 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Hybrid Metaheuristic: A Universal Framework for Continuous Optimisation
Mar 18, 2026This paper presents the constrained Hybrid Metaheuristic (cHM) algorithm as a general framework for continuous optimisation. Unlike many existing metaheuristics that are tailored to specific function classes or problem domains, cHM is designed to operate across a broad spectrum of objective functions, including those with unknown, heterogeneous, or complex properties such as non-convexity, non-separability, and varying smoothness. We provide a formal description of the algorithm, highlighting its modular structure and two-phase operation, which facilitates dynamic adaptation to the problem's characteristics. A key feature of cHM is its ability to harness synergy between both candidate solutions and component metaheuristic strategies. This property allows the algorithm to apply the most appropriate search behaviour at each stage of the optimisation process, thereby improving convergence and robustness. Our extensive experimental evaluation on 28 benchmark functions demonstrates that cHM consistently matches or outperforms traditional metaheuristics in terms of solution quality and convergence speed. In addition, a practical application of the algorithm is demonstrated for a feature selection problem in the context of data classification. The results underscore its potential as a versatile and effective black-box optimiser suitable for both theoretical research and practical applications.
Reasoning Capabilities of Large Language Models. Lessons Learned from General Game Playing
Feb 22, 2026This paper examines the reasoning capabilities of Large Language Models (LLMs) from a novel perspective, focusing on their ability to operate within formally specified, rule-governed environments. We evaluate four LLMs (Gemini 2.5 Pro and Flash variants, Llama 3.3 70B and GPT-OSS 120B) on a suite of forward-simulation tasks-including next / multistep state formulation, and legal action generation-across a diverse set of reasoning problems illustrated through General Game Playing (GGP) game instances. Beyond reporting instance-level performance, we characterize games based on 40 structural features and analyze correlations between these features and LLM performance. Furthermore, we investigate the effects of various game obfuscations to assess the role of linguistic semantics in game definitions and the impact of potential prior exposure of LLMs to specific games during training. The main results indicate that three of the evaluated models generally perform well across most experimental settings, with performance degradation observed as the evaluation horizon increases (i.e., with a higher number of game steps). Detailed case-based analysis of the LLM performance provides novel insights into common reasoning errors in the considered logic-based problem formulation, including hallucinated rules, redundant state facts, or syntactic errors. Overall, the paper reports clear progress in formal reasoning capabilities of contemporary models.
Automatic Design of Optimization Test Problems with Large Language Models
Feb 02, 2026The development of black-box optimization algorithms depends on the availability of benchmark suites that are both diverse and representative of real-world problem landscapes. Widely used collections such as BBOB and CEC remain dominated by hand-crafted synthetic functions and provide limited coverage of the high-dimensional space of Exploratory Landscape Analysis (ELA) features, which in turn biases evaluation and hinders training of meta-black-box optimizers. We introduce Evolution of Test Functions (EoTF), a framework that automatically generates continuous optimization test functions whose landscapes match a specified target ELA feature vector. EoTF adapts LLM-driven evolutionary search, originally proposed for heuristic discovery, to evolve interpretable, self-contained numpy implementations of objective functions by minimizing the distance between sampled ELA features of generated candidates and a target profile. In experiments on 24 noiseless BBOB functions and a contamination-mitigating suite of 24 MA-BBOB hybrid functions, EoTF reliably produces non-trivial functions with closely matching ELA characteristics and preserves optimizer performance rankings under fixed evaluation budgets, supporting their validity as surrogate benchmarks. While a baseline neural-network-based generator achieves higher accuracy in 2D, EoTF substantially outperforms it in 3D and exhibits stable solution quality as dimensionality increases, highlighting favorable scalability. Overall, EoTF offers a practical route to scalable, portable, and interpretable benchmark generation targeted to desired landscape properties.
