 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLCR: Token-Level Continuous Reward for Fine-grained Reinforcement Learning from Human Feedback
Jul 23, 2024



Reinforcement Learning from Human Feedback (RLHF) leverages human preference data to train language models to align more closely with human essence. These human preference data, however, are labeled at the sequence level, creating a mismatch between sequence-level preference labels and tokens, which are autoregressively generated from the language model. Although several recent approaches have tried to provide token-level (i.e., dense) rewards for each individual token, these typically rely on predefined discrete reward values (e.g., positive: +1, negative: -1, neutral: 0), failing to account for varying degrees of preference inherent to each token. To address this limitation, we introduce TLCR (Token-Level Continuous Reward) for RLHF, which incorporates a discriminator trained to distinguish positive and negative tokens, and the confidence of the discriminator is used to assign continuous rewards to each token considering the context. Extensive experiments show that our proposed TLCR leads to consistent performance improvements over previous sequence-level or token-level discrete rewards on open-ended generation benchmarks.
Fast Generation for Convolutional Autoregressive Models
Apr 20, 2017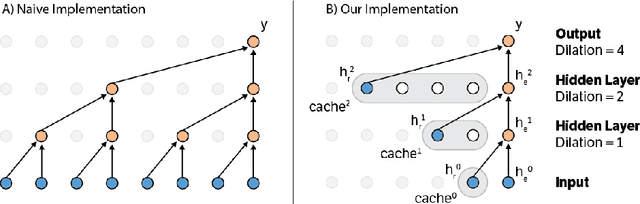
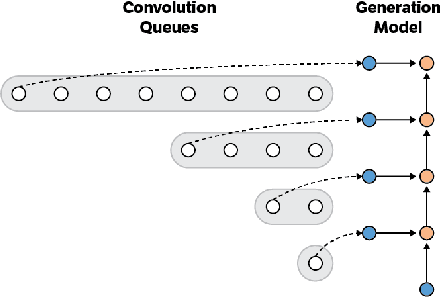
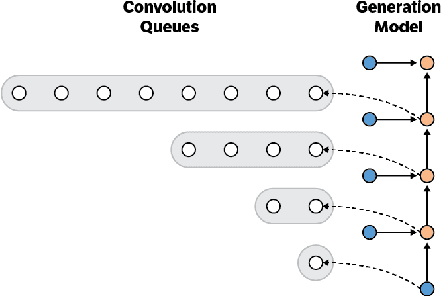
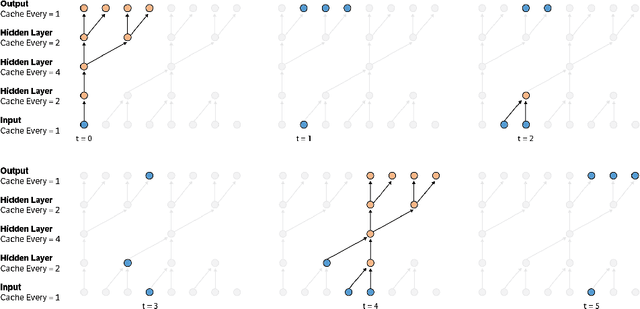
Convolutional autoregressive models have recently demonstrated state-of-the-art performance on a number of generation tasks. While fast, parallel training methods have been crucial for their success, generation is typically implemented in a na\"{i}ve fashion where redundant computations are unnecessarily repeated. This results in slow generation, making such models infeasible for production environments. In this work, we describe a method to speed up generation in convolutional autoregressive models. The key idea is to cache hidden states to avoid redundant computation. We apply our fast generation method to the Wavenet and PixelCNN++ models and achieve up to $21\times$ and $183\times$ speedups respectively.
Fast Wavenet Generation Algorithm
Nov 29, 2016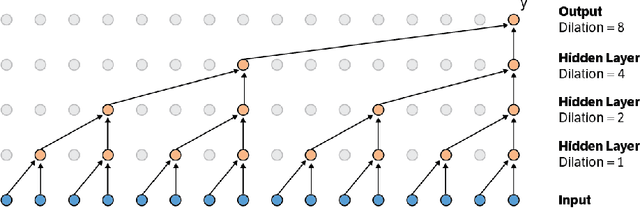
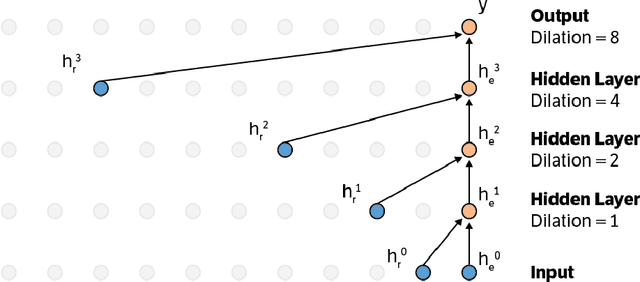
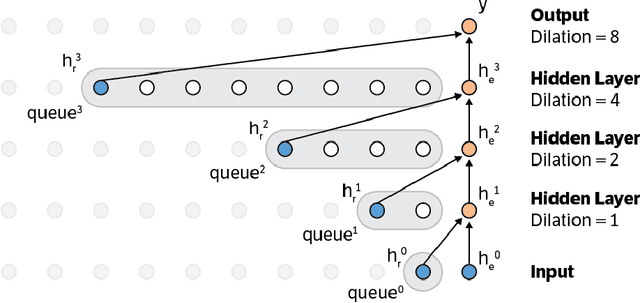
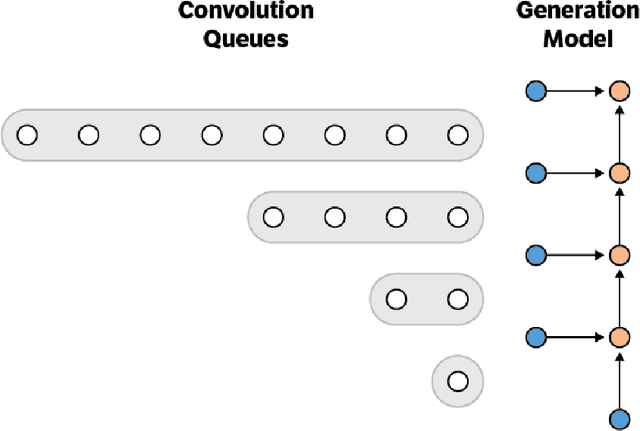
This paper presents an efficient implementation of the Wavenet generation process called Fast Wavenet. Compared to a naive implementation that has complexity O(2^L) (L denotes the number of layers in the network), our proposed approach removes redundant convolution operations by caching previous calculations, thereby reducing the complexity to O(L) time. Timing experiments show significant advantages of our fast implementation over a naive one. While this method is presented for Wavenet, the same scheme can be applied anytime one wants to perform autoregressive generation or online prediction using a model with dilated convolution layers. The code for our method is publicly available.
