 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding The Ph(ysical)AI Layer Of Machine Intelligence
Jun 02, 2026Foundation models achieve generalization through massive-scale training on diverse data, but have limitations with transfer to truly unseen domains without paired training data. We propose principle-driven foundation models that encode signal-theoretic principles (Fourier decomposition, energy conservation, symmetry) rather than learn untethered statistical correlations. We hypothesize that domains differ not in fundamental physics, but in learnable transformations in time, frequency, magnitude, or phase. Training exclusively on radio-frequency (RF) data with co-designed architecture and losses incorporating these principles, we achieve cross-modal transfer to audio, images, text, and video using only frozen representations learned from RF data, requiring no fine-tuning of the encoder on target domains. Our 1.99M parameter frozen encoder achieves 77.7% average accuracy (91.9% top-3) across 15 diverse tasks via linear probing, with systematic variation: 84.5 on physically-grounded tasks (speaker recognition, seismology, RF fingerprinting) versus 70.0% on semantic tasks (music genre, language recognition). This reveals that principle-driven and scale-driven approaches offer complementary paths: physical principles enable efficient cross-modal transfer while naturally establishing the boundary between physical and semantic understanding.
From Snow to Rain: Evaluating Robustness, Calibration, and Complexity of Model-Based Robust Training
Jan 14, 2026Robustness to natural corruptions remains a critical challenge for reliable deep learning, particularly in safety-sensitive domains. We study a family of model-based training approaches that leverage a learned nuisance variation model to generate realistic corruptions, as well as new hybrid strategies that combine random coverage with adversarial refinement in nuisance space. Using the Challenging Unreal and Real Environments for Traffic Sign Recognition dataset (CURE-TSR), with Snow and Rain corruptions, we evaluate accuracy, calibration, and training complexity across corruption severities. Our results show that model-based methods consistently outperform baselines Vanilla, Adversarial Training, and AugMix baselines, with model-based adversarial training providing the strongest robustness under across all corruptions but at the expense of higher computation and model-based data augmentation achieving comparable robustness with $T$ less computational complexity without incurring a statistically significant drop in performance. These findings highlight the importance of learned nuisance models for capturing natural variability, and suggest a promising path toward more resilient and calibrated models under challenging conditions.
LoRAX: LoRA eXpandable Networks for Continual Synthetic Image Attribution
Apr 10, 2025As generative AI image technologies become more widespread and advanced, there is a growing need for strong attribution models. These models are crucial for verifying the authenticity of images and identifying the architecture of their originating generative models-key to maintaining media integrity. However, attribution models struggle to generalize to unseen models, and traditional fine-tuning methods for updating these models have shown to be impractical in real-world settings. To address these challenges, we propose LoRA eXpandable Networks (LoRAX), a parameter-efficient class incremental algorithm that adapts to novel generative image models without the need for full retraining. Our approach trains an extremely parameter-efficient feature extractor per continual learning task via Low Rank Adaptation. Each task-specific feature extractor learns distinct features while only requiring a small fraction of the parameters present in the underlying feature extractor's backbone model. Our extensive experimentation shows LoRAX outperforms or remains competitive with state-of-the-art class incremental learning algorithms on the Continual Deepfake Detection benchmark across all training scenarios and memory settings, while requiring less than 3% of the number of trainable parameters per feature extractor compared to the full-rank implementation. LoRAX code is available at: https://github.com/mit-ll/lorax_cil.
