 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGPO: Self-Generated Preference Optimization based on Self-Improver
Jul 27, 2025Large language models (LLMs), despite their extensive pretraining on diverse datasets, require effective alignment to human preferences for practical and reliable deployment. Conventional alignment methods typically employ off-policy learning and depend on human-annotated datasets, which limits their broad applicability and introduces distribution shift issues during training. To address these challenges, we propose Self-Generated Preference Optimization based on Self-Improver (SGPO), an innovative alignment framework that leverages an on-policy self-improving mechanism. Specifically, the improver refines responses from a policy model to self-generate preference data for direct preference optimization (DPO) of the policy model. Here, the improver and policy are unified into a single model, and in order to generate higher-quality preference data, this self-improver learns to make incremental yet discernible improvements to the current responses by referencing supervised fine-tuning outputs. Experimental results on AlpacaEval 2.0 and Arena-Hard show that the proposed SGPO significantly improves performance over DPO and baseline self-improving methods without using external preference data.
Slot-MLLM: Object-Centric Visual Tokenization for Multimodal LLM
May 26, 2025Recently, multimodal large language models (MLLMs) have emerged as a key approach in achieving artificial general intelligence. In particular, vision-language MLLMs have been developed to generate not only text but also visual outputs from multimodal inputs. This advancement requires efficient image tokens that LLMs can process effectively both in input and output. However, existing image tokenization methods for MLLMs typically capture only global abstract concepts or uniformly segmented image patches, restricting MLLMs' capability to effectively understand or generate detailed visual content, particularly at the object level. To address this limitation, we propose an object-centric visual tokenizer based on Slot Attention specifically for MLLMs. In particular, based on the Q-Former encoder, diffusion decoder, and residual vector quantization, our proposed discretized slot tokens can encode local visual details while maintaining high-level semantics, and also align with textual data to be integrated seamlessly within a unified next-token prediction framework of LLMs. The resulting Slot-MLLM demonstrates significant performance improvements over baselines with previous visual tokenizers across various vision-language tasks that entail local detailed comprehension and generation. Notably, this work is the first demonstration of the feasibility of object-centric slot attention performed with MLLMs and in-the-wild natural images.
TLCR: Token-Level Continuous Reward for Fine-grained Reinforcement Learning from Human Feedback
Jul 23, 2024



Reinforcement Learning from Human Feedback (RLHF) leverages human preference data to train language models to align more closely with human essence. These human preference data, however, are labeled at the sequence level, creating a mismatch between sequence-level preference labels and tokens, which are autoregressively generated from the language model. Although several recent approaches have tried to provide token-level (i.e., dense) rewards for each individual token, these typically rely on predefined discrete reward values (e.g., positive: +1, negative: -1, neutral: 0), failing to account for varying degrees of preference inherent to each token. To address this limitation, we introduce TLCR (Token-Level Continuous Reward) for RLHF, which incorporates a discriminator trained to distinguish positive and negative tokens, and the confidence of the discriminator is used to assign continuous rewards to each token considering the context. Extensive experiments show that our proposed TLCR leads to consistent performance improvements over previous sequence-level or token-level discrete rewards on open-ended generation benchmarks.
