 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCultivating Archipelago of Forests: Evolving Robust Decision Trees through Island Coevolution
Dec 18, 2024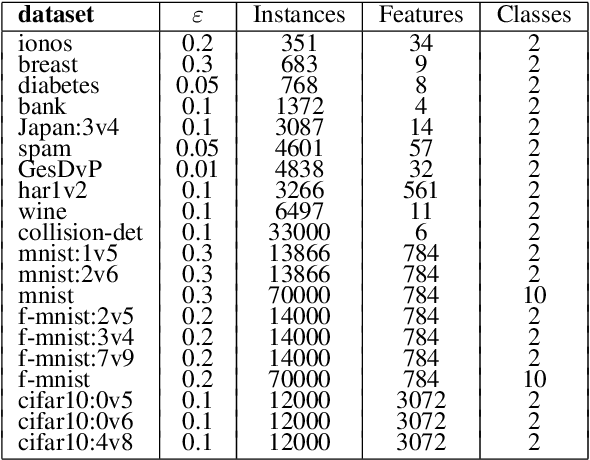
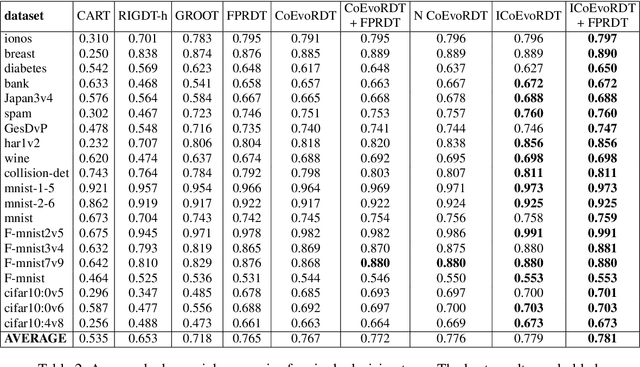
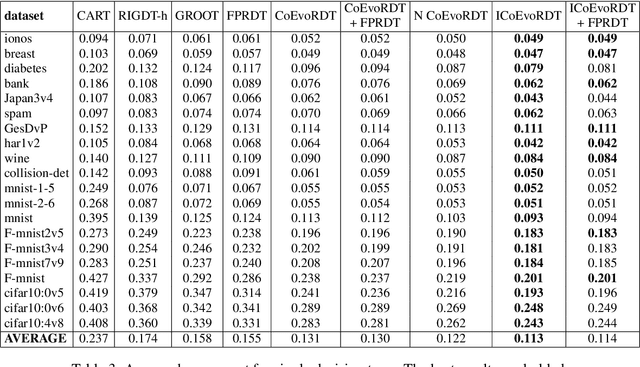
Decision trees are widely used in machine learning due to their simplicity and interpretability, but they often lack robustness to adversarial attacks and data perturbations. The paper proposes a novel island-based coevolutionary algorithm (ICoEvoRDF) for constructing robust decision tree ensembles. The algorithm operates on multiple islands, each containing populations of decision trees and adversarial perturbations. The populations on each island evolve independently, with periodic migration of top-performing decision trees between islands. This approach fosters diversity and enhances the exploration of the solution space, leading to more robust and accurate decision tree ensembles. ICoEvoRDF utilizes a popular game theory concept of mixed Nash equilibrium for ensemble weighting, which further leads to improvement in results. ICoEvoRDF is evaluated on 20 benchmark datasets, demonstrating its superior performance compared to state-of-the-art methods in optimizing both adversarial accuracy and minimax regret. The flexibility of ICoEvoRDF allows for the integration of decision trees from various existing methods, providing a unified framework for combining diverse solutions. Our approach offers a promising direction for developing robust and interpretable machine learning models
Coevolutionary Algorithm for Building Robust Decision Trees under Minimax Regret
Dec 14, 2023



In recent years, there has been growing interest in developing robust machine learning (ML) models that can withstand adversarial attacks, including one of the most widely adopted, efficient, and interpretable ML algorithms-decision trees (DTs). This paper proposes a novel coevolutionary algorithm (CoEvoRDT) designed to create robust DTs capable of handling noisy high-dimensional data in adversarial contexts. Motivated by the limitations of traditional DT algorithms, we leverage adaptive coevolution to allow DTs to evolve and learn from interactions with perturbed input data. CoEvoRDT alternately evolves competing populations of DTs and perturbed features, enabling construction of DTs with desired properties. CoEvoRDT is easily adaptable to various target metrics, allowing the use of tailored robustness criteria such as minimax regret. Furthermore, CoEvoRDT has potential to improve the results of other state-of-the-art methods by incorporating their outcomes (DTs they produce) into the initial population and optimize them in the process of coevolution. Inspired by the game theory, CoEvoRDT utilizes mixed Nash equilibrium to enhance convergence. The method is tested on 20 popular datasets and shows superior performance compared to 4 state-of-the-art algorithms. It outperformed all competing methods on 13 datasets with adversarial accuracy metrics, and on all 20 considered datasets with minimax regret. Strong experimental results and flexibility in choosing the error measure make CoEvoRDT a promising approach for constructing robust DTs in real-world applications.
