 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEDD: The MineRL BASALT Evaluation and Demonstrations Dataset for Training and Benchmarking Agents that Solve Fuzzy Tasks
Dec 05, 2023



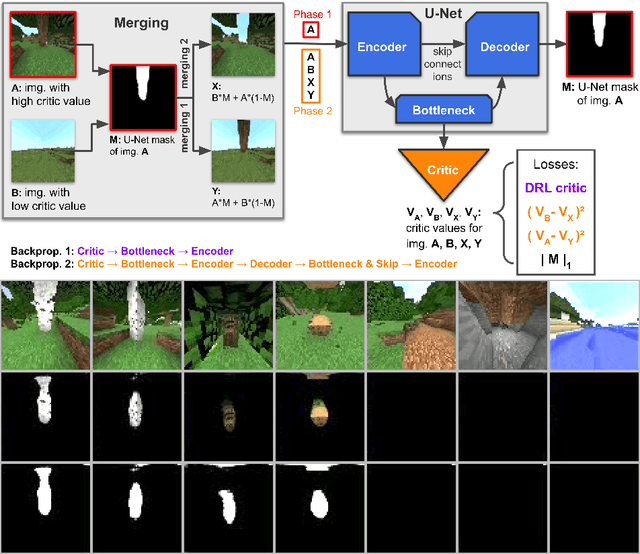
The MineRL BASALT competition has served to catalyze advances in learning from human feedback through four hard-to-specify tasks in Minecraft, such as create and photograph a waterfall. Given the completion of two years of BASALT competitions, we offer to the community a formalized benchmark through the BASALT Evaluation and Demonstrations Dataset (BEDD), which serves as a resource for algorithm development and performance assessment. BEDD consists of a collection of 26 million image-action pairs from nearly 14,000 videos of human players completing the BASALT tasks in Minecraft. It also includes over 3,000 dense pairwise human evaluations of human and algorithmic agents. These comparisons serve as a fixed, preliminary leaderboard for evaluating newly-developed algorithms. To enable this comparison, we present a streamlined codebase for benchmarking new algorithms against the leaderboard. In addition to presenting these datasets, we conduct a detailed analysis of the data from both datasets to guide algorithm development and evaluation. The released code and data are available at https://github.com/minerllabs/basalt-benchmark .
Colour versus Shape Goal Misgeneralization in Reinforcement Learning: A Case Study
Dec 05, 2023We explore colour versus shape goal misgeneralization originally demonstrated by Di Langosco et al. (2022) in the Procgen Maze environment, where, given an ambiguous choice, the agents seem to prefer generalization based on colour rather than shape. After training over 1,000 agents in a simplified version of the environment and evaluating them on over 10 million episodes, we conclude that the behaviour can be attributed to the agents learning to detect the goal object through a specific colour channel. This choice is arbitrary. Additionally, we show how, due to underspecification, the preferences can change when retraining the agents using exactly the same procedure except for using a different random seed for the training run. Finally, we demonstrate the existence of outliers in out-of-distribution behaviour based on training random seed alone.
Towards Solving Fuzzy Tasks with Human Feedback: A Retrospective of the MineRL BASALT 2022 Competition
Mar 23, 2023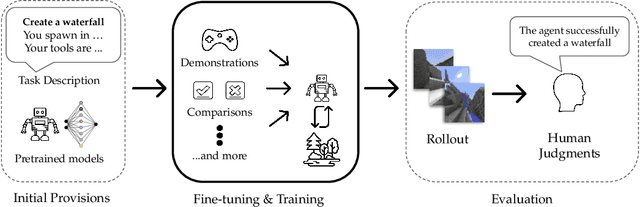

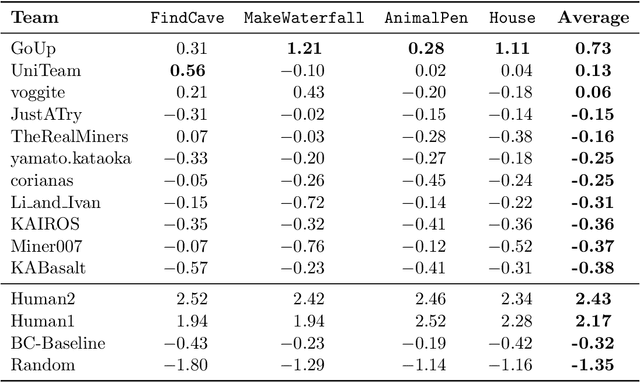
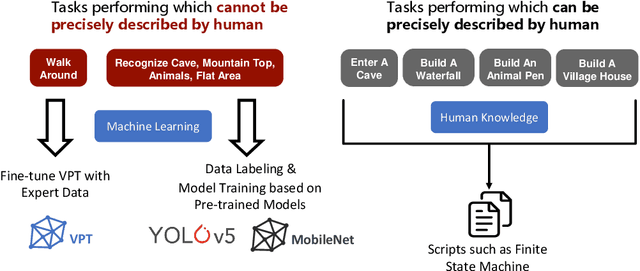
To facilitate research in the direction of fine-tuning foundation models from human feedback, we held the MineRL BASALT Competition on Fine-Tuning from Human Feedback at NeurIPS 2022. The BASALT challenge asks teams to compete to develop algorithms to solve tasks with hard-to-specify reward functions in Minecraft. Through this competition, we aimed to promote the development of algorithms that use human feedback as channels to learn the desired behavior. We describe the competition and provide an overview of the top solutions. We conclude by discussing the impact of the competition and future directions for improvement.