The Impact of Bootstrap Sampling Rate on Random Forest Performance in Regression Tasks
Nov 17, 2025Random Forests (RFs) typically train each tree on a bootstrap sample of the same size as the training set, i.e., bootstrap rate (BR) equals 1.0. We systematically examine how varying BR from 0.2 to 5.0 affects RF performance across 39 heterogeneous regression datasets and 16 RF configurations, evaluating with repeated two-fold cross-validation and mean squared error. Our results demonstrate that tuning the BR can yield significant improvements over the default: the best setup relied on BR \leq 1.0 for 24 datasets, BR > 1.0 for 15, and BR = 1.0 was optimal in 4 cases only. We establish a link between dataset characteristics and the preferred BR: datasets with strong global feature-target relationships favor higher BRs, while those with higher local target variance benefit from lower BRs. To further investigate this relationship, we conducted experiments on synthetic datasets with controlled noise levels. These experiments reproduce the observed bias-variance trade-off: in low-noise scenarios, higher BRs effectively reduce model bias, whereas in high-noise settings, lower BRs help reduce model variance. Overall, BR is an influential hyperparameter that should be tuned to optimize RF regression models.
Advancing Generalization Across a Variety of Abstract Visual Reasoning Tasks
May 19, 2025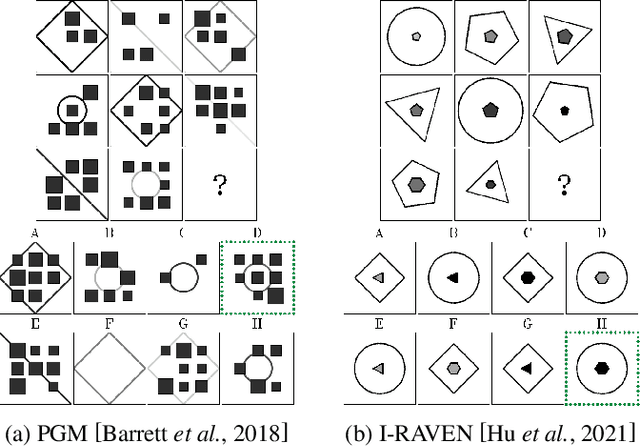
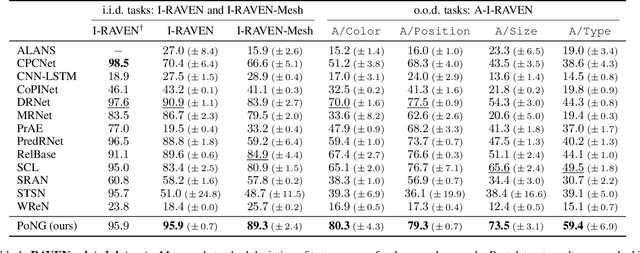
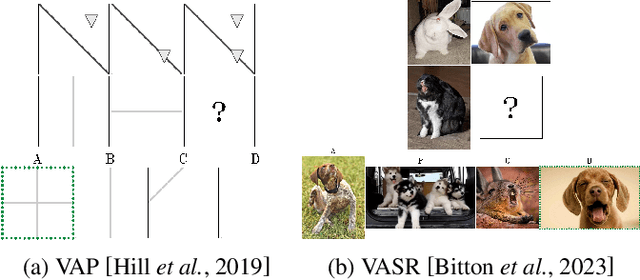

The abstract visual reasoning (AVR) domain presents a diverse suite of analogy-based tasks devoted to studying model generalization. Recent years have brought dynamic progress in the field, particularly in i.i.d. scenarios, in which models are trained and evaluated on the same data distributions. Nevertheless, o.o.d. setups that assess model generalization to new test distributions remain challenging even for the most recent models. To advance generalization in AVR tasks, we present the Pathways of Normalized Group Convolution model (PoNG), a novel neural architecture that features group convolution, normalization, and a parallel design. We consider a wide set of AVR benchmarks, including Raven's Progressive Matrices and visual analogy problems with both synthetic and real-world images. The experiments demonstrate strong generalization capabilities of the proposed model, which in several settings outperforms the existing literature methods.
Modified Adaptive Tree-Structured Parzen Estimator for Hyperparameter Optimization
Feb 02, 2025



In this paper, we review hyperparameter optimization methods for machine learning models, with a particular focus on the Adaptive Tree-Structured Parzen Estimator (ATPE) algorithm. We propose several modifications to ATPE and assess their efficacy on a diverse set of standard benchmark functions. Experimental results demonstrate that the proposed modifications significantly improve the effectiveness of ATPE hyperparameter optimization on selected benchmarks, a finding that holds practical relevance for their application in real-world machine learning / optimization tasks.
