 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Deep Neural Networks Learn Facial Action Units When Doing Expression Recognition?
Paper and Code

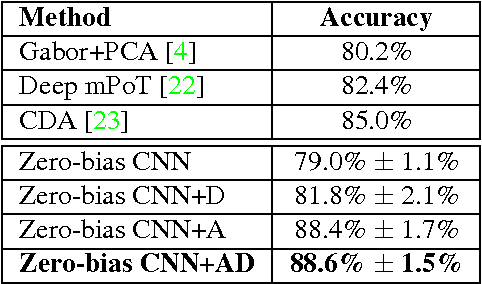
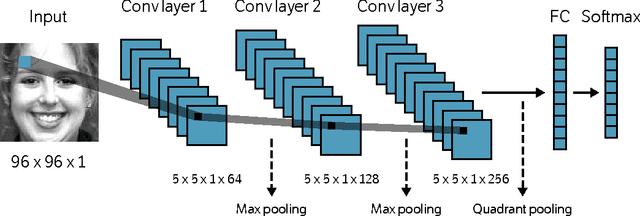
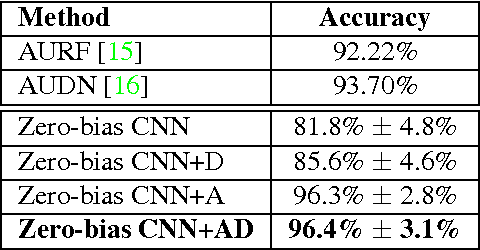
Despite being the appearance-based classifier of choice in recent years, relatively few works have examined how much convolutional neural networks (CNNs) can improve performance on accepted expression recognition benchmarks and, more importantly, examine what it is they actually learn. In this work, not only do we show that CNNs can achieve strong performance, but we also introduce an approach to decipher which portions of the face influence the CNN's predictions. First, we train a zero-bias CNN on facial expression data and achieve, to our knowledge, state-of-the-art performance on two expression recognition benchmarks: the extended Cohn-Kanade (CK+) dataset and the Toronto Face Dataset (TFD). We then qualitatively analyze the network by visualizing the spatial patterns that maximally excite different neurons in the convolutional layers and show how they resemble Facial Action Units (FAUs). Finally, we use the FAU labels provided in the CK+ dataset to verify that the FAUs observed in our filter visualizations indeed align with the subject's facial movements.