 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy-Driven World Model Adaptation for Robust Offline Model-based Reinforcement Learning
May 19, 2025Offline reinforcement learning (RL) offers a powerful paradigm for data-driven control. Compared to model-free approaches, offline model-based RL (MBRL) explicitly learns a world model from a static dataset and uses it as a surrogate simulator, improving data efficiency and enabling potential generalization beyond the dataset support. However, most existing offline MBRL methods follow a two-stage training procedure: first learning a world model by maximizing the likelihood of the observed transitions, then optimizing a policy to maximize its expected return under the learned model. This objective mismatch results in a world model that is not necessarily optimized for effective policy learning. Moreover, we observe that policies learned via offline MBRL often lack robustness during deployment, and small adversarial noise in the environment can lead to significant performance degradation. To address these, we propose a framework that dynamically adapts the world model alongside the policy under a unified learning objective aimed at improving robustness. At the core of our method is a maximin optimization problem, which we solve by innovatively utilizing Stackelberg learning dynamics. We provide theoretical analysis to support our design and introduce computationally efficient implementations. We benchmark our algorithm on twelve noisy D4RL MuJoCo tasks and three stochastic Tokamak Control tasks, demonstrating its state-of-the-art performance.
Bi-level Latent Variable Model for Sample-Efficient Multi-Agent Reinforcement Learning
Apr 12, 2023



Despite their potential in real-world applications, multi-agent reinforcement learning (MARL) algorithms often suffer from high sample complexity. To address this issue, we present a novel model-based MARL algorithm, BiLL (Bi-Level Latent Variable Model-based Learning), that learns a bi-level latent variable model from high-dimensional inputs. At the top level, the model learns latent representations of the global state, which encode global information relevant to behavior learning. At the bottom level, it learns latent representations for each agent, given the global latent representations from the top level. The model generates latent trajectories to use for policy learning. We evaluate our algorithm on complex multi-agent tasks in the challenging SMAC and Flatland environments. Our algorithm outperforms state-of-the-art model-free and model-based baselines in sample efficiency, including on two extremely challenging Super Hard SMAC maps.
Evolutionary Approach to Security Games with Signaling
Apr 29, 2022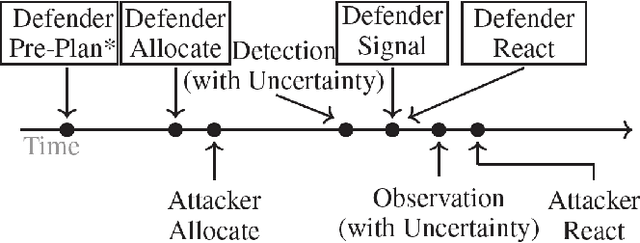
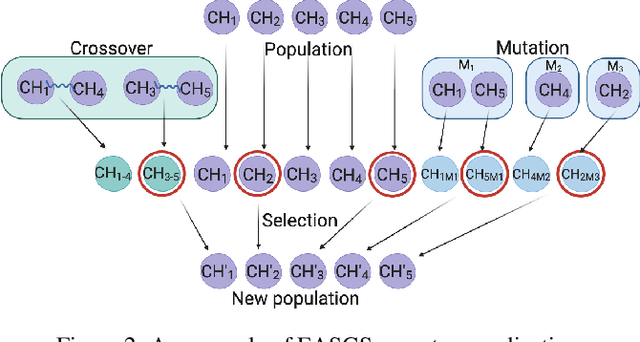
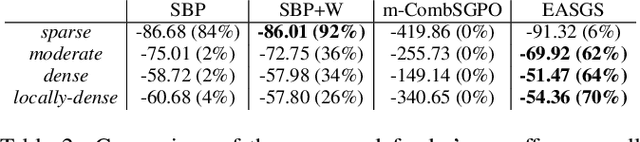
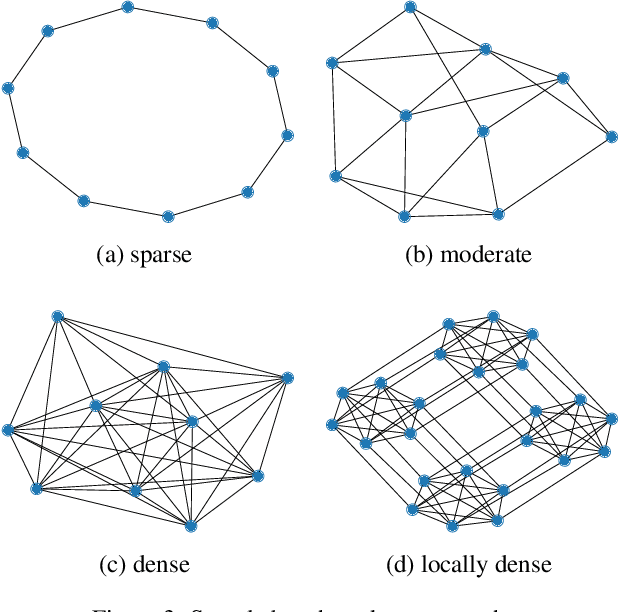
Green Security Games have become a popular way to model scenarios involving the protection of natural resources, such as wildlife. Sensors (e.g. drones equipped with cameras) have also begun to play a role in these scenarios by providing real-time information. Incorporating both human and sensor defender resources strategically is the subject of recent work on Security Games with Signaling (SGS). However, current methods to solve SGS do not scale well in terms of time or memory. We therefore propose a novel approach to SGS, which, for the first time in this domain, employs an Evolutionary Computation paradigm: EASGS. EASGS effectively searches the huge SGS solution space via suitable solution encoding in a chromosome and a specially-designed set of operators. The operators include three types of mutations, each focusing on a particular aspect of the SGS solution, optimized crossover and a local coverage improvement scheme (a memetic aspect of EASGS). We also introduce a new set of benchmark games, based on dense or locally-dense graphs that reflect real-world SGS settings. In the majority of 342 test game instances, EASGS outperforms state-of-the-art methods, including a reinforcement learning method, in terms of time scalability, nearly constant memory utilization, and quality of the returned defender's strategies (expected payoffs).