 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinning the ICCV'2021 VALUE Challenge: Task-aware Ensemble and Transfer Learning with Visual Concepts
Oct 13, 2021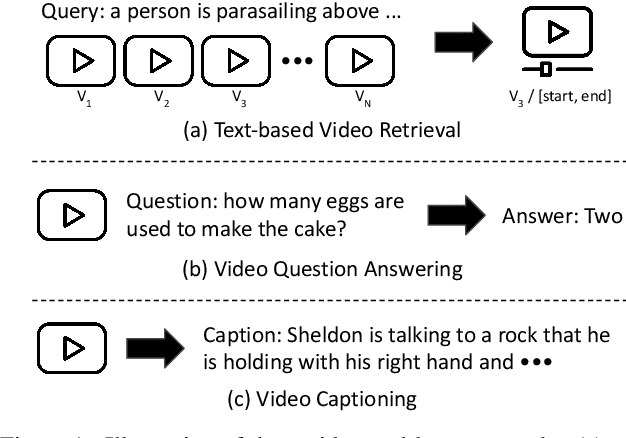

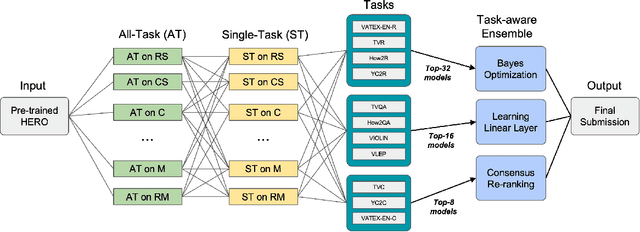
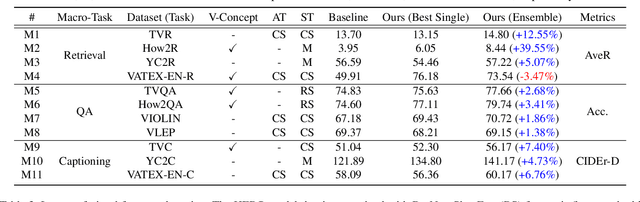
The VALUE (Video-And-Language Understanding Evaluation) benchmark is newly introduced to evaluate and analyze multi-modal representation learning algorithms on three video-and-language tasks: Retrieval, QA, and Captioning. The main objective of the VALUE challenge is to train a task-agnostic model that is simultaneously applicable for various tasks with different characteristics. This technical report describes our winning strategies for the VALUE challenge: 1) single model optimization, 2) transfer learning with visual concepts, and 3) task-aware ensemble. The first and third strategies are designed to address heterogeneous characteristics of each task, and the second one is to leverage rich and fine-grained visual information. We provide a detailed and comprehensive analysis with extensive experimental results. Based on our approach, we ranked first place on the VALUE and QA phases for the competition.