Insights From the NeurIPS 2021 NetHack Challenge
Mar 22, 2022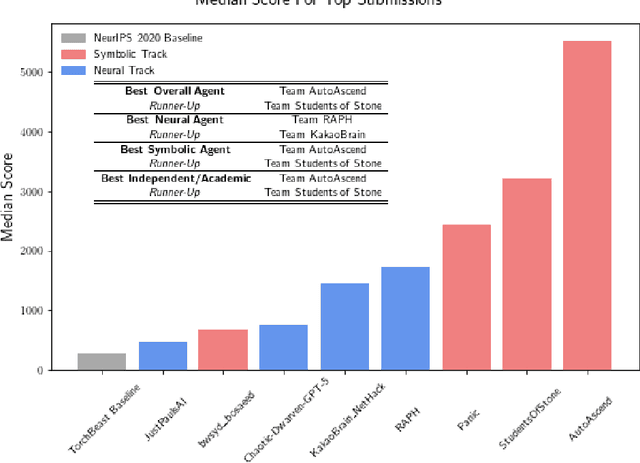

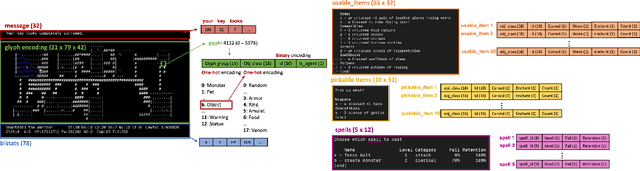
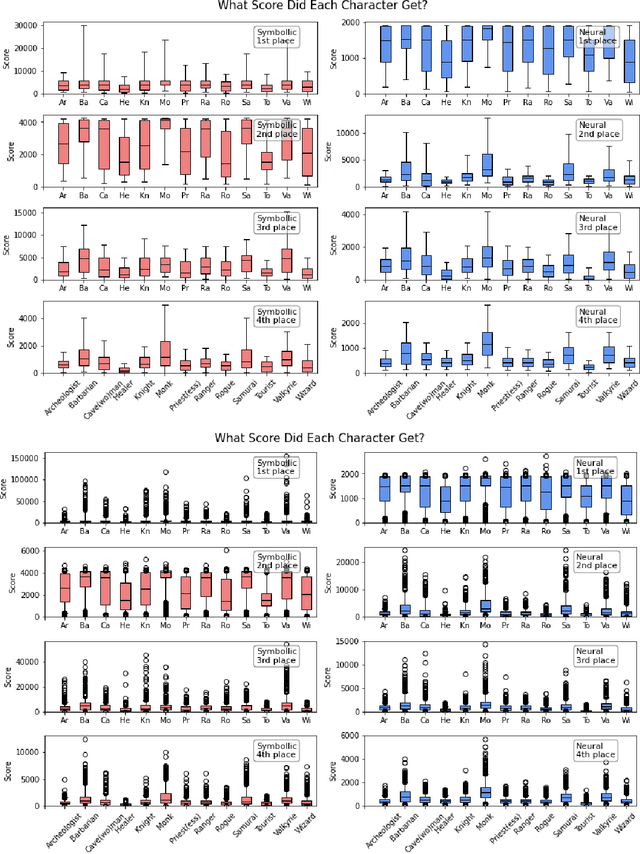
In this report, we summarize the takeaways from the first NeurIPS 2021 NetHack Challenge. Participants were tasked with developing a program or agent that can win (i.e., 'ascend' in) the popular dungeon-crawler game of NetHack by interacting with the NetHack Learning Environment (NLE), a scalable, procedurally generated, and challenging Gym environment for reinforcement learning (RL). The challenge showcased community-driven progress in AI with many diverse approaches significantly beating the previously best results on NetHack. Furthermore, it served as a direct comparison between neural (e.g., deep RL) and symbolic AI, as well as hybrid systems, demonstrating that on NetHack symbolic bots currently outperform deep RL by a large margin. Lastly, no agent got close to winning the game, illustrating NetHack's suitability as a long-term benchmark for AI research.
