 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLCR: Token-Level Continuous Reward for Fine-grained Reinforcement Learning from Human Feedback
Jul 23, 2024



Reinforcement Learning from Human Feedback (RLHF) leverages human preference data to train language models to align more closely with human essence. These human preference data, however, are labeled at the sequence level, creating a mismatch between sequence-level preference labels and tokens, which are autoregressively generated from the language model. Although several recent approaches have tried to provide token-level (i.e., dense) rewards for each individual token, these typically rely on predefined discrete reward values (e.g., positive: +1, negative: -1, neutral: 0), failing to account for varying degrees of preference inherent to each token. To address this limitation, we introduce TLCR (Token-Level Continuous Reward) for RLHF, which incorporates a discriminator trained to distinguish positive and negative tokens, and the confidence of the discriminator is used to assign continuous rewards to each token considering the context. Extensive experiments show that our proposed TLCR leads to consistent performance improvements over previous sequence-level or token-level discrete rewards on open-ended generation benchmarks.
Binary Classifier Optimization for Large Language Model Alignment
Apr 06, 2024



Aligning Large Language Models (LLMs) to human preferences through preference optimization has been crucial but labor-intensive, necessitating for each prompt a comparison of both a chosen and a rejected text completion by evaluators. Recently, Kahneman-Tversky Optimization (KTO) has demonstrated that LLMs can be aligned using merely binary "thumbs-up" or "thumbs-down" signals on each prompt-completion pair. In this paper, we present theoretical foundations to explain the successful alignment achieved through these binary signals. Our analysis uncovers a new perspective: optimizing a binary classifier, whose logit is a reward, implicitly induces minimizing the Direct Preference Optimization (DPO) loss. In the process of this discovery, we identified two techniques for effective alignment: reward shift and underlying distribution matching. Consequently, we propose a new algorithm, \textit{Binary Classifier Optimization}, that integrates the techniques. We validate our methodology in two settings: first, on a paired preference dataset, where our method performs on par with DPO and KTO; and second, on binary signal datasets simulating real-world conditions with divergent underlying distributions between thumbs-up and thumbs-down data. Our model consistently demonstrates effective and robust alignment across two base LLMs and three different binary signal datasets, showcasing the strength of our approach to learning from binary feedback.
Hexa: Self-Improving for Knowledge-Grounded Dialogue System
Oct 22, 2023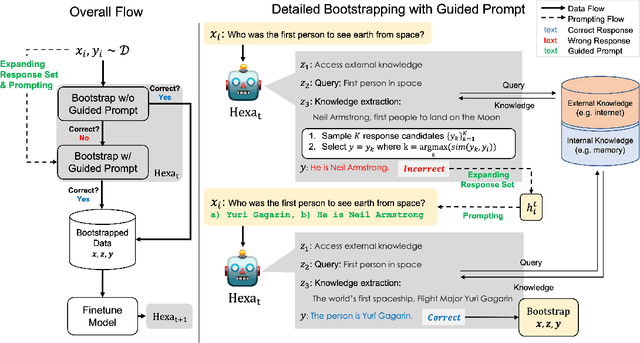
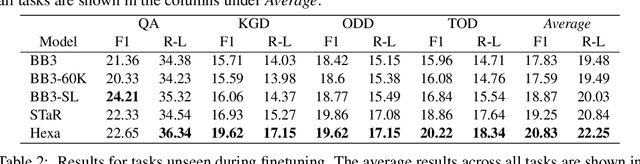
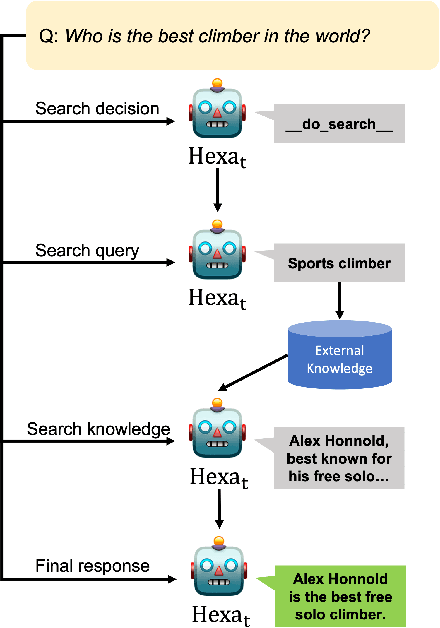

A common practice in knowledge-grounded dialogue generation is to explicitly utilize intermediate steps (e.g., web-search, memory retrieval) with modular approaches. However, data for such steps are often inaccessible compared to those of dialogue responses as they are unobservable in an ordinary dialogue. To fill in the absence of these data, we develop a self-improving method to improve the generative performances of intermediate steps without the ground truth data. In particular, we propose a novel bootstrapping scheme with a guided prompt and a modified loss function to enhance the diversity of appropriate self-generated responses. Through experiments on various benchmark datasets, we empirically demonstrate that our method successfully leverages a self-improving mechanism in generating intermediate and final responses and improves the performances on the task of knowledge-grounded dialogue generation.