Hexa: Self-Improving for Knowledge-Grounded Dialogue System
Oct 22, 2023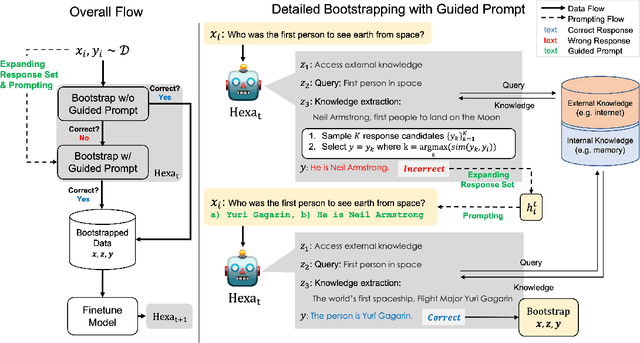
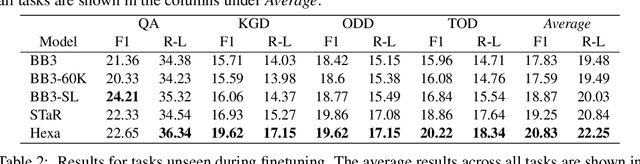
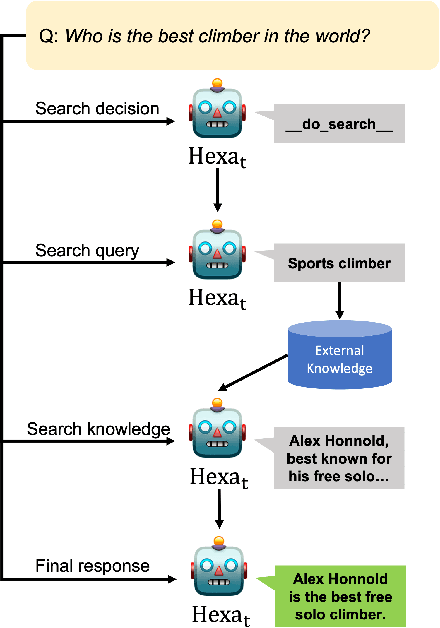

A common practice in knowledge-grounded dialogue generation is to explicitly utilize intermediate steps (e.g., web-search, memory retrieval) with modular approaches. However, data for such steps are often inaccessible compared to those of dialogue responses as they are unobservable in an ordinary dialogue. To fill in the absence of these data, we develop a self-improving method to improve the generative performances of intermediate steps without the ground truth data. In particular, we propose a novel bootstrapping scheme with a guided prompt and a modified loss function to enhance the diversity of appropriate self-generated responses. Through experiments on various benchmark datasets, we empirically demonstrate that our method successfully leverages a self-improving mechanism in generating intermediate and final responses and improves the performances on the task of knowledge-grounded dialogue generation.
Effortless Integration of Memory Management into Open-Domain Conversation Systems
May 23, 2023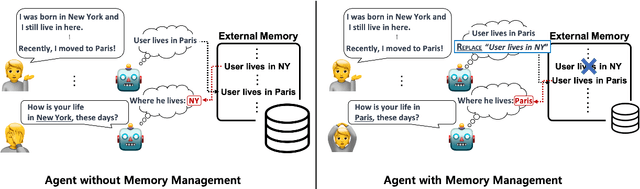
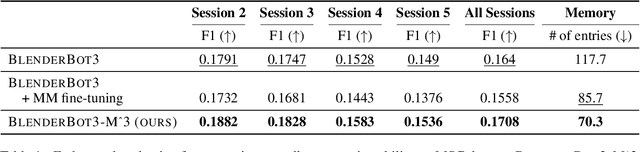
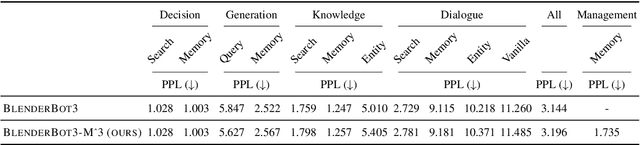
Open-domain conversation systems integrate multiple conversation skills into a single system through a modular approach. One of the limitations of the system, however, is the absence of management capability for external memory. In this paper, we propose a simple method to improve BlenderBot3 by integrating memory management ability into it. Since no training data exists for this purpose, we propose an automating dataset creation for memory management. Our method 1) requires little cost for data construction, 2) does not affect performance in other tasks, and 3) reduces external memory. We show that our proposed model BlenderBot3-M^3, which is multi-task trained with memory management, outperforms BlenderBot3 with a relative 4% performance gain in terms of F1 score.