Meta-Learning and Self-Supervised Pretraining for Real World Image Translation
Dec 22, 2021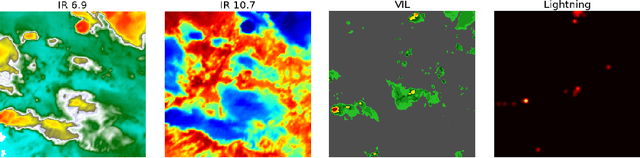
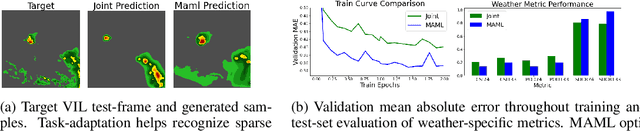
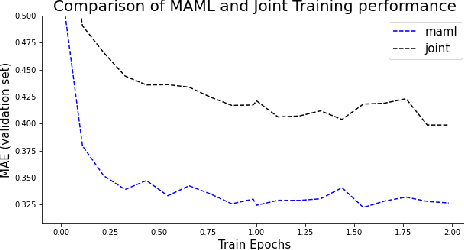
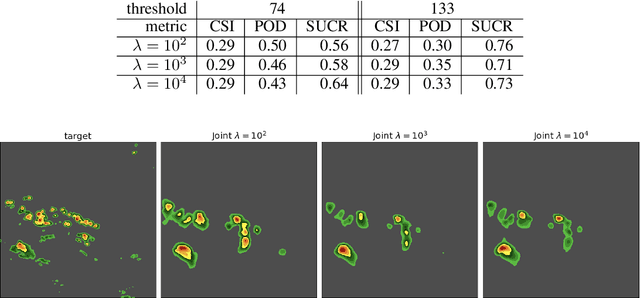
Recent advances in deep learning, in particular enabled by hardware advances and big data, have provided impressive results across a wide range of computational problems such as computer vision, natural language, or reinforcement learning. Many of these improvements are however constrained to problems with large-scale curated data-sets which require a lot of human labor to gather. Additionally, these models tend to generalize poorly under both slight distributional shifts and low-data regimes. In recent years, emerging fields such as meta-learning or self-supervised learning have been closing the gap between proof-of-concept results and real-life applications of machine learning by extending deep-learning to the semi-supervised and few-shot domains. We follow this line of work and explore spatio-temporal structure in a recently introduced image-to-image translation problem in order to: i) formulate a novel multi-task few-shot image generation benchmark and ii) explore data augmentations in contrastive pre-training for image translation downstream tasks. We present several baselines for the few-shot problem and discuss trade-offs between different approaches. Our code is available at https://github.com/irugina/meta-image-translation.
Fast Generation for Convolutional Autoregressive Models
Apr 20, 2017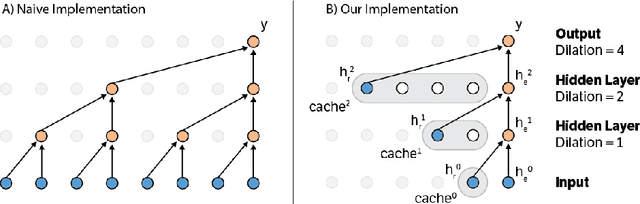
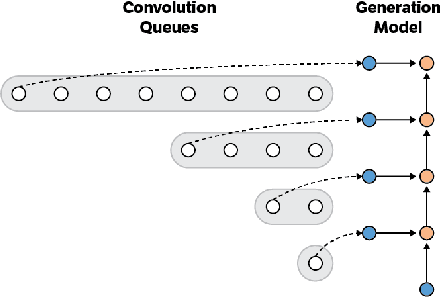
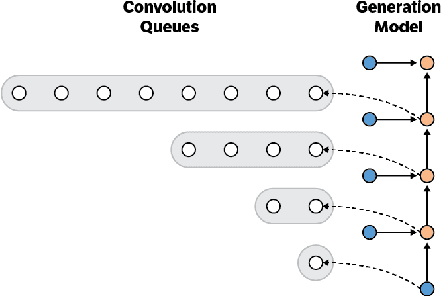
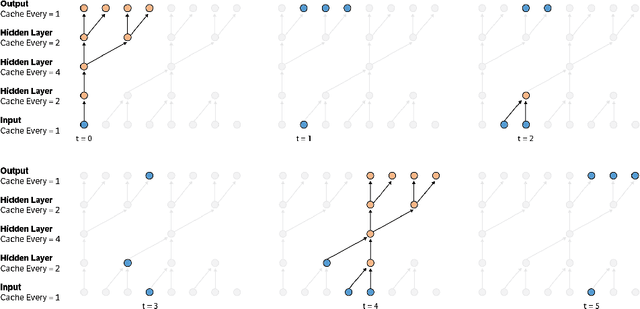
Convolutional autoregressive models have recently demonstrated state-of-the-art performance on a number of generation tasks. While fast, parallel training methods have been crucial for their success, generation is typically implemented in a na\"{i}ve fashion where redundant computations are unnecessarily repeated. This results in slow generation, making such models infeasible for production environments. In this work, we describe a method to speed up generation in convolutional autoregressive models. The key idea is to cache hidden states to avoid redundant computation. We apply our fast generation method to the Wavenet and PixelCNN++ models and achieve up to $21\times$ and $183\times$ speedups respectively.
