 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Recursive Reasoning
May 20, 2026How should future neural reasoning systems implement extended computation? Recursive Reasoning Models (RRMs) offer a promising alternative to autoregressive sequence extension by performing iterative latent-state refinement with shared transition functions. Yet existing RRMs are largely deterministic, following a single latent trajectory and converging to a single prediction. We introduce Generative Recursive reAsoning Models (GRAM), a framework that turns recursive latent reasoning into probabilistic multi-trajectory computation. GRAM models reasoning as a stochastic latent trajectory, enabling multiple hypotheses, alternative solution strategies, and inference-time scaling through both recursive depth and parallel trajectory sampling. This yields a latent-variable generative model supporting conditional reasoning via $p_θ(y \mid x)$ and, with fixed or absent inputs, unconditional generation via $p_θ(x)$. Trained with amortized variational inference, GRAM improves over deterministic recurrent and recursive baselines on structured reasoning and multi-solution constraint satisfaction tasks, while demonstrating an unconditional generation capability. https://ahn-ml.github.io/gram-website
Learning to Theorize the World from Observation
May 05, 2026What does it mean to understand the world? Contemporary world models often operationalize understanding as accurate future prediction in latent or observation space. Developmental cognitive science, however, suggests a different view: human understanding emerges through the construction of internal theories of how the world works, even before mature language is acquired. Inspired by this theory-building view of cognition, we introduce Learning-to-Theorize, a learning paradigm for inferring explicit explanatory theories of the world from raw, non-textual observations. We instantiate this paradigm with the Neural Theorizer (NEO), a probabilistic neural model that induces latent programs as a learned Language of Thought and executes them through a shared transition model. In NEO, a theory is represented as an executable, compositional program whose learned primitives can be systematically recombined to explain novel phenomena. Experiments show that this formulation enables explanation-driven generalization, allowing observations to be understood in terms of the programs that generate them.
Discrete JEPA: Learning Discrete Token Representations without Reconstruction
Jun 17, 2025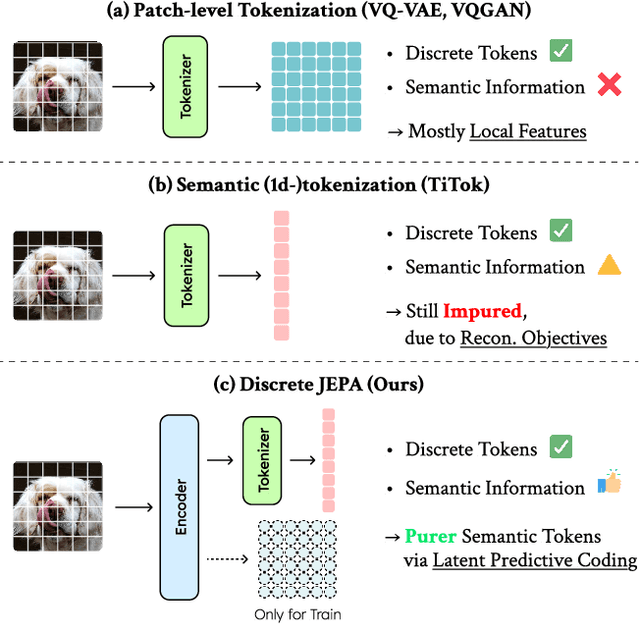
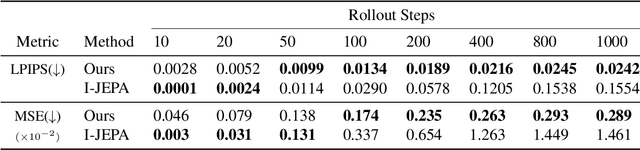