MineRL Diamond 2021 Competition: Overview, Results, and Lessons Learned
Feb 17, 2022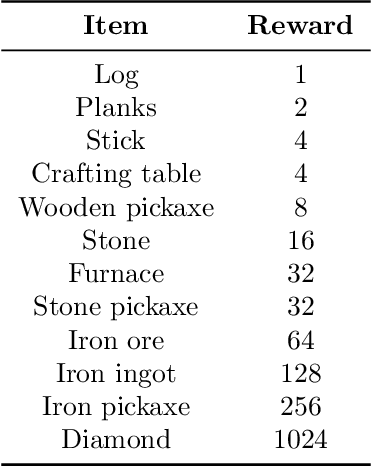
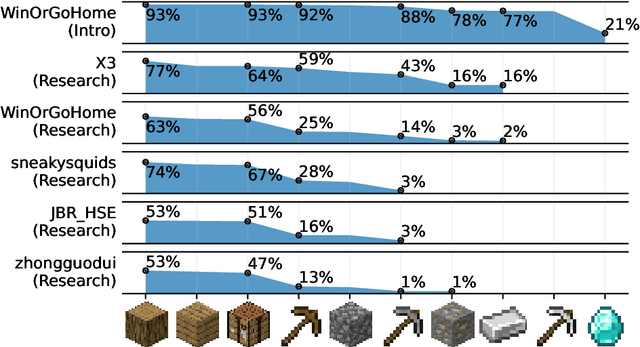
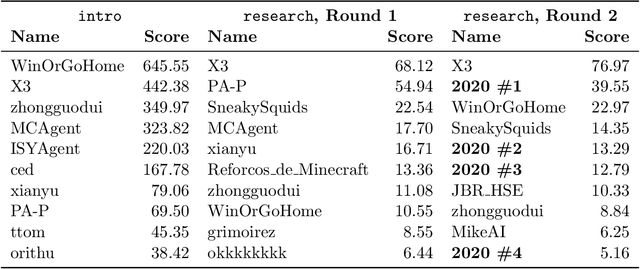
Reinforcement learning competitions advance the field by providing appropriate scope and support to develop solutions toward a specific problem. To promote the development of more broadly applicable methods, organizers need to enforce the use of general techniques, the use of sample-efficient methods, and the reproducibility of the results. While beneficial for the research community, these restrictions come at a cost -- increased difficulty. If the barrier for entry is too high, many potential participants are demoralized. With this in mind, we hosted the third edition of the MineRL ObtainDiamond competition, MineRL Diamond 2021, with a separate track in which we permitted any solution to promote the participation of newcomers. With this track and more extensive tutorials and support, we saw an increased number of submissions. The participants of this easier track were able to obtain a diamond, and the participants of the harder track progressed the generalizable solutions in the same task.
Towards robust and domain agnostic reinforcement learning competitions
Jun 07, 2021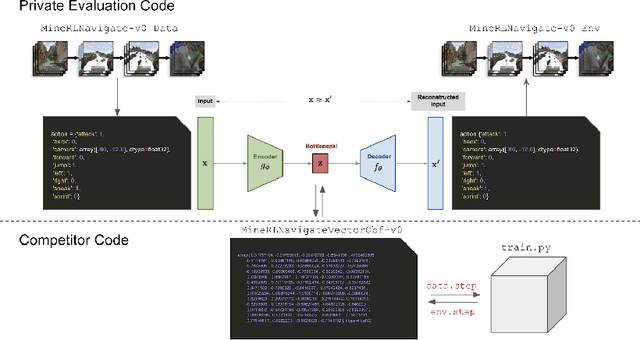

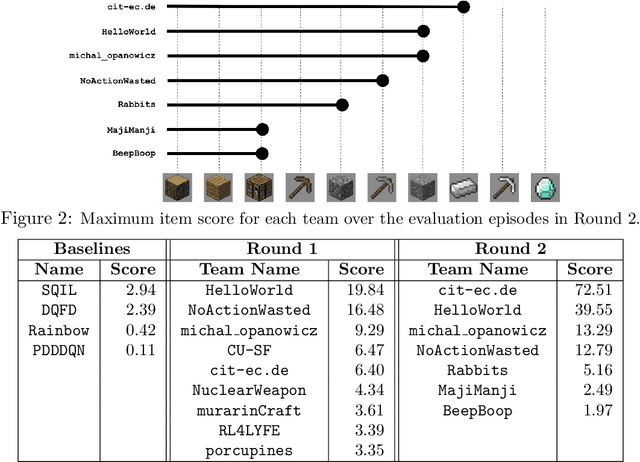
Reinforcement learning competitions have formed the basis for standard research benchmarks, galvanized advances in the state-of-the-art, and shaped the direction of the field. Despite this, a majority of challenges suffer from the same fundamental problems: participant solutions to the posed challenge are usually domain-specific, biased to maximally exploit compute resources, and not guaranteed to be reproducible. In this paper, we present a new framework of competition design that promotes the development of algorithms that overcome these barriers. We propose four central mechanisms for achieving this end: submission retraining, domain randomization, desemantization through domain obfuscation, and the limitation of competition compute and environment-sample budget. To demonstrate the efficacy of this design, we proposed, organized, and ran the MineRL 2020 Competition on Sample-Efficient Reinforcement Learning. In this work, we describe the organizational outcomes of the competition and show that the resulting participant submissions are reproducible, non-specific to the competition environment, and sample/resource efficient, despite the difficult competition task.