 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Committee of Convolutional Neural Networks for Image Classication in the Concurrent Presence of Feature and Label Noise
Paper and Code
Apr 19, 2020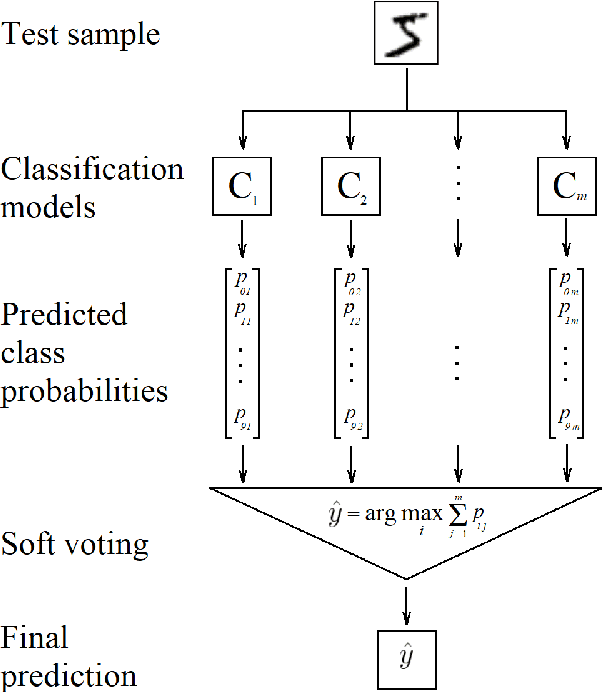
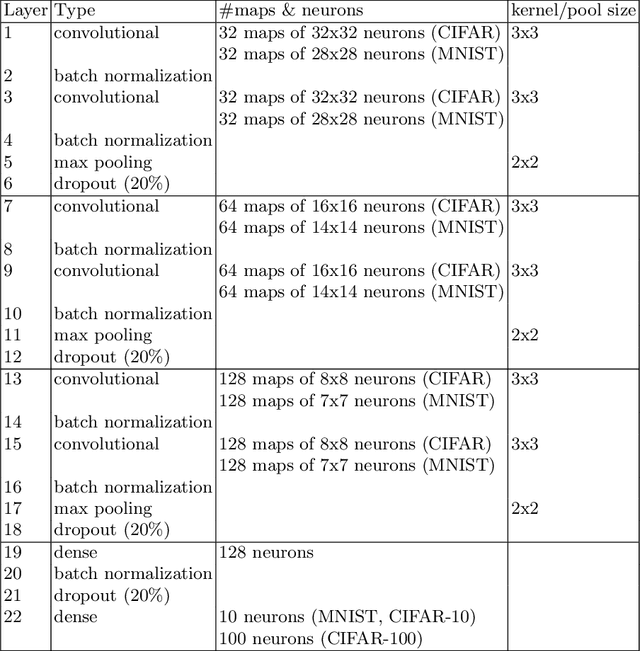
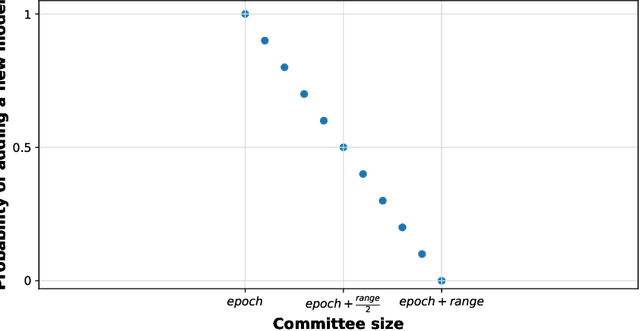
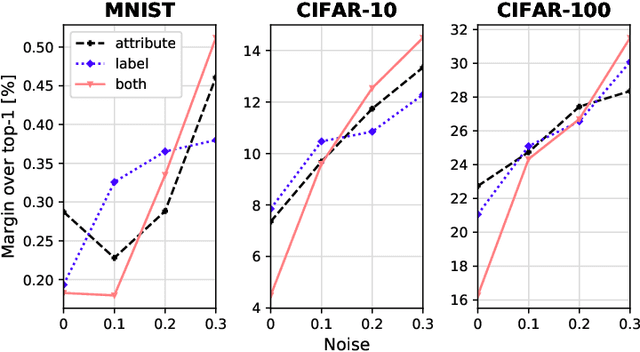
Image classification has become a ubiquitous task. Models trained on good quality data achieve accuracy which in some application domains is already above human-level performance. Unfortunately, real-world data are quite often degenerated by the noise existing in features and/or labels. There are quite many papers that handle the problem of either feature or label noise, separately. However, to the best of our knowledge, this piece of research is the first attempt to address the problem of concurrent occurrence of both types of noise. Basing on the MNIST, CIFAR-10 and CIFAR-100 datasets, we experimentally proved that the difference by which committees beat single models increases along with noise level, no matter it is an attribute or label disruption. Thus, it makes ensembles legitimate to be applied to noisy images with noisy labels. The aforementioned committees' advantage over single models is positively correlated with dataset difficulty level as well. We propose three committee selection algorithms that outperform a strong baseline algorithm which relies on an ensemble of individual (nonassociated) best models.