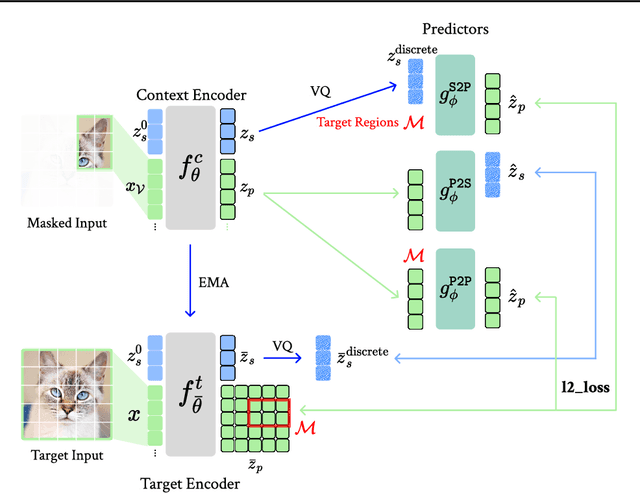
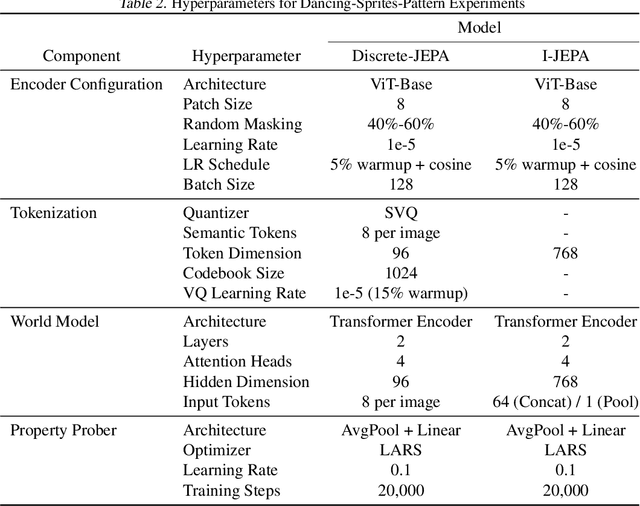
The cornerstone of cognitive intelligence lies in extracting hidden patterns from observations and leveraging these principles to systematically predict future outcomes. However, current image tokenization methods demonstrate significant limitations in tasks requiring symbolic abstraction and logical reasoning capabilities essential for systematic inference. To address this challenge, we propose Discrete-JEPA, extending the latent predictive coding framework with semantic tokenization and novel complementary objectives to create robust tokenization for symbolic reasoning tasks. Discrete-JEPA dramatically outperforms baselines on visual symbolic prediction tasks, while striking visual evidence reveals the spontaneous emergence of deliberate systematic patterns within the learned semantic token space. Though an initial model, our approach promises a significant impact for advancing Symbolic world modeling and planning capabilities in artificial intelligence systems.
Slot-MLLM: Object-Centric Visual Tokenization for Multimodal LLM
May 26, 2025Recently, multimodal large language models (MLLMs) have emerged as a key approach in achieving artificial general intelligence. In particular, vision-language MLLMs have been developed to generate not only text but also visual outputs from multimodal inputs. This advancement requires efficient image tokens that LLMs can process effectively both in input and output. However, existing image tokenization methods for MLLMs typically capture only global abstract concepts or uniformly segmented image patches, restricting MLLMs' capability to effectively understand or generate detailed visual content, particularly at the object level. To address this limitation, we propose an object-centric visual tokenizer based on Slot Attention specifically for MLLMs. In particular, based on the Q-Former encoder, diffusion decoder, and residual vector quantization, our proposed discretized slot tokens can encode local visual details while maintaining high-level semantics, and also align with textual data to be integrated seamlessly within a unified next-token prediction framework of LLMs. The resulting Slot-MLLM demonstrates significant performance improvements over baselines with previous visual tokenizers across various vision-language tasks that entail local detailed comprehension and generation. Notably, this work is the first demonstration of the feasibility of object-centric slot attention performed with MLLMs and in-the-wild natural images.