Do Deep Neural Networks Learn Facial Action Units When Doing Expression Recognition?
Mar 16, 2017
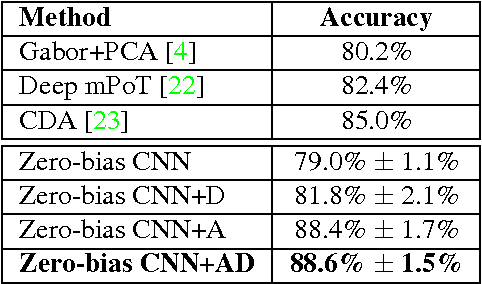
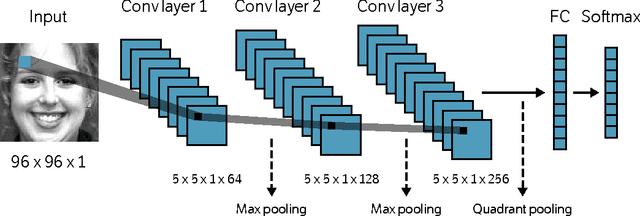
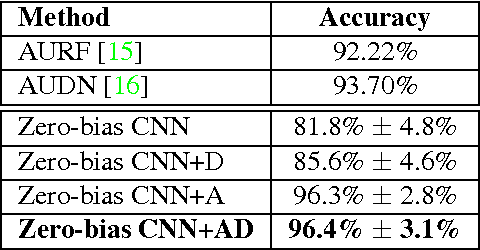
Despite being the appearance-based classifier of choice in recent years, relatively few works have examined how much convolutional neural networks (CNNs) can improve performance on accepted expression recognition benchmarks and, more importantly, examine what it is they actually learn. In this work, not only do we show that CNNs can achieve strong performance, but we also introduce an approach to decipher which portions of the face influence the CNN's predictions. First, we train a zero-bias CNN on facial expression data and achieve, to our knowledge, state-of-the-art performance on two expression recognition benchmarks: the extended Cohn-Kanade (CK+) dataset and the Toronto Face Dataset (TFD). We then qualitatively analyze the network by visualizing the spatial patterns that maximally excite different neurons in the convolutional layers and show how they resemble Facial Action Units (FAUs). Finally, we use the FAU labels provided in the CK+ dataset to verify that the FAUs observed in our filter visualizations indeed align with the subject's facial movements.
How Deep Neural Networks Can Improve Emotion Recognition on Video Data
Jan 10, 2017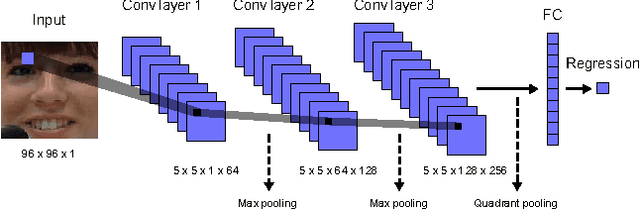
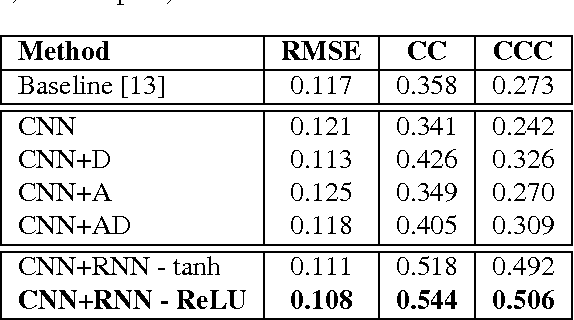
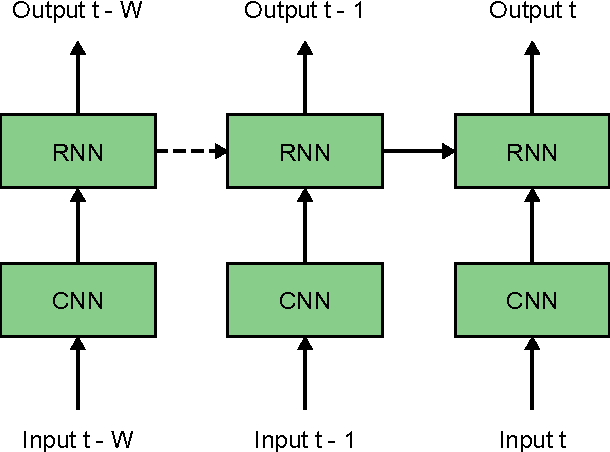
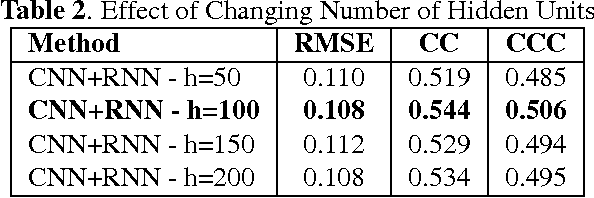
We consider the task of dimensional emotion recognition on video data using deep learning. While several previous methods have shown the benefits of training temporal neural network models such as recurrent neural networks (RNNs) on hand-crafted features, few works have considered combining convolutional neural networks (CNNs) with RNNs. In this work, we present a system that performs emotion recognition on video data using both CNNs and RNNs, and we also analyze how much each neural network component contributes to the system's overall performance. We present our findings on videos from the Audio/Visual+Emotion Challenge (AV+EC2015). In our experiments, we analyze the effects of several hyperparameters on overall performance while also achieving superior performance to the baseline and other competing methods.
