 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHexa: Self-Improving for Knowledge-Grounded Dialogue System
Oct 22, 2023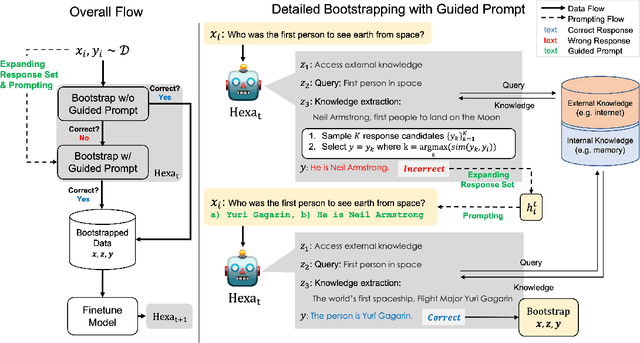
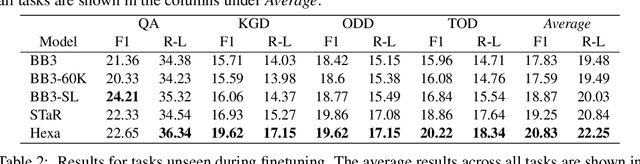
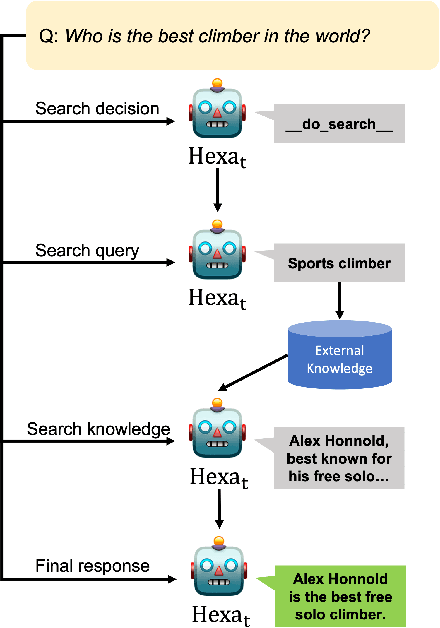

A common practice in knowledge-grounded dialogue generation is to explicitly utilize intermediate steps (e.g., web-search, memory retrieval) with modular approaches. However, data for such steps are often inaccessible compared to those of dialogue responses as they are unobservable in an ordinary dialogue. To fill in the absence of these data, we develop a self-improving method to improve the generative performances of intermediate steps without the ground truth data. In particular, we propose a novel bootstrapping scheme with a guided prompt and a modified loss function to enhance the diversity of appropriate self-generated responses. Through experiments on various benchmark datasets, we empirically demonstrate that our method successfully leverages a self-improving mechanism in generating intermediate and final responses and improves the performances on the task of knowledge-grounded dialogue generation.
Effortless Integration of Memory Management into Open-Domain Conversation Systems
May 23, 2023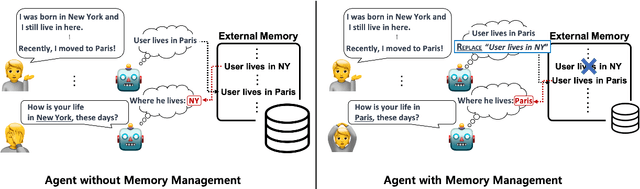
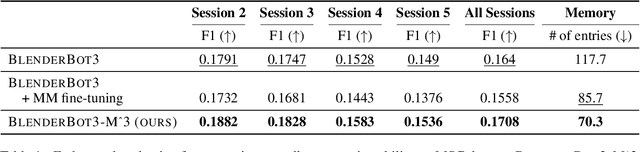
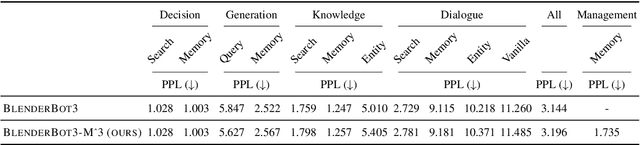
Open-domain conversation systems integrate multiple conversation skills into a single system through a modular approach. One of the limitations of the system, however, is the absence of management capability for external memory. In this paper, we propose a simple method to improve BlenderBot3 by integrating memory management ability into it. Since no training data exists for this purpose, we propose an automating dataset creation for memory management. Our method 1) requires little cost for data construction, 2) does not affect performance in other tasks, and 3) reduces external memory. We show that our proposed model BlenderBot3-M^3, which is multi-task trained with memory management, outperforms BlenderBot3 with a relative 4% performance gain in terms of F1 score.
