 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchoring Theory in Sequential Stackelberg Games
Dec 07, 2019
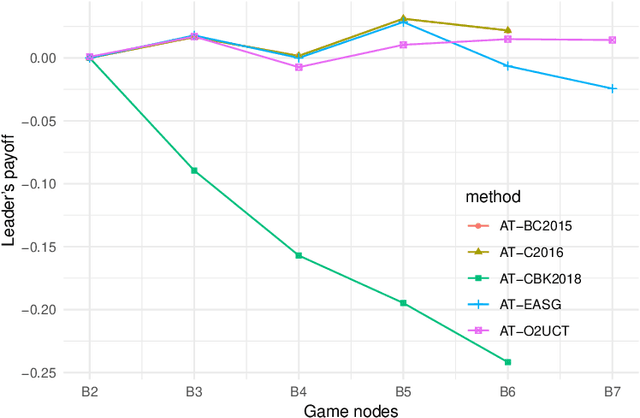
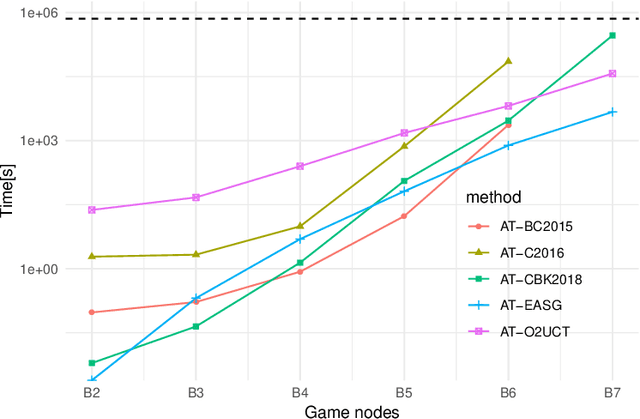
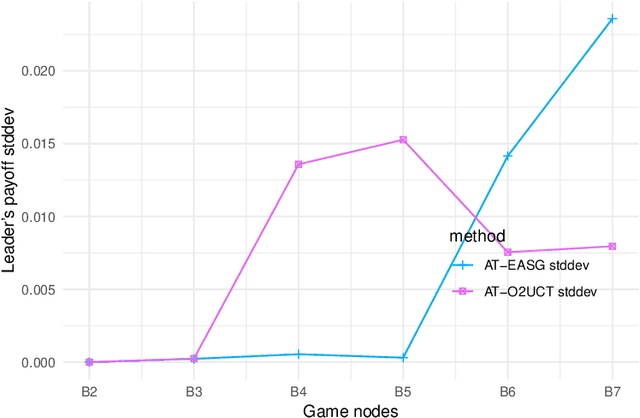
An underlying assumption of Stackelberg Games (SGs) is perfect rationality of the players. However, in real-life situations (which are often modeled by SGs) the followers (terrorists, thieves, poachers or smugglers) -- as humans in general -- may act not in a perfectly rational way, as their decisions may be affected by biases of various kinds which bound rationality of their decisions. One of the popular models of bounded rationality (BR) is Anchoring Theory (AT) which claims that humans have a tendency to flatten probabilities of available options, i.e. they perceive a distribution of these probabilities as being closer to the uniform distribution than it really is. This paper proposes an efficient formulation of AT in sequential extensive-form SGs (named ATSG), suitable for Mixed-Integer Linear Program (MILP) solution methods. ATSG is implemented in three MILP/LP-based state-of-the-art methods for solving sequential SGs and two recently introduced non-MILP approaches: one relying on Monte Carlo sampling (O2UCT) and the other one (EASG) employing Evolutionary Algorithms. Experimental evaluation indicates that both non-MILP heuristic approaches scale better in time than MILP solutions while providing optimal or close-to-optimal solutions. Except for competitive time scalability, an additional asset of non-MILP methods is flexibility of potential BR formulations they are able to incorporate. While MILP approaches accept BR formulations with linear constraints only, no restrictions on the BR form are imposed in either of the two non-MILP methods.
Double-oracle sampling method for Stackelberg Equilibrium approximation in general-sum extensive-form games
Sep 09, 2019
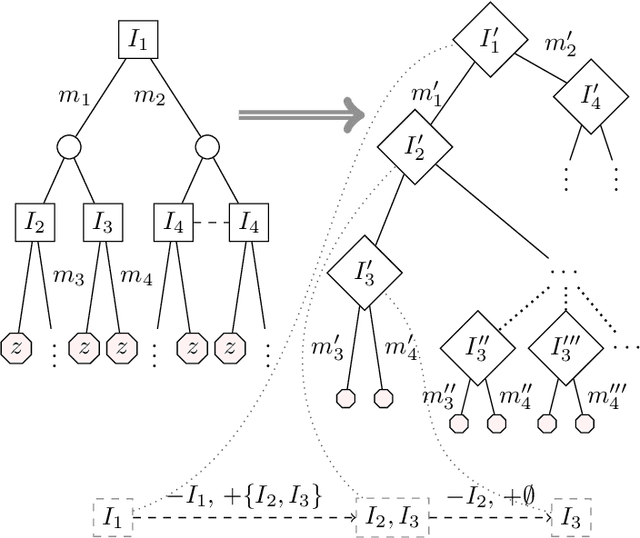
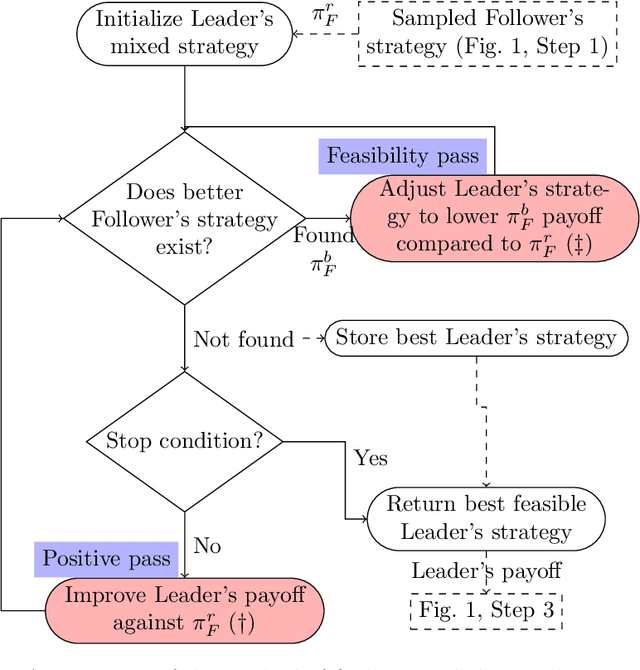
The paper presents a new method for approximating Strong Stackelberg Equilibrium in general-sum sequential games with imperfect information and perfect recall. The proposed approach is generic as it does not rely on any specific properties of a particular game model. The method is based on iterative interleaving of the two following phases: (1) guided Monte Carlo Tree Search sampling of the Follower's strategy space and (2) building the Leader's behavior strategy tree for which the sampled Follower's strategy is an optimal response. The above solution scheme is evaluated with respect to expected Leader's utility and time requirements on three sets of interception games with variable characteristics, played on graphs. A comparison with three state-of-the-art MILP/LP-based methods shows that in vast majority of test cases proposed simulation-based approach leads to optimal Leader's strategies, while excelling the competitive methods in terms of better time scalability and lower memory requirements.