 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning and Self-Supervised Pretraining for Real World Image Translation
Paper and Code
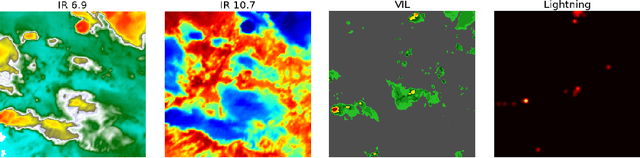
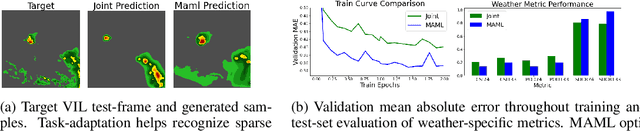
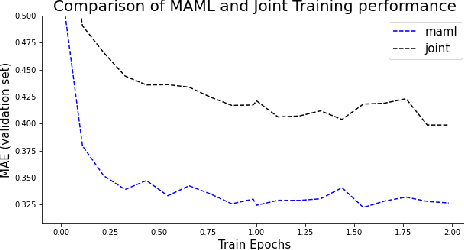
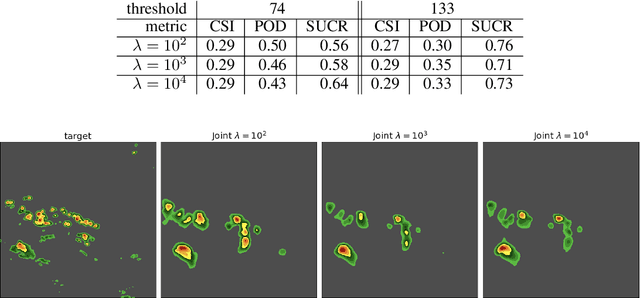
Recent advances in deep learning, in particular enabled by hardware advances and big data, have provided impressive results across a wide range of computational problems such as computer vision, natural language, or reinforcement learning. Many of these improvements are however constrained to problems with large-scale curated data-sets which require a lot of human labor to gather. Additionally, these models tend to generalize poorly under both slight distributional shifts and low-data regimes. In recent years, emerging fields such as meta-learning or self-supervised learning have been closing the gap between proof-of-concept results and real-life applications of machine learning by extending deep-learning to the semi-supervised and few-shot domains. We follow this line of work and explore spatio-temporal structure in a recently introduced image-to-image translation problem in order to: i) formulate a novel multi-task few-shot image generation benchmark and ii) explore data augmentations in contrastive pre-training for image translation downstream tasks. We present several baselines for the few-shot problem and discuss trade-offs between different approaches. Our code is available at https://github.com/irugina/meta-image-translation.