 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKanana: Compute-efficient Bilingual Language Models
Feb 26, 2025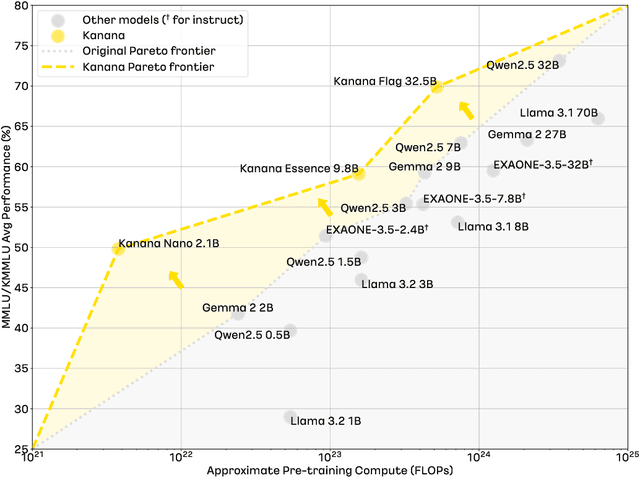



We introduce Kanana, a series of bilingual language models that demonstrate exceeding performance in Korean and competitive performance in English. The computational cost of Kanana is significantly lower than that of state-of-the-art models of similar size. The report details the techniques employed during pre-training to achieve compute-efficient yet competitive models, including high quality data filtering, staged pre-training, depth up-scaling, and pruning and distillation. Furthermore, the report outlines the methodologies utilized during the post-training of the Kanana models, encompassing supervised fine-tuning and preference optimization, aimed at enhancing their capability for seamless interaction with users. Lastly, the report elaborates on plausible approaches used for language model adaptation to specific scenarios, such as embedding, retrieval augmented generation, and function calling. The Kanana model series spans from 2.1B to 32.5B parameters with 2.1B models (base, instruct, embedding) publicly released to promote research on Korean language models.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Binary Classifier Optimization for Large Language Model Alignment
Apr 06, 2024



Aligning Large Language Models (LLMs) to human preferences through preference optimization has been crucial but labor-intensive, necessitating for each prompt a comparison of both a chosen and a rejected text completion by evaluators. Recently, Kahneman-Tversky Optimization (KTO) has demonstrated that LLMs can be aligned using merely binary "thumbs-up" or "thumbs-down" signals on each prompt-completion pair. In this paper, we present theoretical foundations to explain the successful alignment achieved through these binary signals. Our analysis uncovers a new perspective: optimizing a binary classifier, whose logit is a reward, implicitly induces minimizing the Direct Preference Optimization (DPO) loss. In the process of this discovery, we identified two techniques for effective alignment: reward shift and underlying distribution matching. Consequently, we propose a new algorithm, \textit{Binary Classifier Optimization}, that integrates the techniques. We validate our methodology in two settings: first, on a paired preference dataset, where our method performs on par with DPO and KTO; and second, on binary signal datasets simulating real-world conditions with divergent underlying distributions between thumbs-up and thumbs-down data. Our model consistently demonstrates effective and robust alignment across two base LLMs and three different binary signal datasets, showcasing the strength of our approach to learning from binary feedback.
Pivotal Role of Language Modeling in Recommender Systems: Enriching Task-specific and Task-agnostic Representation Learning
Dec 13, 2022



Recent studies have proposed unified user modeling frameworks that leverage user behavior data from various applications. Many of them benefit from utilizing users' behavior sequences as plain texts, representing rich information in any domain or system without losing generality. Hence, a question arises: Can language modeling for user history corpus help improve recommender systems? While its versatile usability has been widely investigated in many domains, its applications to recommender systems still remain underexplored. We show that language modeling applied directly to task-specific user histories achieves excellent results on diverse recommendation tasks. Also, leveraging additional task-agnostic user histories delivers significant performance benefits. We further demonstrate that our approach can provide promising transfer learning capabilities for a broad spectrum of real-world recommender systems, even on unseen domains and services.