Constrained Hybrid Metaheuristic Algorithm for Probabilistic Neural Networks Learning
Jan 26, 2025



This study investigates the potential of hybrid metaheuristic algorithms to enhance the training of Probabilistic Neural Networks (PNNs) by leveraging the complementary strengths of multiple optimisation strategies. Traditional learning methods, such as gradient-based approaches, often struggle to optimise high-dimensional and uncertain environments, while single-method metaheuristics may fail to exploit the solution space fully. To address these challenges, we propose the constrained Hybrid Metaheuristic (cHM) algorithm, a novel approach that combines multiple population-based optimisation techniques into a unified framework. The proposed procedure operates in two phases: an initial probing phase evaluates multiple metaheuristics to identify the best-performing one based on the error rate, followed by a fitting phase where the selected metaheuristic refines the PNN to achieve optimal smoothing parameters. This iterative process ensures efficient exploration and convergence, enhancing the network's generalisation and classification accuracy. cHM integrates several popular metaheuristics, such as BAT, Simulated Annealing, Flower Pollination Algorithm, Bacterial Foraging Optimization, and Particle Swarm Optimisation as internal optimisers. To evaluate cHM performance, experiments were conducted on 16 datasets with varying characteristics, including binary and multiclass classification tasks, balanced and imbalanced class distributions, and diverse feature dimensions. The results demonstrate that cHM effectively combines the strengths of individual metaheuristics, leading to faster convergence and more robust learning. By optimising the smoothing parameters of PNNs, the proposed method enhances classification performance across diverse datasets, proving its application flexibility and efficiency.
Cultivating Archipelago of Forests: Evolving Robust Decision Trees through Island Coevolution
Dec 18, 2024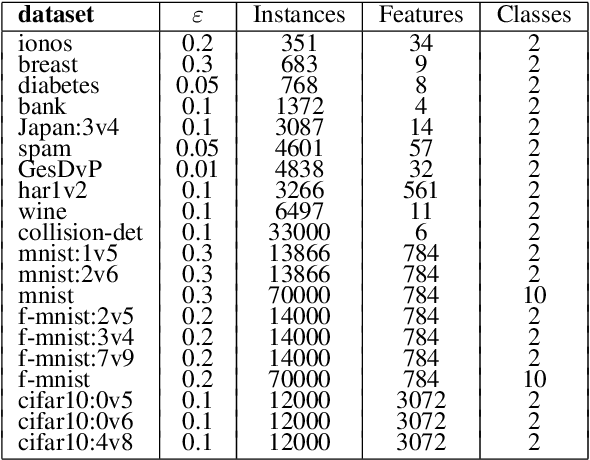
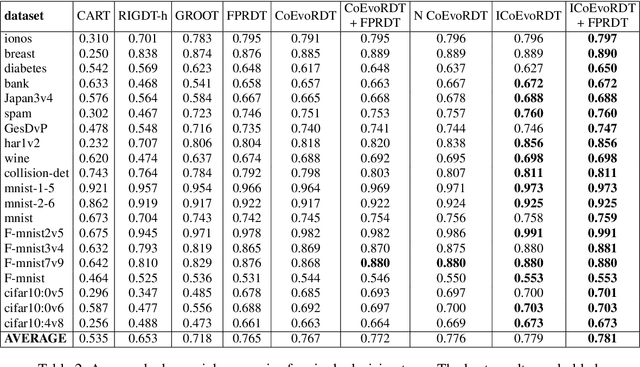
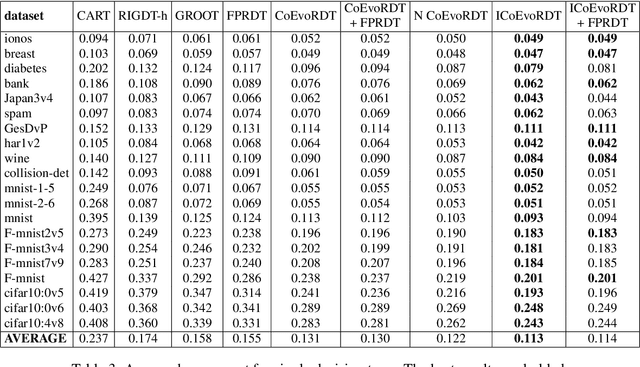
Decision trees are widely used in machine learning due to their simplicity and interpretability, but they often lack robustness to adversarial attacks and data perturbations. The paper proposes a novel island-based coevolutionary algorithm (ICoEvoRDF) for constructing robust decision tree ensembles. The algorithm operates on multiple islands, each containing populations of decision trees and adversarial perturbations. The populations on each island evolve independently, with periodic migration of top-performing decision trees between islands. This approach fosters diversity