Effortless Integration of Memory Management into Open-Domain Conversation Systems
May 23, 2023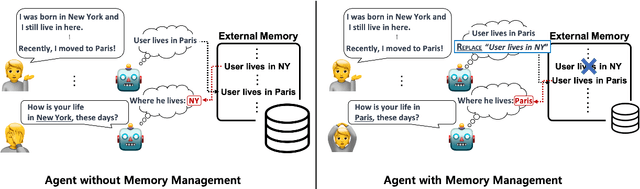
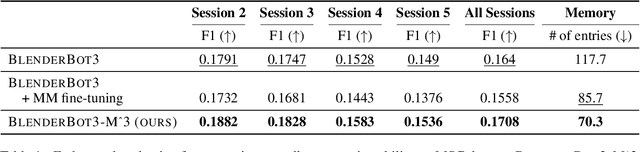
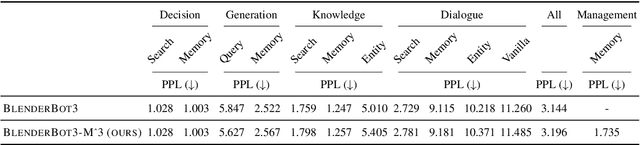
Open-domain conversation systems integrate multiple conversation skills into a single system through a modular approach. One of the limitations of the system, however, is the absence of management capability for external memory. In this paper, we propose a simple method to improve BlenderBot3 by integrating memory management ability into it. Since no training data exists for this purpose, we propose an automating dataset creation for memory management. Our method 1) requires little cost for data construction, 2) does not affect performance in other tasks, and 3) reduces external memory. We show that our proposed model BlenderBot3-M^3, which is multi-task trained with memory management, outperforms BlenderBot3 with a relative 4% performance gain in terms of F1 score.
Boundary-aware Self-supervised Learning for Video Scene Segmentation
Jan 14, 2022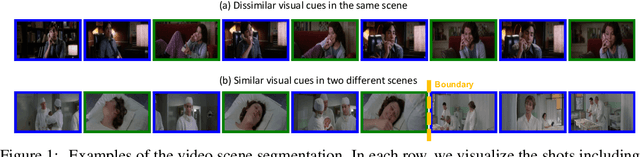
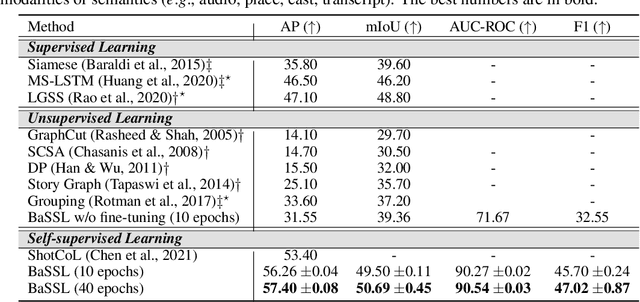
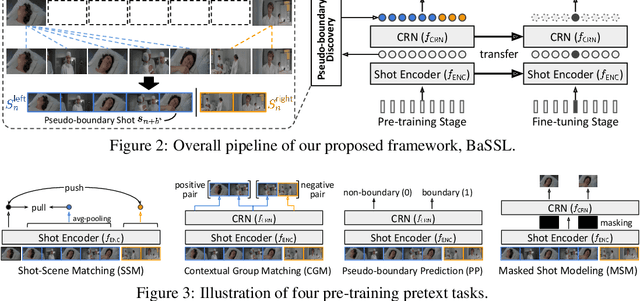
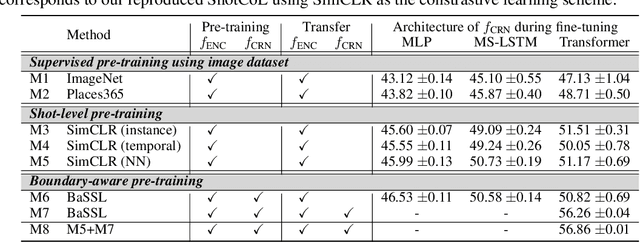
Self-supervised learning has drawn attention through its effectiveness in learning in-domain representations with no ground-truth annotations; in particular, it is shown that properly designed pretext tasks (e.g., contrastive prediction task) bring significant performance gains for downstream tasks (e.g., classification task). Inspired from this, we tackle video scene segmentation, which is a task of temporally localizing scene boundaries in a video, with a self-supervised learning framework where we mainly focus on designing effective pretext tasks. In our framework, we discover a pseudo-boundary from a sequence of shots by splitting it into two