MAGVLT: Masked Generative Vision-and-Language Transformer
Mar 21, 2023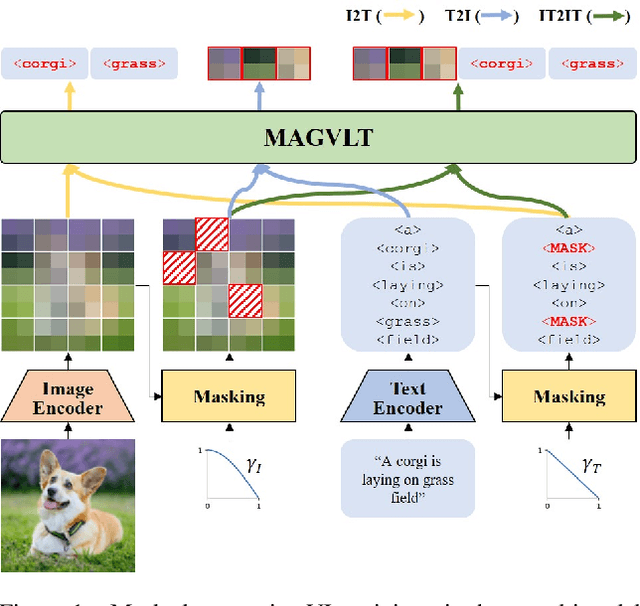
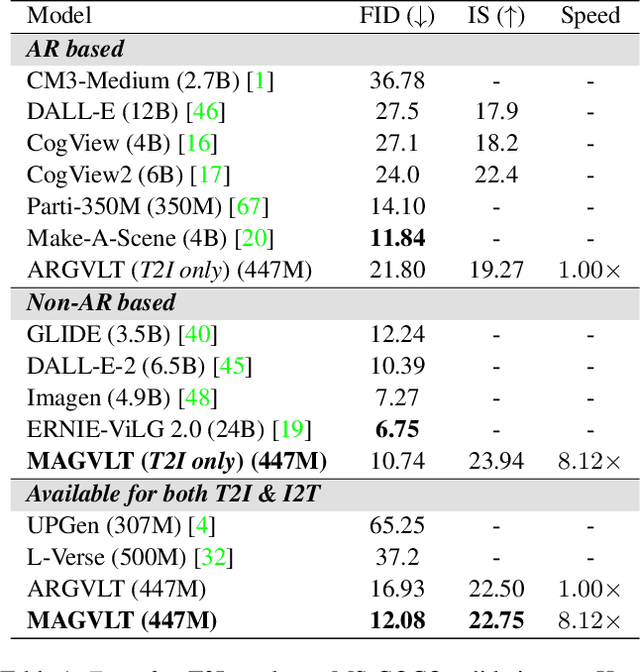
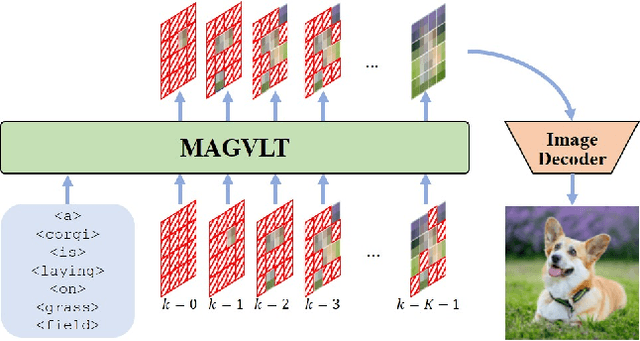
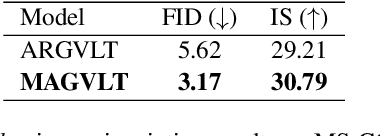
While generative modeling on multimodal image-text data has been actively developed with large-scale paired datasets, there have been limited attempts to generate both image and text data by a single model rather than a generation of one fixed modality conditioned on the other modality. In this paper, we explore a unified generative vision-and-language (VL) model that can produce both images and text sequences. Especially, we propose a generative VL transformer based on the non-autoregressive mask prediction, named MAGVLT, and compare it with an autoregressive generative VL transformer (ARGVLT). In comparison to ARGVLT, the proposed MAGVLT enables bidirectional context encoding, fast decoding by parallel token predictions in an iterative refinement, and extended editing capabilities such as image and text infilling. For rigorous training of our MAGVLT with image-text pairs from scratch, we combine the image-to-text, text-to-image, and joint image-and-text mask prediction tasks. Moreover, we devise two additional tasks based on the step-unrolled mask prediction and the selective prediction on the mixture of two image-text pairs. Experimental results on various downstream generation tasks of VL benchmarks show that our MAGVLT outperforms ARGVLT by a large margin even with significant inference speedup. Particularly, MAGVLT achieves competitive results on both zero-shot image-to-text and text-to-image generation tasks from MS-COCO by one moderate-sized model (fewer than 500M parameters) even without the use of monomodal data and networks.