Hazard Gradient Penalty for Survival Analysis
May 27, 2022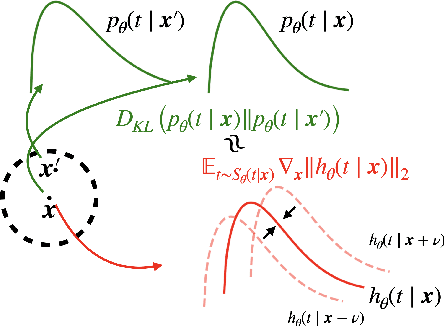

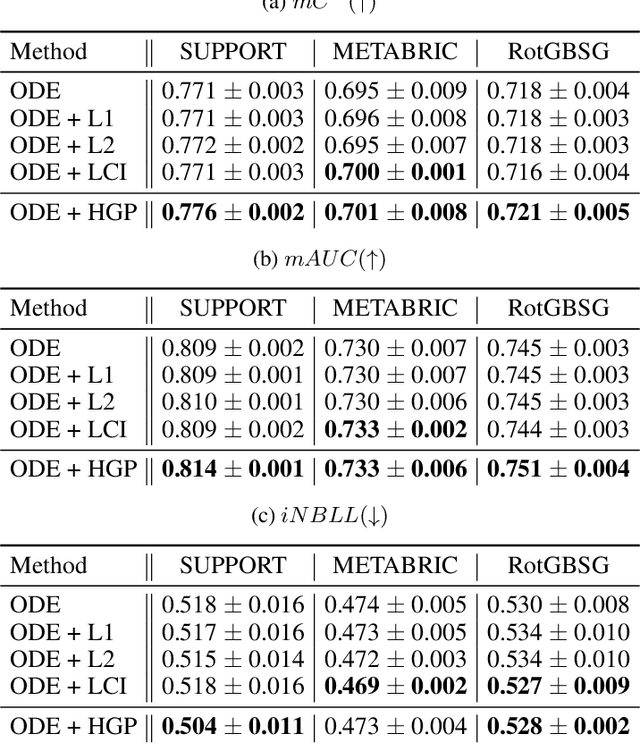
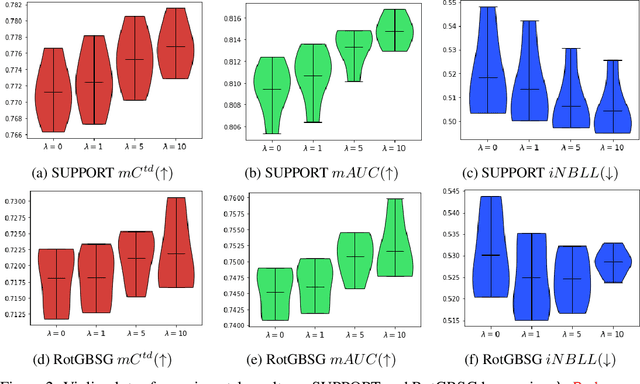
Survival analysis appears in various fields such as medicine, economics, engineering, and business. Recent studies showed that the Ordinary Differential Equation (ODE) modeling framework unifies many existing survival models while the framework is flexible and widely applicable. However, naively applying the ODE framework to survival analysis problems may model fiercely changing density function which may worsen the model's performance. Though we can apply L1 or L2 regularizers to the ODE model, their effect on the ODE modeling framework is barely known. In this paper, we propose hazard gradient penalty (HGP) to enhance the performance of a survival analysis model. Our method imposes constraints on local data points by regularizing the gradient of hazard function with respect to the data point. Our method applies to any survival analysis model including the ODE modeling framework and is easy to implement. We theoretically show that our method is related to minimizing the KL divergence between the density function at a data point and that of the neighborhood points. Experimental results on three public benchmarks show that our approach outperforms other regularization methods.
