 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanDQ: Hierarchical Plan Orchestration via D-Conductor and Q-Performer
Paper and Code
Jun 10, 2024
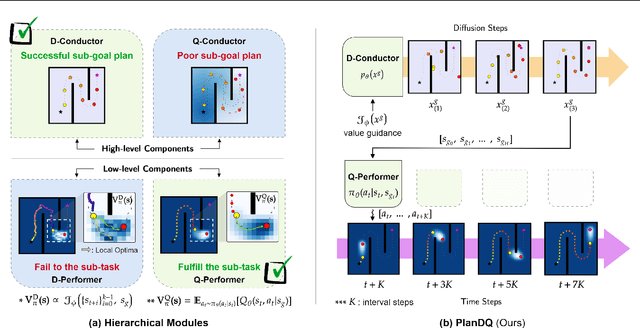
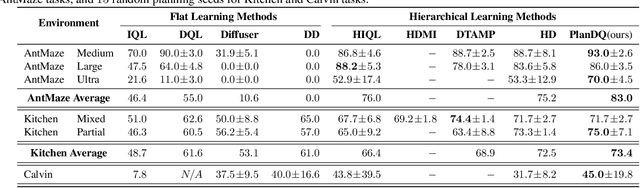
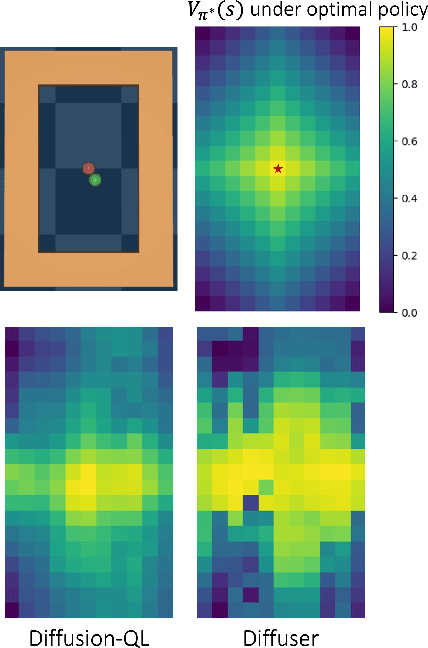
Despite the recent advancements in offline RL, no unified algorithm could achieve superior performance across a broad range of tasks. Offline \textit{value function learning}, in particular, struggles with sparse-reward, long-horizon tasks due to the difficulty of solving credit assignment and extrapolation errors that accumulates as the horizon of the task grows.~On the other hand, models that can perform well in long-horizon tasks are designed specifically for goal-conditioned tasks, which commonly perform worse than value function learning methods on short-horizon, dense-reward scenarios. To bridge this gap, we propose a hierarchical planner designed for offline RL called PlanDQ. PlanDQ incorporates a diffusion-based planner at the high level, named D-Conductor, which guides the low-level policy through sub-goals. At the low level, we used a Q-learning based approach called the Q-Performer to accomplish these sub-goals. Our experimental results suggest that PlanDQ can achieve superior or competitive performance on D4RL continuous control benchmark tasks as well as AntMaze, Kitchen, and Calvin as long-horizon tasks.