 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Bootstrap Sampling Rate on Random Forest Performance in Regression Tasks
Nov 17, 2025Random Forests (RFs) typically train each tree on a bootstrap sample of the same size as the training set, i.e., bootstrap rate (BR) equals 1.0. We systematically examine how varying BR from 0.2 to 5.0 affects RF performance across 39 heterogeneous regression datasets and 16 RF configurations, evaluating with repeated two-fold cross-validation and mean squared error. Our results demonstrate that tuning the BR can yield significant improvements over the default: the best setup relied on BR \leq 1.0 for 24 datasets, BR > 1.0 for 15, and BR = 1.0 was optimal in 4 cases only. We establish a link between dataset characteristics and the preferred BR: datasets with strong global feature-target relationships favor higher BRs, while those with higher local target variance benefit from lower BRs. To further investigate this relationship, we conducted experiments on synthetic datasets with controlled noise levels. These experiments reproduce the observed bias-variance trade-off: in low-noise scenarios, higher BRs effectively reduce model bias, whereas in high-noise settings, lower BRs help reduce model variance. Overall, BR is an influential hyperparameter that should be tuned to optimize RF regression models.
Bootstrap Sampling Rate Greater than 1.0 May Improve Random Forest Performance
Oct 05, 2024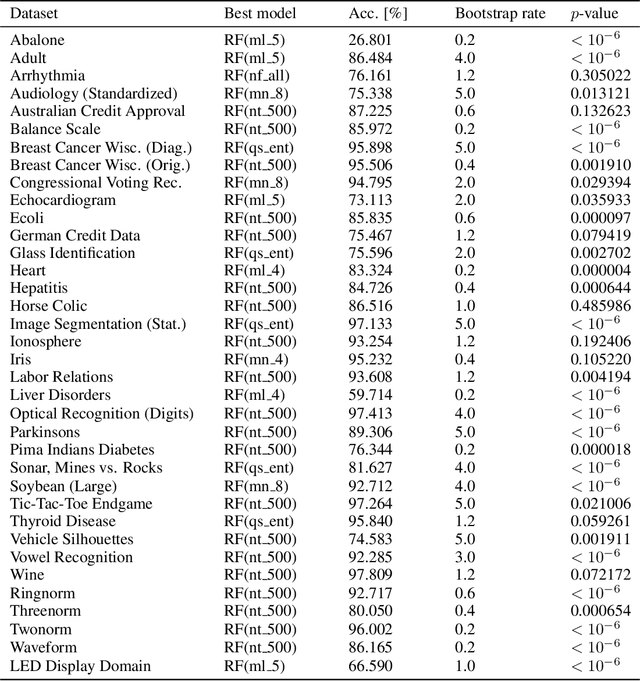
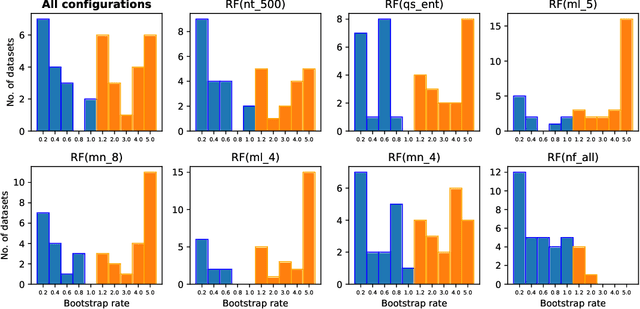
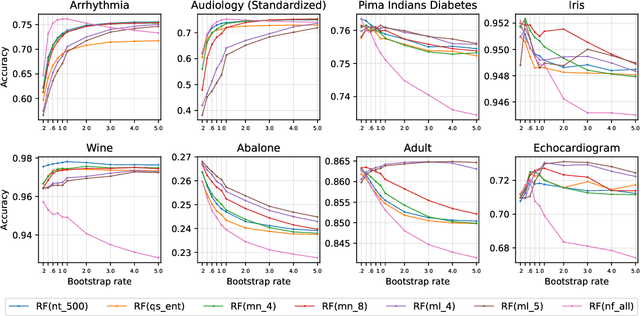
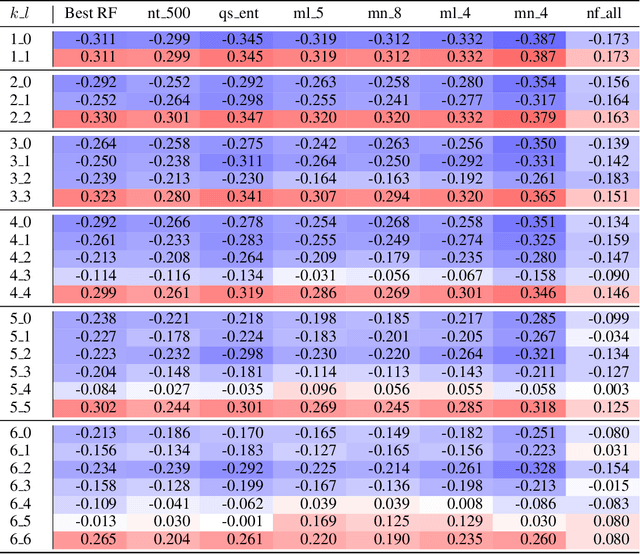