continuous, non-overlapping sub-sequences and leverage the pseudo-boundary to facilitate the pre-training. Based on this, we introduce three novel boundary-aware pretext tasks: 1) Shot-Scene Matching (SSM), 2) Contextual Group Matching (CGM) and 3) Pseudo-boundary Prediction (PP); SSM and CGM guide the model to maximize intra-scene similarity and inter-scene discrimination while PP encourages the model to identify transitional moments. Through comprehensive analysis, we empirically show that pre-training and transferring contextual representation are both critical to improving the video scene segmentation performance. Lastly, we achieve the new state-of-the-art on the MovieNet-SSeg benchmark. The code is available at https://github.com/kakaobrain/bassl.
Winning the ICCV'2021 VALUE Challenge: Task-aware Ensemble and Transfer Learning with Visual Concepts
Oct 13, 2021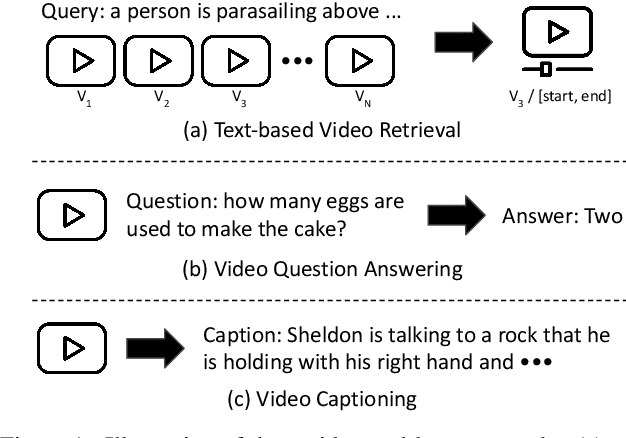

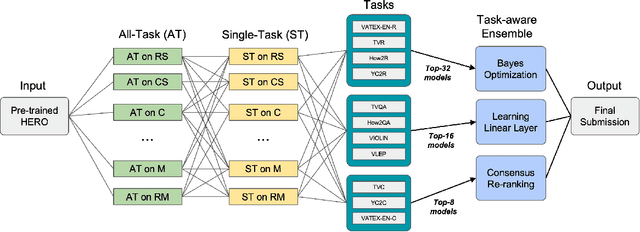
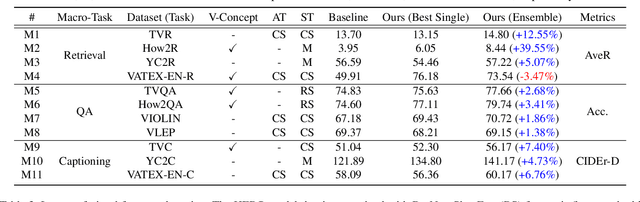
The VALUE (Video-And-Language Understanding Evaluation) benchmark is newly introduced to evaluate and analyze multi-modal representation learning algorithms on three video-and-language tasks: Retrieval, QA, and Captioning. The main objective of the VALUE challenge is to train a task-agnostic model that is simultaneously applicable for various tasks with different characteristics. This technical report describes our winning strategies for the VALUE challenge: 1) single model optimization, 2) transfer learning with visual concepts, and 3) task-aware ensemble. The first and third strategies are designed to address heterogeneous characteristics of each task, and the second one is to leverage rich and fine-grained visual information. We provide a detailed and comprehensive analysis with extensive experimental results. Based on our approach, we ranked first place on the VALUE and QA phases for the competition.