LECO: Learnable Episodic Count for Task-Specific Intrinsic Reward
Oct 11, 2022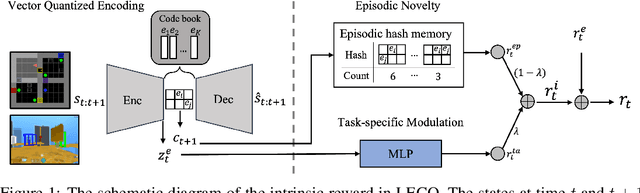
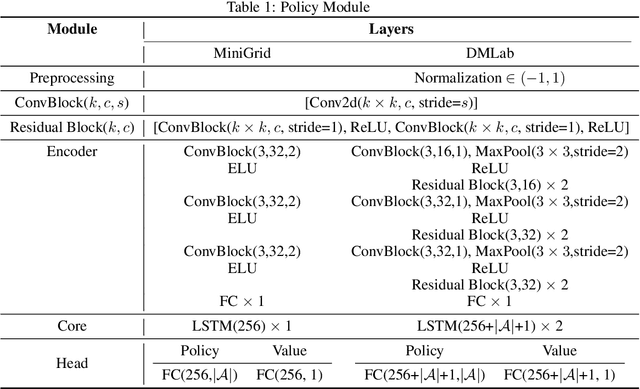
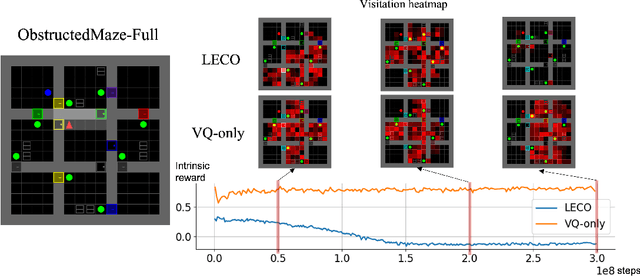
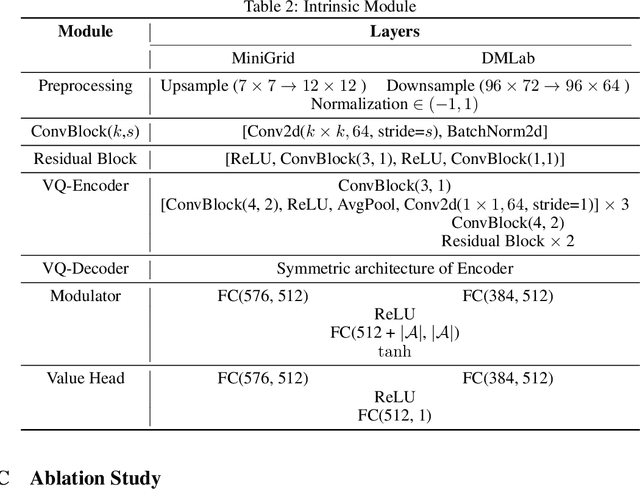
Episodic count has been widely used to design a simple yet effective intrinsic motivation for reinforcement learning with a sparse reward. However, the use of episodic count in a high-dimensional state space as well as over a long episode time requires a thorough state compression and fast hashing, which hinders rigorous exploitation of it in such hard and complex exploration environments. Moreover, the interference from task-irrelevant observations in the episodic count may cause its intrinsic motivation to overlook task-related important changes of states, and the novelty in an episodic manner can lead to repeatedly revisit the familiar states across episodes. In order to resolve these issues, in this paper, we propose a learnable hash-based episodic count, which we name LECO, that efficiently performs as a task-specific intrinsic reward in hard exploration problems. In particular, the proposed intrinsic reward consists of the episodic novelty and the task-specific modulation where the former employs a vector quantized variational autoencoder to automatically obtain the discrete state codes for fast counting while the latter regulates the episodic novelty by learning a modulator to optimize the task-specific extrinsic reward. The proposed LECO specifically enables the automatic transition from exploration to exploitation during reinforcement learning. We experimentally show that in contrast to the previous exploration methods LECO successfully solves hard exploration problems and also scales to large state spaces through the most difficult tasks in MiniGrid and DMLab environments.