Global-Local Item Embedding for Temporal Set Prediction
Sep 05, 2021

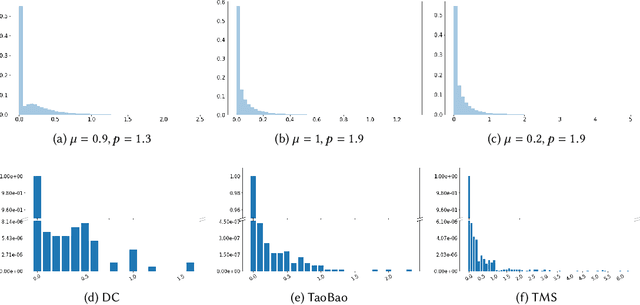
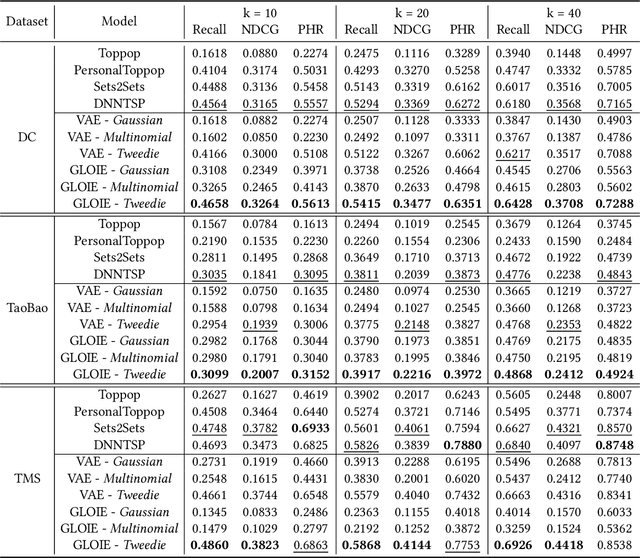
Temporal set prediction is becoming increasingly important as many companies employ recommender systems in their online businesses, e.g., personalized purchase prediction of shopping baskets. While most previous techniques have focused on leveraging a user's history, the study of combining it with others' histories remains untapped potential. This paper proposes Global-Local Item Embedding (GLOIE) that learns to utilize the temporal properties of sets across whole users as well as within a user by coining the names as global and local information to distinguish the two temporal patterns. GLOIE uses Variational Autoencoder (VAE) and dynamic graph-based model to capture global and local information and then applies attention to integrate resulting item embeddings. Additionally, we propose to use Tweedie output for the decoder of VAE as it can easily model zero-inflated and long-tailed distribution, which is more suitable for several real-world data distributions than Gaussian or multinomial counterparts. When evaluated on three public benchmarks, our algorithm consistently outperforms previous state-of-the-art methods in most ranking metrics.
