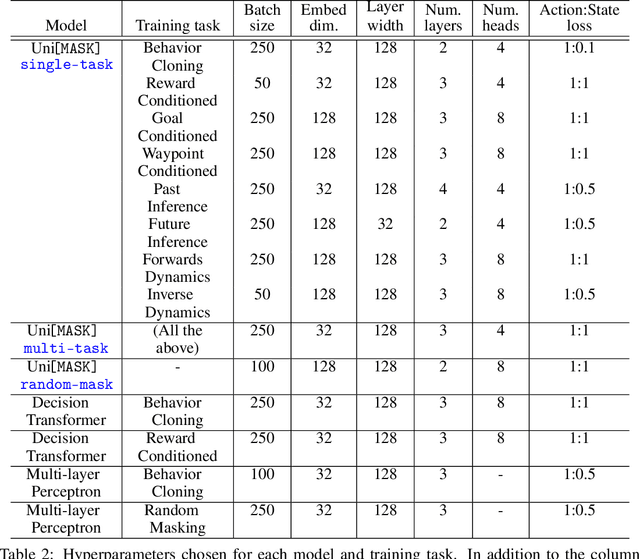
Randomly masking and predicting word tokens has been a successful approach in pre-training language models for a variety of downstream tasks. In this work, we observe that the same idea also applies naturally to sequential decision-making, where many well-studied tasks like behavior cloning, offline reinforcement learning, inverse dynamics, and waypoint conditioning correspond to different sequence maskings over a sequence of states, actions, and returns. We introduce the UniMASK framework, which provides a unified way to specify models which can be trained on many different sequential decision-making tasks. We show that a single UniMASK model is often capable of carrying out many tasks with performance similar to or better than single-task models. Additionally, after fine-tuning, our UniMASK models consistently outperform comparable single-task models. Our code is publicly available at https://github.com/micahcarroll/uniMASK.