 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMineRL Diamond 2021 Competition: Overview, Results, and Lessons Learned
Feb 17, 2022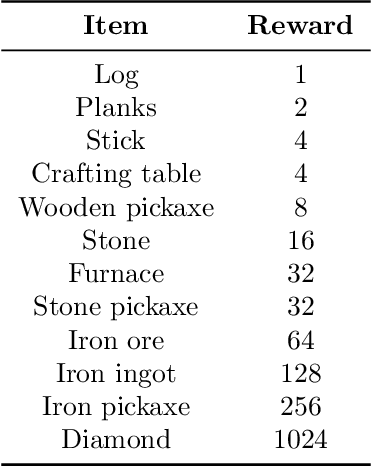
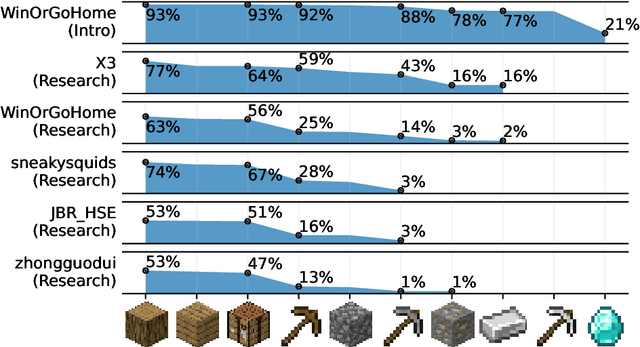
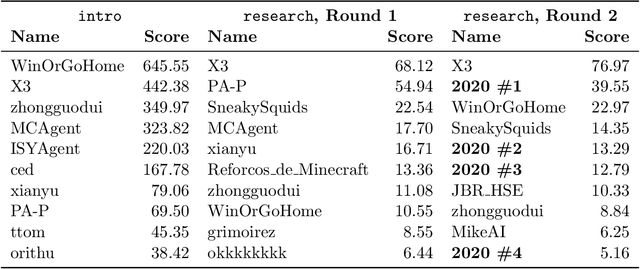
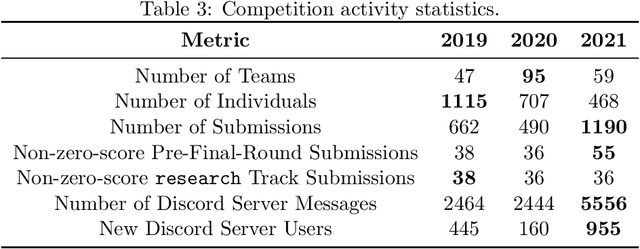
Reinforcement learning competitions advance the field by providing appropriate scope and support to develop solutions toward a specific problem. To promote the development of more broadly applicable methods, organizers need to enforce the use of general techniques, the use of sample-efficient methods, and the reproducibility of the results. While beneficial for the research community, these restrictions come at a cost -- increased difficulty. If the barrier for entry is too high, many potential participants are demoralized. With this in mind, we hosted the third edition of the MineRL ObtainDiamond competition, MineRL Diamond 2021, with a separate track in which we permitted any solution to promote the participation of newcomers. With this track and more extensive tutorials and support, we saw an increased number of submissions. The participants of this easier track were able to obtain a diamond, and the participants of the harder track progressed the generalizable solutions in the same task.
JueWu-MC: Playing Minecraft with Sample-efficient Hierarchical Reinforcement Learning
Dec 07, 2021



Learning rational behaviors in open-world games like Minecraft remains to be challenging for Reinforcement Learning (RL) research due to the compound challenge of partial observability, high-dimensional visual perception and delayed reward. To address this, we propose JueWu-MC, a sample-efficient hierarchical RL approach equipped with representation learning and imitation learning to deal with perception and exploration. Specifically, our approach includes two levels of hierarchy, where the high-level controller learns a policy to control over options and the low-level workers learn to solve each sub-task. To boost the learning of sub-tasks, we propose a combination of techniques including 1) action-aware representation learning which captures underlying relations between action and representation, 2) discriminator-based self-imitation learning for efficient exploration, and 3) ensemble behavior cloning with consistency filtering for policy robustness. Extensive experiments show that JueWu-MC significantly improves sample efficiency and outperforms a set of baselines by a large margin. Notably, we won the championship of the NeurIPS MineRL 2021 research competition and achieved the highest performance score ever.