and enhances the exploration of the solution space, leading to more robust and accurate decision tree ensembles. ICoEvoRDF utilizes a popular game theory concept of mixed Nash equilibrium for ensemble weighting, which further leads to improvement in results. ICoEvoRDF is evaluated on 20 benchmark datasets, demonstrating its superior performance compared to state-of-the-art methods in optimizing both adversarial accuracy and minimax regret. The flexibility of ICoEvoRDF allows for the integration of decision trees from various existing methods, providing a unified framework for combining diverse solutions. Our approach offers a promising direction for developing robust and interpretable machine learning models
Reasoning Limitations of Multimodal Large Language Models. A case study of Bongard Problems
Nov 02, 2024



Abstract visual reasoning (AVR) encompasses a suite of tasks whose solving requires the ability to discover common concepts underlying the set of pictures through an analogy-making process, similarly to human IQ tests. Bongard Problems (BPs), proposed in 1968, constitute a fundamental challenge in this domain mainly due to their requirement to combine visual reasoning and verbal description. This work poses a question whether multimodal large language models (MLLMs) inherently designed to combine vision and language are capable of tackling BPs. To this end, we propose a set of diverse MLLM-suited strategies to tackle BPs and examine four popular proprietary MLLMs: GPT-4o, GPT-4 Turbo, Gemini 1.5 Pro, and Claude 3.5 Sonnet, and four open models: InternVL2-8B, LLaVa-1.6 Mistral-7B, Phi-3.5-Vision, and Pixtral 12B. The above MLLMs are compared on three BP datasets: a set of original BP instances relying on synthetic, geometry-based images and two recent datasets based on real-world images, i.e., Bongard-HOI and Bongard-OpenWorld. The experiments reveal significant limitations of MLLMs in solving BPs. In particular, the models struggle to solve the classical set of synthetic BPs, despite their visual simplicity. Though their performance ameliorates on real-world concepts expressed in Bongard-HOI and Bongard-OpenWorld, the models still have difficulty in utilizing new information to improve their predictions, as well as utilizing a dialog context window effectively. To capture the reasons of performance discrepancy between synthetic and real-world AVR domains, we propose Bongard-RWR, a new BP dataset consisting of real-world images that translates concepts from hand-crafted synthetic BPs to real-world concepts. The MLLMs' results on Bongard-RWR suggest that their poor performance on classical BPs is not due to domain specificity but rather reflects their general AVR limitations.