LECO: Learnable Episodic Count for Task-Specific Intrinsic Reward
Oct 11, 2022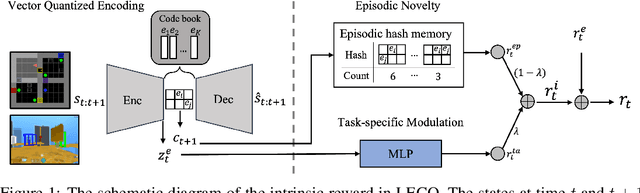
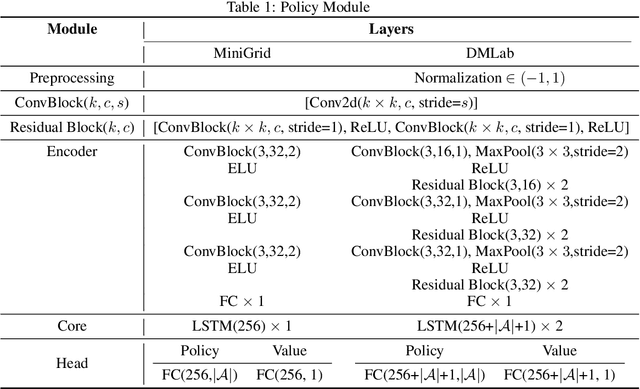
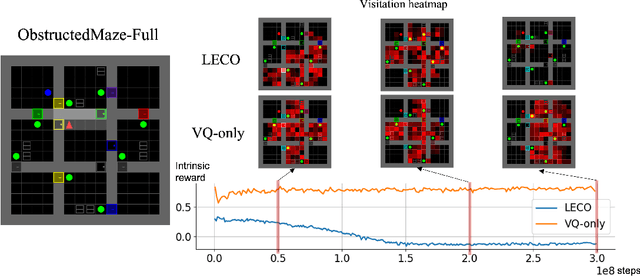
Episodic count has been widely used to design a simple yet effective intrinsic motivation for reinforcement learning with a sparse reward. However, the use of episodic count in a high-dimensional state space as well as over a long episode time requires a thorough state compression and fast hashing, which hinders rigorous exploitation of it in such hard and complex exploration environments. Moreover, the interference from task-irrelevant observations in the episodic count may cause its intrinsic motivation to overlook task-related important changes of states, and the novelty in an episodic manner can lead to repeatedly revisit the familiar states across episodes. In order to resolve these issues, in this paper, we propose a learnable hash-based episodic count, which we name LECO, that efficiently performs as a task-specific intrinsic reward in hard exploration problems. In particular, the proposed intrinsic reward consists of the episodic novelty and the task-specific modulation where the former employs a vector quantized variational autoencoder to automatically obtain the discrete state codes for fast counting while the latter regulates the episodic novelty by learning a modulator to optimize the task-specific extrinsic reward. The proposed LECO specifically enables the automatic transition from exploration to exploitation during reinforcement learning. We experimentally show that in contrast to the previous exploration methods LECO successfully solves hard exploration problems and also scales to large state spaces through the most difficult tasks in MiniGrid and DMLab environments.