One4all User Representation for Recommender Systems in E-commerce
May 24, 2021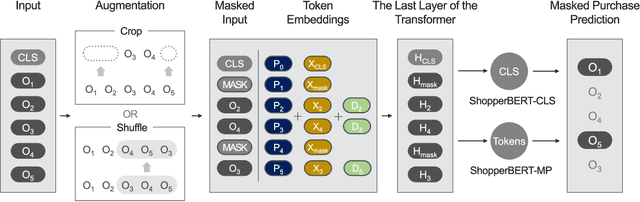

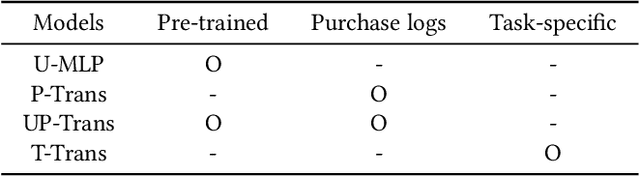
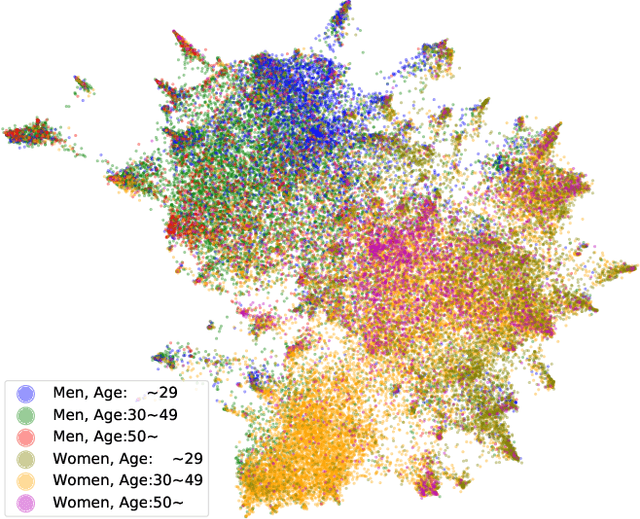
General-purpose representation learning through large-scale pre-training has shown promising results in the various machine learning fields. For an e-commerce domain, the objective of general-purpose, i.e., one for all, representations would be efficient applications for extensive downstream tasks such as user profiling, targeting, and recommendation tasks. In this paper, we systematically compare the generalizability of two learning strategies, i.e., transfer learning through the proposed model, ShopperBERT, vs. learning from scratch. ShopperBERT learns nine pretext tasks with 79.2M parameters from 0.8B user behaviors collected over two years to produce user embeddings. As a result, the MLPs that employ our embedding method outperform more complex models trained from scratch for five out of six tasks. Specifically, the pre-trained embeddings have superiority over the task-specific supervised features and the strong baselines, which learn the auxiliary dataset for the cold-start problem. We also show the computational efficiency and embedding visualization of the pre-trained features.
A Worrying Analysis of Probabilistic Time-series Models for Sales Forecasting
Nov 21, 2020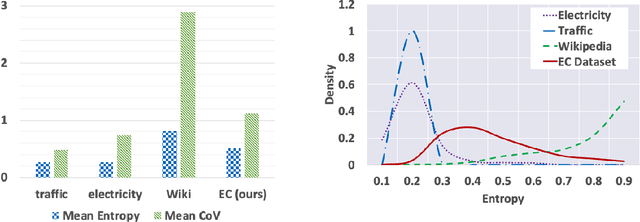
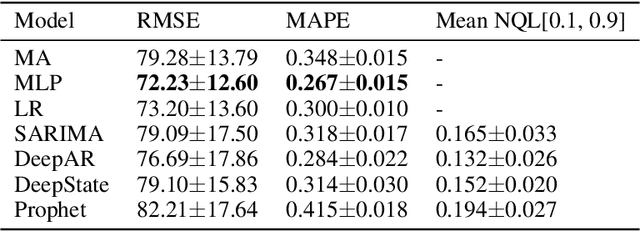
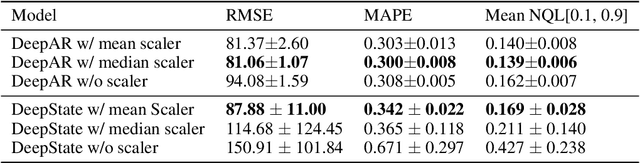

Probabilistic time-series models become popular in the forecasting field as they help to make optimal decisions under uncertainty. Despite the growing interest, a lack of thorough analysis hinders choosing what is worth applying for the desired task. In this paper, we analyze the performance of three prominent probabilistic time-series models for sales forecasting. To remove the role of random chance in architecture's performance, we make two experimental principles; 1) Large-scale dataset with various cross-validation sets. 2) A standardized training and hyperparameter selection. The experimental results show that a simple Multi-layer Perceptron and Linear Regression outperform the probabilistic models on RMSE without any feature engineering. Overall, the probabilistic models fail to achieve better performance on point estimation, such as RMSE and MAPE, than comparably simple baselines. We analyze and discuss the performances of probabilistic time-series models.