Evolutionary Approach to Security Games with Signaling
Apr 29, 2022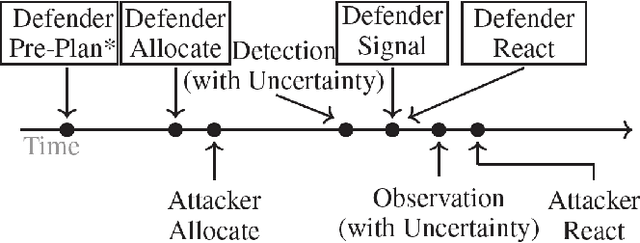
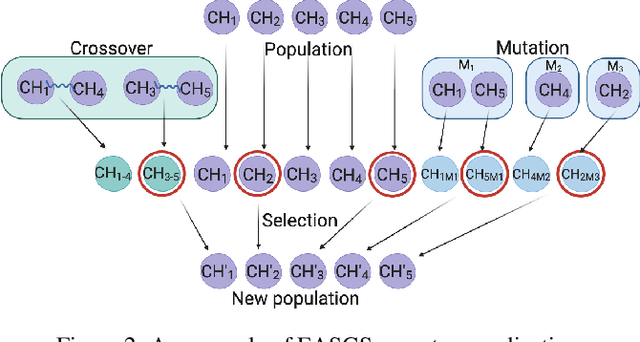
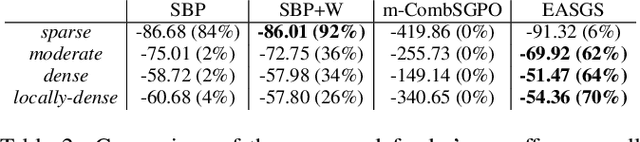
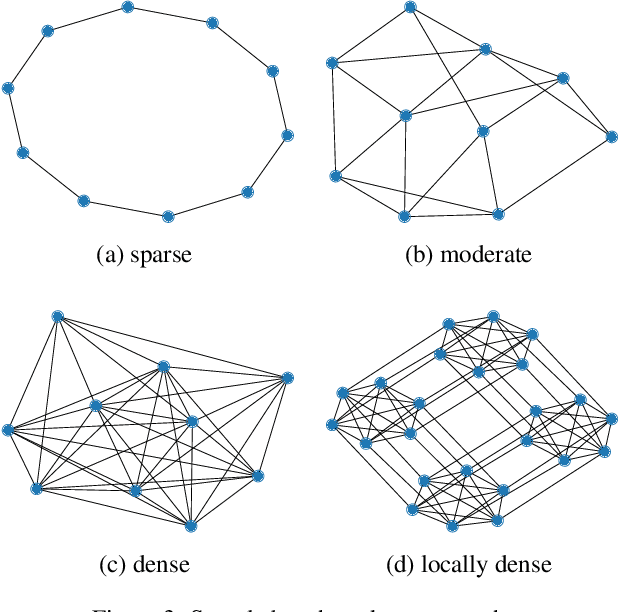
Green Security Games have become a popular way to model scenarios involving the protection of natural resources, such as wildlife. Sensors (e.g. drones equipped with cameras) have also begun to play a role in these scenarios by providing real-time information. Incorporating both human and sensor defender resources strategically is the subject of recent work on Security Games with Signaling (SGS). However, current methods to solve SGS do not scale well in terms of time or memory. We therefore propose a novel approach to SGS, which, for the first time in this domain, employs an Evolutionary Computation paradigm: EASGS. EASGS effectively searches the huge SGS solution space via suitable solution encoding in a chromosome and a specially-designed set of operators. The operators include three types of mutations, each focusing on a particular aspect of the SGS solution, optimized crossover and a local coverage improvement scheme (a memetic aspect of EASGS). We also introduce a new set of benchmark games, based on dense or locally-dense graphs that reflect real-world SGS settings. In the majority of 342 test game instances, EASGS outperforms state-of-the-art methods, including a reinforcement learning method, in terms of time scalability, nearly constant memory utilization, and quality of the returned defender's strategies (expected payoffs).
Learning Attacker's Bounded Rationality Model in Security Games
Sep 27, 2021



The paper proposes a novel neuroevolutionary method (NESG) for calculating leader's payoff in Stackelberg Security Games. The heart of NESG is strategy evaluation neural network (SENN). SENN is able to effectively evaluate leader's strategies against an opponent who may potentially not behave in a perfectly rational way due to certain cognitive biases or limitations. SENN is trained on historical data and does not require any direct prior knowledge regarding the follower's target preferences, payoff distribution or bounded rationality model. NESG was tested on a set of 90 benchmark games inspired by real-world cybersecurity scenario known as deep packet inspections. Experimental results show an advantage of applying NESG over the existing state-of-the-art methods when playing against not perfectly rational opponents. The method provides high quality solutions with superior computation time scalability. Due to generic and knowledge-free construction of NESG, the method may be applied to various real-life security scenarios.