Selective Token Generation for Few-shot Natural Language Generation
Sep 17, 2022
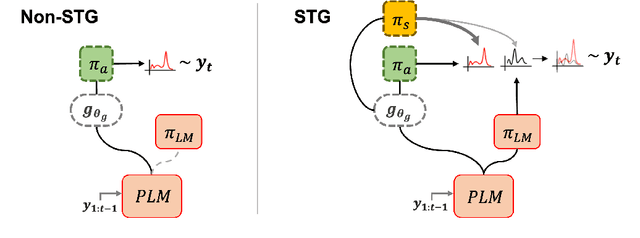
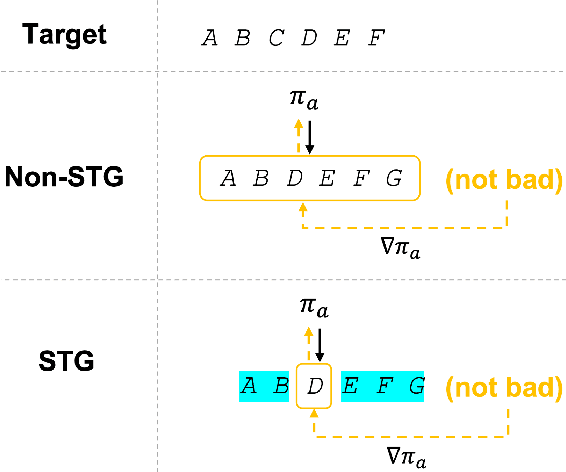
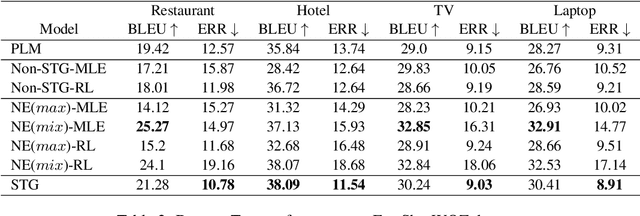
Natural language modeling with limited training data is a challenging problem, and many algorithms make use of large-scale pretrained language models (PLMs) for this due to its great generalization ability. Among them, additive learning that incorporates a task-specific adapter on top of the fixed large-scale PLM has been popularly used in the few-shot setting. However, this added adapter is still easy to disregard the knowledge of the PLM especially for few-shot natural language generation (NLG) since an entire sequence is usually generated by only the newly trained adapter. Therefore, in this work, we develop a novel additive learning algorithm based on reinforcement learning (RL) that selectively outputs language tokens between the task-general PLM and the task-specific adapter during both training and inference. This output token selection over the two generators allows the adapter to take into account solely the task-relevant parts in sequence generation, and therefore makes it more robust to overfitting as well as more stable in RL training. In addition, to obtain the complementary adapter from the PLM for each few-shot task, we exploit a separate selecting module that is also simultaneously trained using RL. Experimental results on various few-shot NLG tasks including question answering, data-to-text generation and text summarization demonstrate that the proposed selective token generation significantly outperforms the previous additive learning algorithms based on the PLMs.
Variational Intrinsic Control Revisited
Oct 07, 2020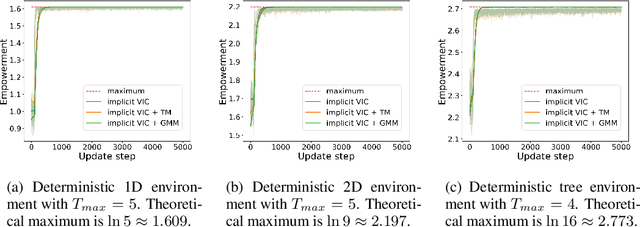

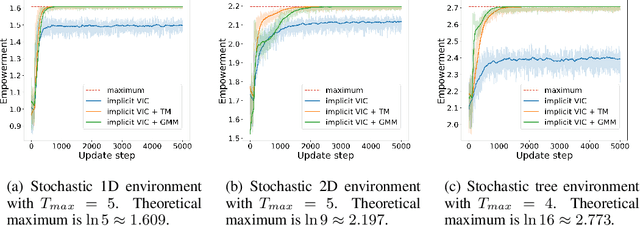
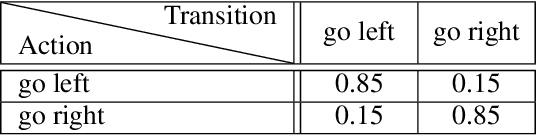
In this paper, we revisit variational intrinsic control (VIC), an unsupervised reinforcement learning method for finding the largest set of intrinsic options available to an agent. In the original work by Gregor et al. (2016), two VIC algorithms were proposed: one that represents the options explicitly, and the other that does it implicitly. We show that the intrinsic reward used in the latter is subject to bias in stochastic environments, causing convergence to suboptimal solutions. To correct this behavior, we propose two methods respectively based on the transitional probability model and Gaussian Mixture Model. We substantiate our claims through rigorous mathematical derivations and experimental analyses.