Selective Token Generation for Few-shot Natural Language Generation
Sep 17, 2022
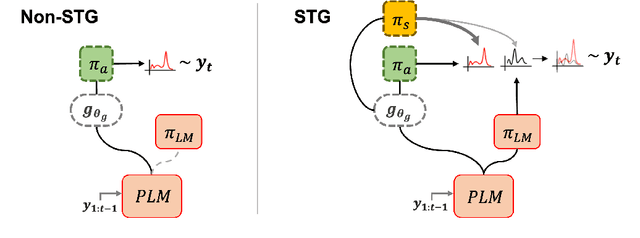
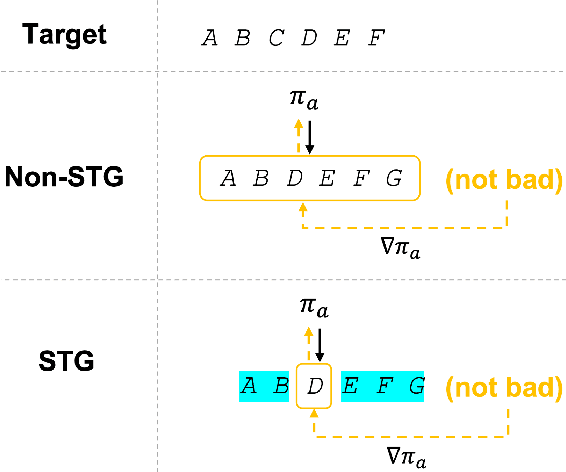
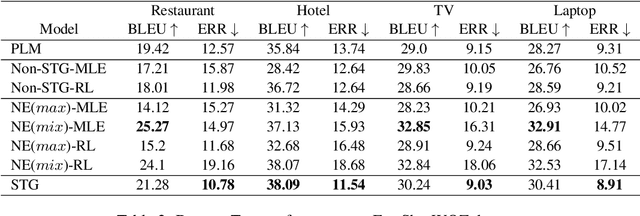
Natural language modeling with limited training data is a challenging problem, and many algorithms make use of large-scale pretrained language models (PLMs) for this due to its great generalization ability. Among them, additive learning that incorporates a task-specific adapter on top of the fixed large-scale PLM has been popularly used in the few-shot setting. However, this added adapter is still easy to disregard the knowledge of the PLM especially for few-shot natural language generation (NLG) since an entire sequence is usually generated by only the newly trained adapter. Therefore, in this work, we develop a novel additive learning algorithm based on reinforcement learning (RL) that selectively outputs language tokens between the task-general PLM and the task-specific adapter during both training and inference. This output token selection over the two generators allows the adapter to take into account solely the task-relevant parts in sequence generation, and therefore makes it more robust to overfitting as well as more stable in RL training. In addition, to obtain the complementary adapter from the PLM for each few-shot task, we exploit a separate selecting module that is also simultaneously trained using RL. Experimental results on various few-shot NLG tasks including question answering, data-to-text generation and text summarization demonstrate that the proposed selective token generation significantly outperforms the previous additive learning algorithms based on the PLMs.