Random forests utilize bootstrap sampling to create an individual training set for each component tree. This involves sampling with replacement, with the number of instances equal to the size of the original training set ($N$). Research literature indicates that drawing fewer than $N$ observations can also yield satisfactory results. The ratio of the number of observations in each bootstrap sample to the total number of training instances is called the bootstrap rate (BR). Sampling more than $N$ observations (BR $>$ 1) has been explored in the literature only to a limited extent and has generally proven ineffective. In this paper, we re-examine this approach using 36 diverse datasets and consider BR values ranging from 1.2 to 5.0. Contrary to previous findings, we show that such parameterization can result in statistically significant improvements in classification accuracy compared to standard settings (BR $\leq$ 1). Furthermore, we investigate what the optimal BR depends on and conclude that it is more a property of the dataset than a dependence on the random forest hyperparameters. Finally, we develop a binary classifier to predict whether the optimal BR is $\leq$ 1 or $>$ 1 for a given dataset, achieving between 81.88\% and 88.81\% accuracy, depending on the experiment configuration.
Prediction of the Facial Growth Direction is Challenging
Sep 28, 2021Facial dysmorphology or malocclusion is frequently associated with abnormal growth of the face. The ability to predict facial growth (FG) direction would allow clinicians to prepare individualized therapy to increase the chance for successful treatment. Prediction of FG direction is a novel problem in the machine learning (ML) domain. In this paper, we perform feature selection and point the attribute that plays a central role in the abovementioned problem. Then we successfully apply data augmentation (DA) methods and improve the previously reported classification accuracy by 2.81%. Finally, we present the results of two experienced clinicians that were asked to solve a similar task to ours and show how tough is solving this problem for human experts.