Bootstrap Sampling Rate Greater than 1.0 May Improve Random Forest Performance
Oct 05, 2024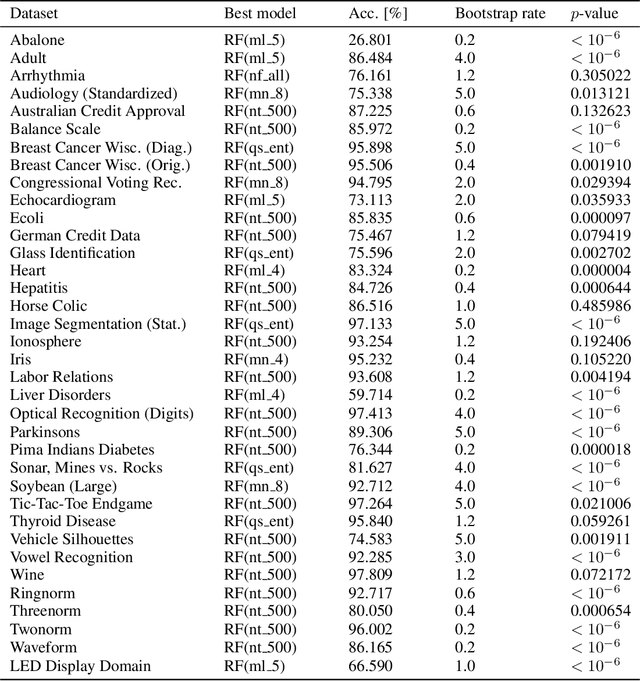
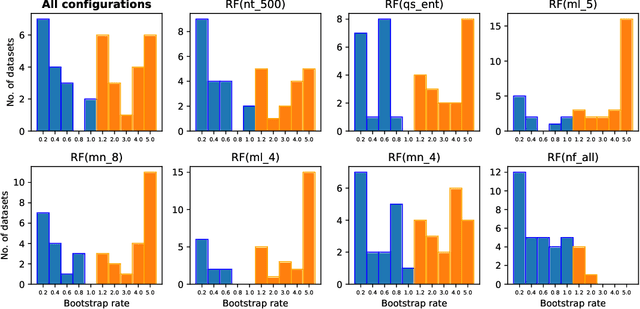
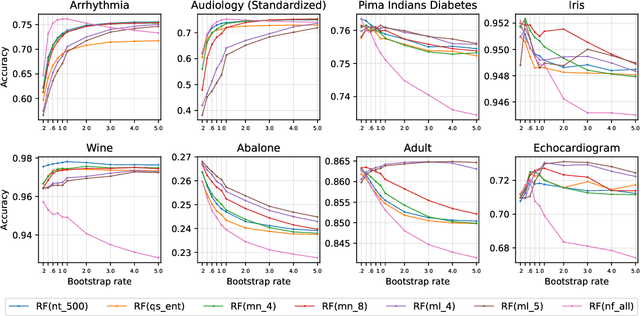
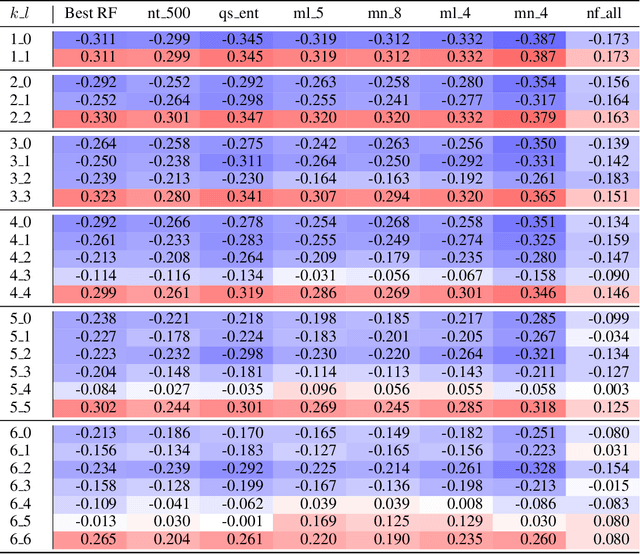
Random forests utilize bootstrap sampling to create an individual training set for each component tree. This involves sampling with replacement, with the number of instances equal to the size of the original training set ($N$). Research literature indicates that drawing fewer than $N$ observations can also yield satisfactory results. The ratio of the number of observations in each bootstrap sample to the total number of training instances is called the bootstrap rate (BR). Sampling more than $N$ observations (BR $>$ 1) has been explored in the literature only to a limited extent and has generally proven ineffective. In this paper, we re-examine this approach using 36 diverse datasets and consider BR values ranging from 1.2 to 5.0. Contrary to previous findings, we show that such parameterization can result in statistically significant improvements in classification accuracy compared to standard settings (BR $\leq$ 1). Furthermore, we investigate what the optimal BR depends on and conclude that it is more a property of the dataset than a dependence on the random forest hyperparameters. Finally, we develop a binary classifier to predict whether the optimal BR is $\leq$ 1 or $>$ 1 for a given dataset, achieving between 81.88\% and 88.81\% accuracy, depending on the experiment configuration.