Fast Wavenet Generation Algorithm
Nov 29, 2016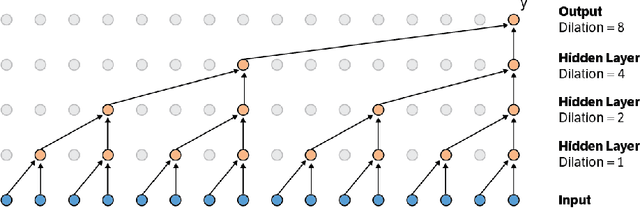
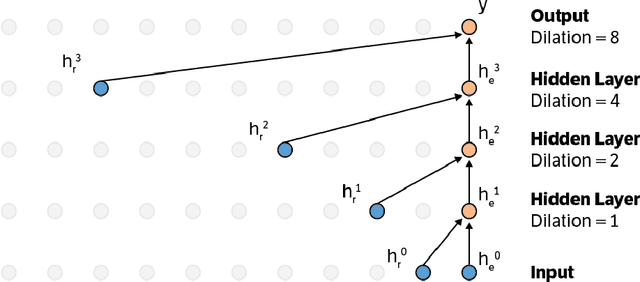
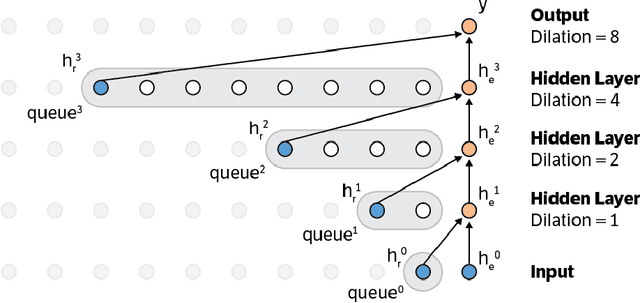
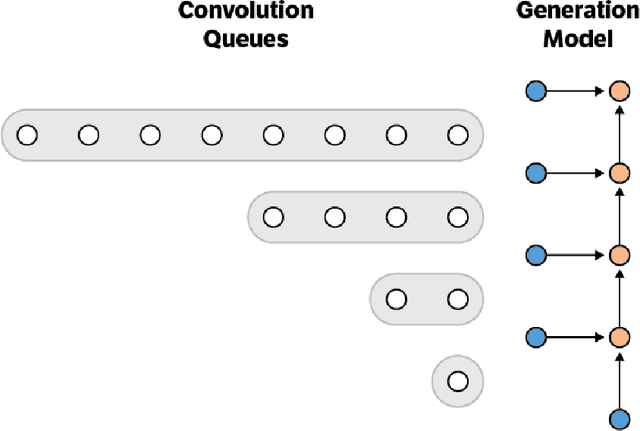
This paper presents an efficient implementation of the Wavenet generation process called Fast Wavenet. Compared to a naive implementation that has complexity O(2^L) (L denotes the number of layers in the network), our proposed approach removes redundant convolution operations by caching previous calculations, thereby reducing the complexity to O(L) time. Timing experiments show significant advantages of our fast implementation over a naive one. While this method is presented for Wavenet, the same scheme can be applied anytime one wants to perform autoregressive generation or online prediction using a model with dilated convolution layers. The code for our method is publicly available.