Prediction of the facial growth direction with Machine Learning methods
Jun 19, 2021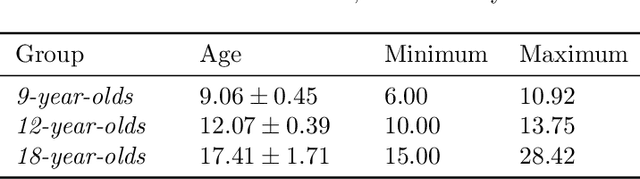
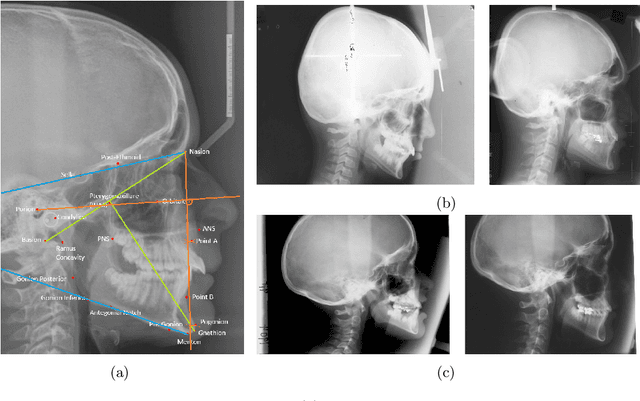
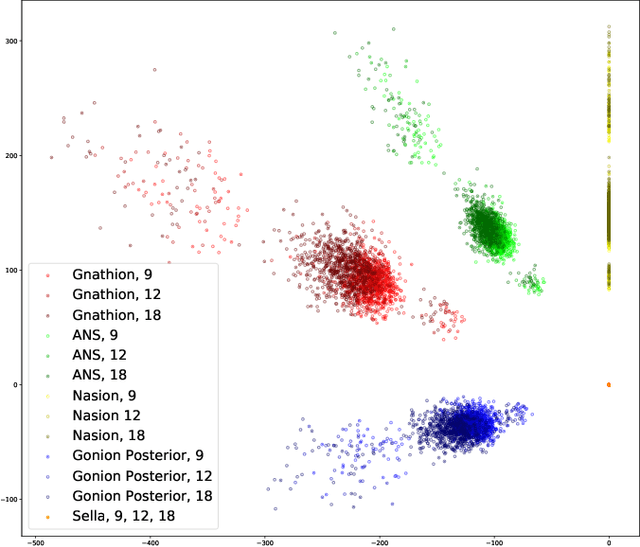
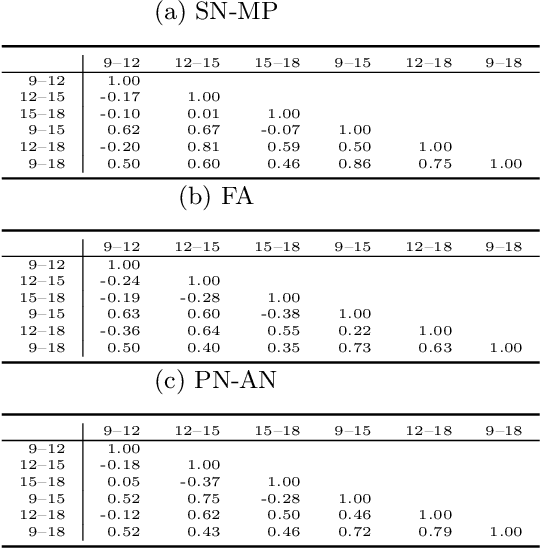
First attempts of prediction of the facial growth (FG) direction were made over half of a century ago. Despite numerous attempts and elapsed time, a satisfactory method has not been established yet and the problem still poses a challenge for medical experts. To our knowledge, this paper is the first Machine Learning approach to the prediction of FG direction. Conducted data analysis reveals the inherent complexity of the problem and explains the reasons of difficulty in FG direction prediction based on 2D X-ray images. To perform growth forecasting, we employ a wide range of algorithms, from logistic regression, through tree ensembles to neural networks and consider three, slightly different, problem formulations. The resulting classification accuracy varies between 71% and 75%.