Encoder-Powered Generative Adversarial Networks
Jun 03, 2019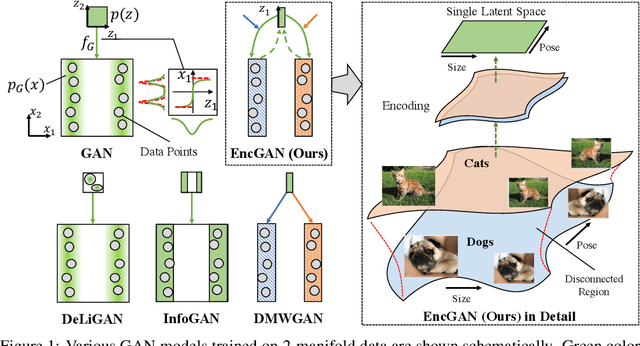
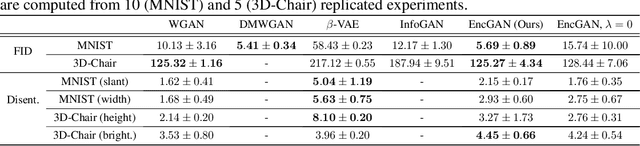
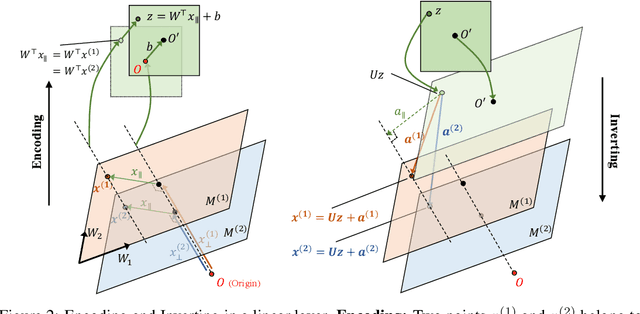
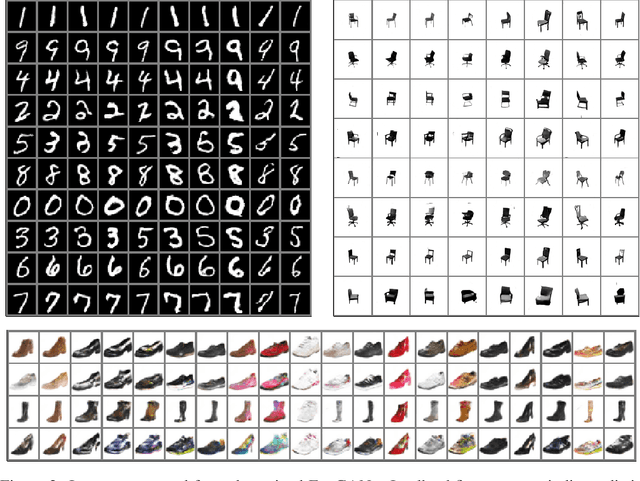
We present an encoder-powered generative adversarial network (EncGAN) that is able to learn both the multi-manifold structure and the abstract features of data. Unlike the conventional decoder-based GANs, EncGAN uses an encoder to model the manifold structure and invert the encoder to generate data. This unique scheme enables the proposed model to exclude discrete features from the smooth structure modeling and learn multi-manifold data without being hindered by the disconnections. Also, as EncGAN requires a single latent space to carry the information for all the manifolds, it builds abstract features shared among the manifolds in the latent space. For an efficient computation, we formulate EncGAN using a simple regularizer, and mathematically prove its validity. We also experimentally demonstrate that EncGAN successfully learns the multi-manifold structure and the abstract features of MNIST, 3D-chair and UT-Zap50k datasets. Our analysis shows that the learned abstract features are disentangled and make a good style-transfer even when the source data is off the trained distribution.