Insights From the NeurIPS 2021 NetHack Challenge
Mar 22, 2022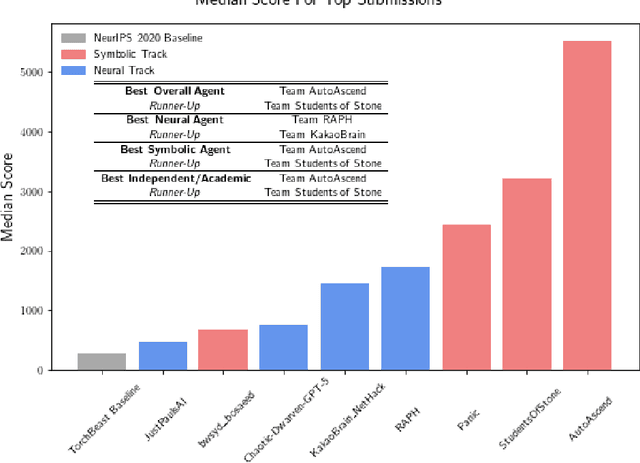

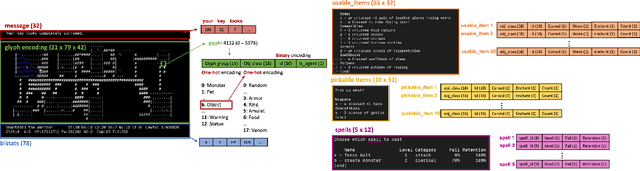
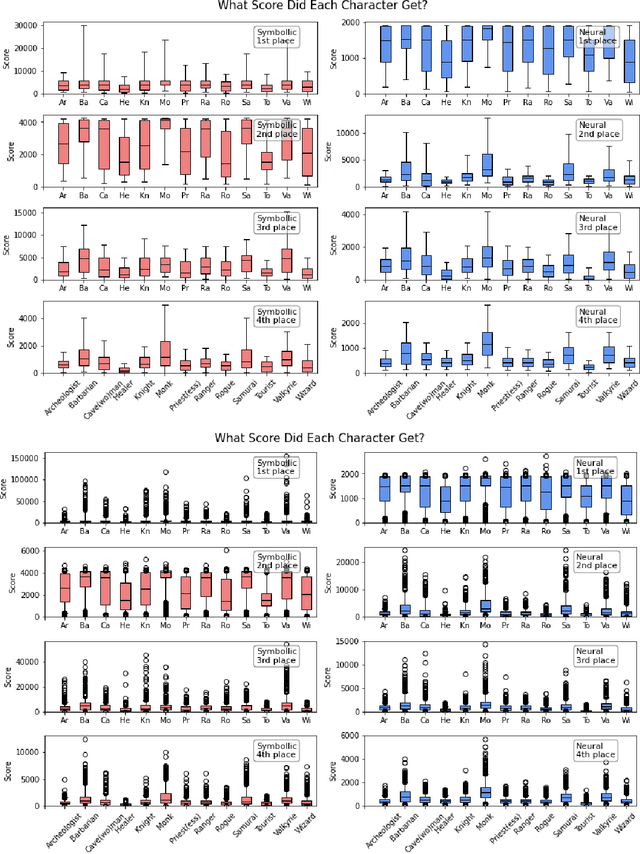
In this report, we summarize the takeaways from the first NeurIPS 2021 NetHack Challenge. Participants were tasked with developing a program or agent that can win (i.e., 'ascend' in) the popular dungeon-crawler game of NetHack by interacting with the NetHack Learning Environment (NLE), a scalable, procedurally generated, and challenging Gym environment for reinforcement learning (RL). The challenge showcased community-driven progress in AI with many diverse approaches significantly beating the previously best results on NetHack. Furthermore, it served as a direct comparison between neural (e.g., deep RL) and symbolic AI, as well as hybrid systems, demonstrating that on NetHack symbolic bots currently outperform deep RL by a large margin. Lastly, no agent got close to winning the game, illustrating NetHack's suitability as a long-term benchmark for AI research.