A Committee of Convolutional Neural Networks for Image Classication in the Concurrent Presence of Feature and Label Noise
Apr 19, 2020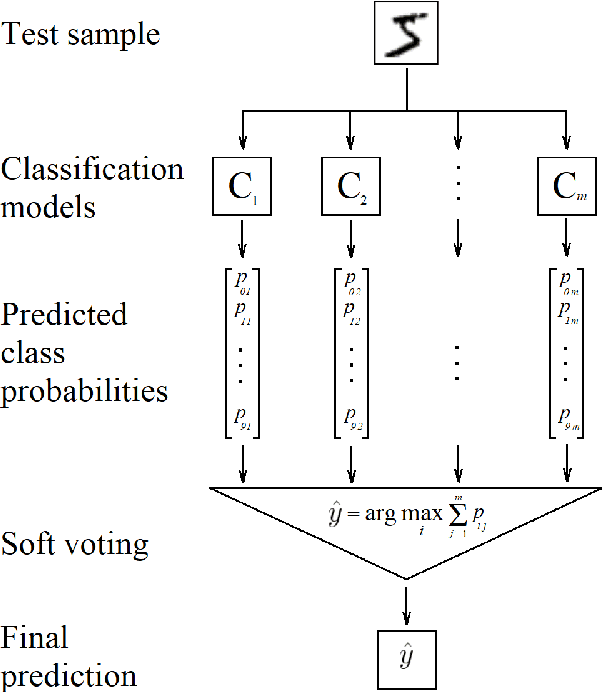
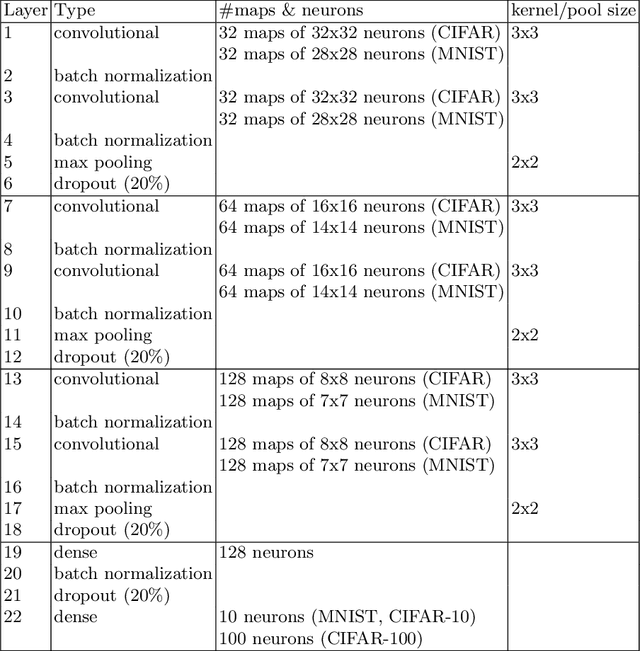
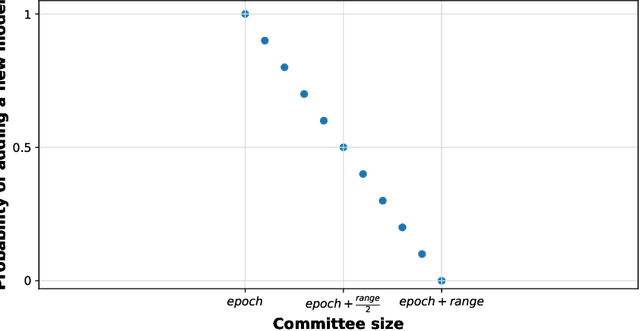
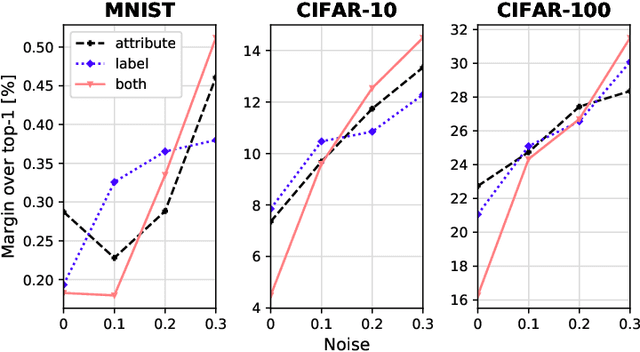
Image classification has become a ubiquitous task. Models trained on good quality data achieve accuracy which in some application domains is already above human-level performance. Unfortunately, real-world data are quite often degenerated by the noise existing in features and/or labels. There are quite many papers that handle the problem of either feature or label noise, separately. However, to the best of our knowledge, this piece of research is the first attempt to address the problem of concurrent occurrence of both types of noise. Basing on the MNIST, CIFAR-10 and CIFAR-100 datasets, we experimentally proved that the difference by which committees beat single models increases along with noise level, no matter it is an attribute or label disruption. Thus, it makes ensembles legitimate to be applied to noisy images with noisy labels. The aforementioned committees' advantage over single models is positively correlated with dataset difficulty level as well. We propose three committee selection algorithms that outperform a strong baseline algorithm which relies on an ensemble of individual (nonassociated) best models.