Anchoring Theory in Sequential Stackelberg Games
Dec 07, 2019
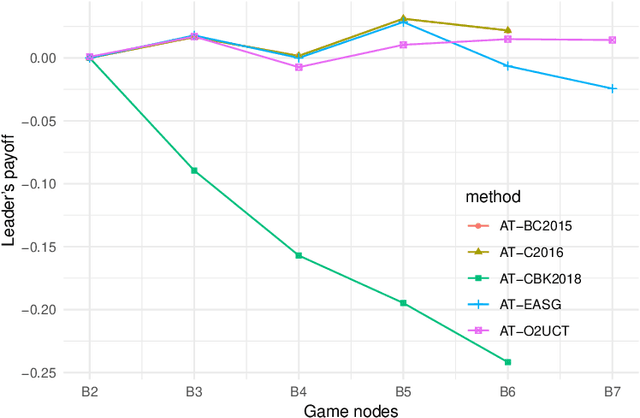
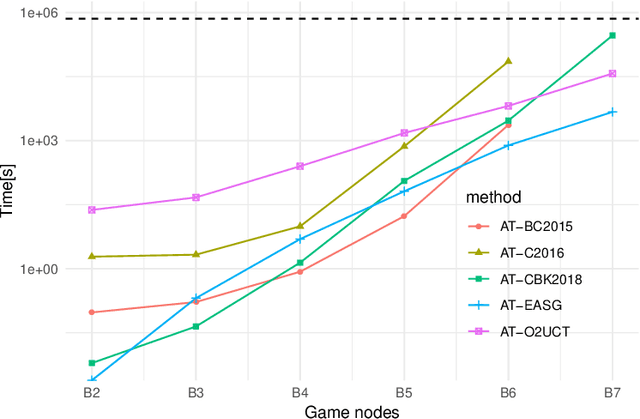
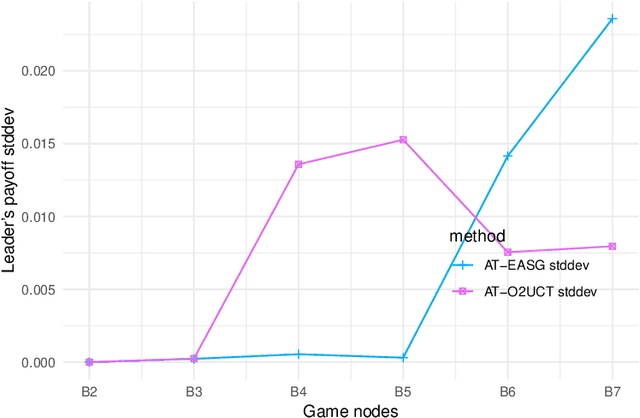
An underlying assumption of Stackelberg Games (SGs) is perfect rationality of the players. However, in real-life situations (which are often modeled by SGs) the followers (terrorists, thieves, poachers or smugglers) -- as humans in general -- may act not in a perfectly rational way, as their decisions may be affected by biases of various kinds which bound rationality of their decisions. One of the popular models of bounded rationality (BR) is Anchoring Theory (AT) which claims that humans have a tendency to flatten probabilities of available options, i.e. they perceive a distribution of these probabilities as being closer to the uniform distribution than it really is. This paper proposes an efficient formulation of AT in sequential extensive-form SGs (named ATSG), suitable for Mixed-Integer Linear Program (MILP) solution methods. ATSG is implemented in three MILP/LP-based state-of-the-art methods for solving sequential SGs and two recently introduced non-MILP approaches: one relying on Monte Carlo sampling (O2UCT) and the other one (EASG) employing Evolutionary Algorithms. Experimental evaluation indicates that both non-MILP heuristic approaches scale better in time than MILP solutions while providing optimal or close-to-optimal solutions. Except for competitive time scalability, an additional asset of non-MILP methods is flexibility of potential BR formulations they are able to incorporate. While MILP approaches accept BR formulations with linear constraints only, no restrictions on the BR form are imposed in either of the two non-MILP methods.
Addressing Expensive Multi-objective Games with Postponed Preference Articulation via Memetic Co-evolution
Nov 17, 2017



This paper presents algorithmic and empirical contributions demonstrating that the convergence characteristics of a co-evolutionary approach to tackle Multi-Objective Games (MOGs) with postponed preference articulation can often be hampered due to the possible emergence of the so-called Red Queen effect. Accordingly, it is hypothesized that the convergence characteristics can be significantly improved through the incorporation of memetics (local solution refinements as a form of lifelong learning), as a promising means of mitigating (or at least suppressing) the Red Queen phenomenon by providing a guiding hand to the purely genetic mechanisms of co-evolution. Our practical motivation is to address MOGs of a time-sensitive nature that are characterized by computationally expensive evaluations, wherein there is a natural need to reduce the total number of true function evaluations consumed in achieving good quality solutions. To this end, we propose novel enhancements to co-evolutionary approaches for tackling MOGs, such that memetic local refinements can be efficiently applied on evolved candidate strategies by searching on computationally cheap surrogate payoff landscapes (that preserve postponed preference conditions). The efficacy of the proposal is demonstrated on a suite of test MOGs that have been designed.