Dreamweaver: Learning Compositional World Representations from Pixels
Jan 24, 2025



Humans have an innate ability to decompose their perceptions of the world into objects and their attributes, such as colors, shapes, and movement patterns. This cognitive process enables us to imagine novel futures by recombining familiar concepts. However, replicating this ability in artificial intelligence systems has proven challenging, particularly when it comes to modeling videos into compositional concepts and generating unseen, recomposed futures without relying on auxiliary data, such as text, masks, or bounding boxes. In this paper, we propose Dreamweaver, a neural architecture designed to discover hierarchical and compositional representations from raw videos and generate compositional future simulations. Our approach leverages a novel Recurrent Block-Slot Unit (RBSU) to decompose videos into their constituent objects and attributes. In addition, Dreamweaver uses a multi-future-frame prediction objective to capture disentangled representations for dynamic concepts more effectively as well as static concepts. In experiments, we demonstrate our model outperforms current state-of-the-art baselines for world modeling when evaluated under the DCI framework across multiple datasets. Furthermore, we show how the modularized concept representations of our model enable compositional imagination, allowing the generation of novel videos by recombining attributes from different objects.
PlanDQ: Hierarchical Plan Orchestration via D-Conductor and Q-Performer
Jun 10, 2024
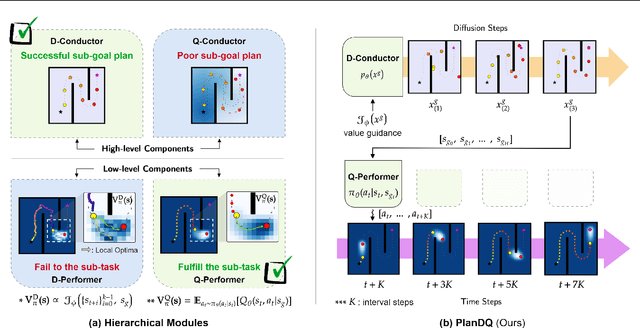
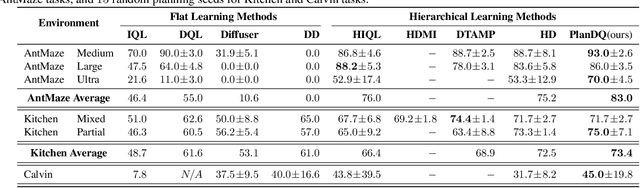
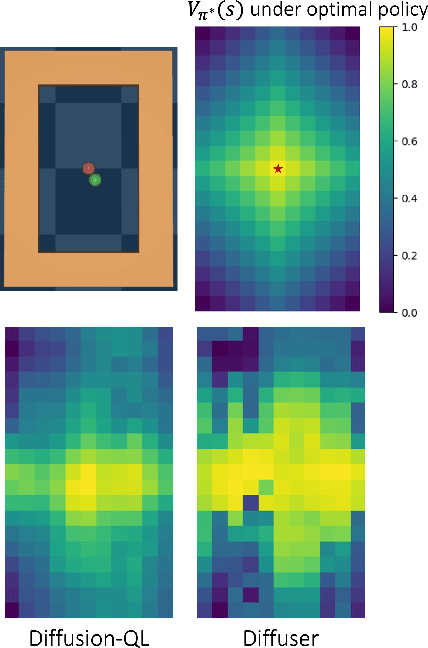
Despite the recent advancements in offline RL, no unified algorithm could achieve superior performance across a broad range of tasks. Offline \textit{value function learning}, in particular, struggles with sparse-reward, long-horizon tasks due to the difficulty of solving credit assignment and extrapolation errors that accumulates as the horizon of the task grows.~On the other hand, models that can perform well in long-horizon tasks are designed specifically for goal-conditioned tasks, which commonly perform worse than value function learning methods on short-horizon, dense-reward scenarios. To bridge this gap, we propose a hierarchical planner designed for offline RL called PlanDQ. PlanDQ incorporates a diffusion-based planner at the high level, named D-Conductor, which guides the low-level policy through sub-goals. At the low level, we used a Q-learning based approach called the Q-Performer to accomplish these sub-goals. Our experimental results suggest that PlanDQ can achieve superior or competitive performance on D4RL continuous control benchmark tasks as well as AntMaze, Kitchen, and Calvin as long-horizon tasks.