Seq-NMS for Video Object Detection
Aug 22, 2016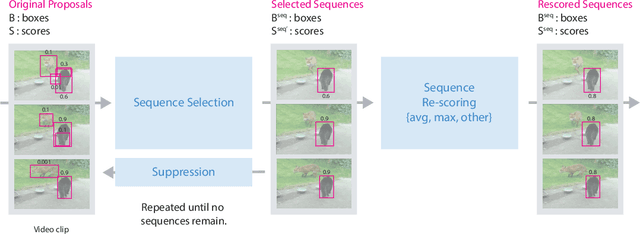
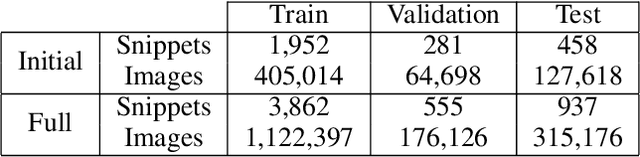
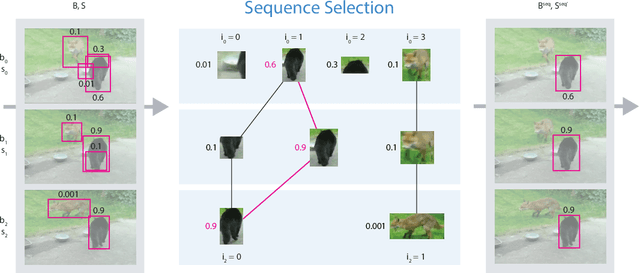

Video object detection is challenging because objects that are easily detected in one frame may be difficult to detect in another frame within the same clip. Recently, there have been major advances for doing object detection in a single image. These methods typically contain three phases: (i) object proposal generation (ii) object classification and (iii) post-processing. We propose a modification of the post-processing phase that uses high-scoring object detections from nearby frames to boost scores of weaker detections within the same clip. We show that our method obtains superior results to state-of-the-art single image object detection techniques. Our method placed 3rd in the video object detection (VID) task of the ImageNet Large Scale Visual Recognition Challenge 2015 (ILSVRC2015).
An Analysis of Unsupervised Pre-training in Light of Recent Advances
Apr 10, 2015

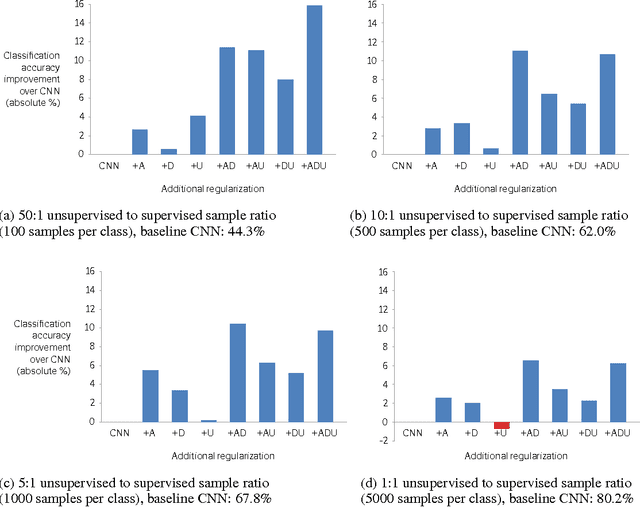

Convolutional neural networks perform well on object recognition because of a number of recent advances: rectified linear units (ReLUs), data augmentation, dropout, and large labelled datasets. Unsupervised data has been proposed as another way to improve performance. Unfortunately, unsupervised pre-training is not used by state-of-the-art methods leading to the following question: Is unsupervised pre-training still useful given recent advances? If so, when? We answer this in three parts: we 1) develop an unsupervised method that incorporates ReLUs and recent unsupervised regularization techniques, 2) analyze the benefits of unsupervised pre-training compared to data augmentation and dropout on CIFAR-10 while varying the ratio of unsupervised to supervised samples, 3) verify our findings on STL-10. We discover unsupervised pre-training, as expected, helps when the ratio of unsupervised to supervised samples is high, and surprisingly, hurts when the ratio is low. We also use unsupervised pre-training with additional color augmentation to achieve near state-of-the-art performance on STL-10.