Streaming Recommender Systems
Jul 21, 2016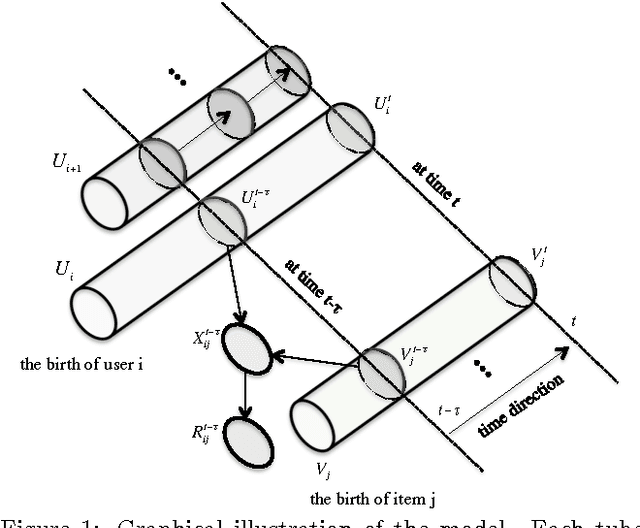
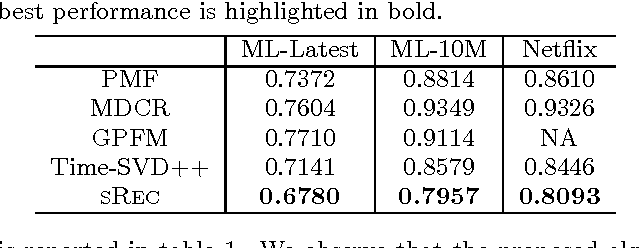
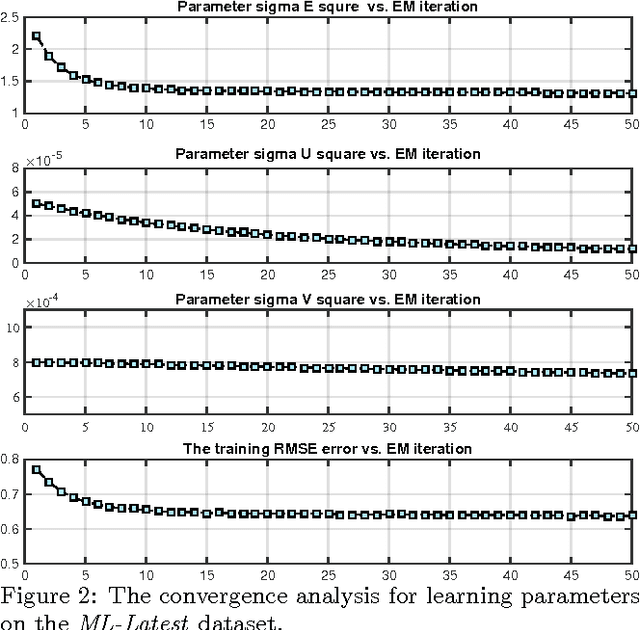
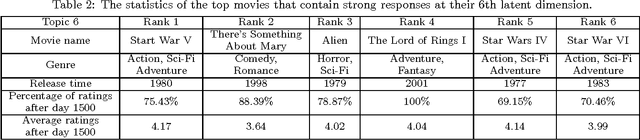
The increasing popularity of real-world recommender systems produces data continuously and rapidly, and it becomes more realistic to study recommender systems under streaming scenarios. Data streams present distinct properties such as temporally ordered, continuous and high-velocity, which poses tremendous challenges to traditional recommender systems. In this paper, we investigate the problem of recommendation with stream inputs. In particular, we provide a principled framework termed sRec, which provides explicit continuous-time random process models of the creation of users and topics, and of the evolution of their interests. A variational Bayesian approach called recursive meanfield approximation is proposed, which permits computationally efficient instantaneous on-line inference. Experimental results on several real-world datasets demonstrate the advantages of our sRec over other state-of-the-arts.