 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Discovery in Action: Learning Chain-Reaction Mechanisms from Interventions
Mar 23, 2026Causal discovery is challenging in general dynamical systems because, without strong structural assumptions, the underlying causal graph may not be identifiable even from interventional data. However, many real-world systems exhibit directional, cascade-like structure, in which components activate sequentially and upstream failures suppress downstream effects. We study causal discovery in such chain-reaction systems and show that the causal structure is uniquely identifiable from blocking interventions that prevent individual components from activating. We propose a minimal estimator with finite-sample guarantees, achieving exponential error decay and logarithmic sample complexity. Experiments on synthetic models and diverse chain-reaction environments demonstrate reliable recovery from a few interventions, while observational heuristics fail in regimes with delayed or overlapping causal effects.
Approximating Shapley Explanations in Reinforcement Learning
Nov 08, 2025Reinforcement learning has achieved remarkable success in complex decision-making environments, yet its lack of transparency limits its deployment in practice, especially in safety-critical settings. Shapley values from cooperative game theory provide a principled framework for explaining reinforcement learning; however, the computational cost of Shapley explanations is an obstacle to their use. We introduce FastSVERL, a scalable method for explaining reinforcement learning by approximating Shapley values. FastSVERL is designed to handle the unique challenges of reinforcement learning, including temporal dependencies across multi-step trajectories, learning from off-policy data, and adapting to evolving agent behaviours in real time. FastSVERL introduces a practical, scalable approach for principled and rigorous interpretability in reinforcement learning.
* Camera-ready version. Published at the Conference on Neural Information Processing Systems (NeurIPS 2025)
Position: Causal Machine Learning Requires Rigorous Synthetic Experiments for Broader Adoption
Aug 12, 2025Causal machine learning has the potential to revolutionize decision-making by combining the predictive power of machine learning algorithms with the theory of causal inference. However, these methods remain underutilized by the broader machine learning community, in part because current empirical evaluations do not permit assessment of their reliability and robustness, undermining their practical utility. Specifically, one of the principal criticisms made by the community is the extensive use of synthetic experiments. We argue, on the contrary, that synthetic experiments are essential and necessary to precisely assess and understand the capabilities of causal machine learning methods. To substantiate our position, we critically review the current evaluation practices, spotlight their shortcomings, and propose a set of principles for conducting rigorous empirical analyses with synthetic data. Adopting the proposed principles will enable comprehensive evaluations that build trust in causal machine learning methods, driving their broader adoption and impactful real-world use.
Learning The Minimum Action Distance
Jun 10, 2025This paper presents a state representation framework for Markov decision processes (MDPs) that can be learned solely from state trajectories, requiring neither reward signals nor the actions executed by the agent. We propose learning the minimum action distance (MAD), defined as the minimum number of actions required to transition between states, as a fundamental metric that captures the underlying structure of an environment. MAD naturally enables critical downstream tasks such as goal-conditioned reinforcement learning and reward shaping by providing a dense, geometrically meaningful measure of progress. Our self-supervised learning approach constructs an embedding space where the distances between embedded state pairs correspond to their MAD, accommodating both symmetric and asymmetric approximations. We evaluate the framework on a comprehensive suite of environments with known MAD values, encompassing both deterministic and stochastic dynamics, as well as discrete and continuous state spaces, and environments with noisy observations. Empirical results demonstrate that the proposed approach not only efficiently learns accurate MAD representations across these diverse settings but also significantly outperforms existing state representation methods in terms of representation quality.
A Theoretical Framework for Explaining Reinforcement Learning with Shapley Values
May 12, 2025Reinforcement learning agents can achieve superhuman performance, but their decisions are often difficult to interpret. This lack of transparency limits deployment, especially in safety-critical settings where human trust and accountability are essential. In this work, we develop a theoretical framework for explaining reinforcement learning through the influence of state features, which represent what the agent observes in its environment. We identify three core elements of the agent-environment interaction that benefit from explanation: behaviour (what the agent does), performance (what the agent achieves), and value estimation (what the agent expects to achieve). We treat state features as players cooperating to produce each element and apply Shapley values, a principled method from cooperative game theory, to identify the influence of each feature. This approach yields a family of mathematically grounded explanations with clear semantics and theoretical guarantees. We use illustrative examples to show how these explanations align with human intuition and reveal novel insights. Our framework unifies and extends prior work, making explicit the assumptions behind existing approaches, and offers a principled foundation for more interpretable and trustworthy reinforcement learning.
Curricula for Learning Robust Policies with Factored State Representations in Changing Environments
Sep 19, 2024

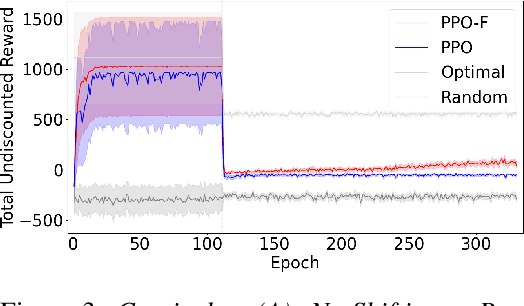

Robust policies enable reinforcement learning agents to effectively adapt to and operate in unpredictable, dynamic, and ever-changing real-world environments. Factored representations, which break down complex state and action spaces into distinct components, can improve generalization and sample efficiency in policy learning. In this paper, we explore how the curriculum of an agent using a factored state representation affects the robustness of the learned policy. We experimentally demonstrate three simple curricula, such as varying only the variable of highest regret between episodes, that can significantly enhance policy robustness, offering practical insights for reinforcement learning in complex environments.
Curricula for Learning Robust Policies over Factored State Representations in Changing Environments
Sep 13, 2024Robust policies enable reinforcement learning agents to effectively adapt to and operate in unpredictable, dynamic, and ever-changing real-world environments. Factored representations, which break down complex state and action spaces into distinct components, can improve generalization and sample efficiency in policy learning. In this paper, we explore how the curriculum of an agent using a factored state representation affects the robustness of the learned policy. We experimentally demonstrate three simple curricula, such as varying only the variable of highest regret between episodes, that can significantly enhance policy robustness, offering practical insights for reinforcement learning in complex environments.
Interpretability in Action: Exploratory Analysis of VPT, a Minecraft Agent
Jul 16, 2024



Understanding the mechanisms behind decisions taken by large foundation models in sequential decision making tasks is critical to ensuring that such systems operate transparently and safely. In this work, we perform exploratory analysis on the Video PreTraining (VPT) Minecraft playing agent, one of the largest open-source vision-based agents. We aim to illuminate its reasoning mechanisms by applying various interpretability techniques. First, we analyze the attention mechanism while the agent solves its training task - crafting a diamond pickaxe. The agent pays attention to the last four frames and several key-frames further back in its six-second memory. This is a possible mechanism for maintaining coherence in a task that takes 3-10 minutes, despite the short memory span. Secondly, we perform various interventions, which help us uncover a worrying case of goal misgeneralization: VPT mistakenly identifies a villager wearing brown clothes as a tree trunk when the villager is positioned stationary under green tree leaves, and punches it to death.
Colour versus Shape Goal Misgeneralization in Reinforcement Learning: A Case Study
Dec 05, 2023We explore colour versus shape goal misgeneralization originally demonstrated by Di Langosco et al. (2022) in the Procgen Maze environment, where, given an ambiguous choice, the agents seem to prefer generalization based on colour rather than shape. After training over 1,000 agents in a simplified version of the environment and evaluating them on over 10 million episodes, we conclude that the behaviour can be attributed to the agents learning to detect the goal object through a specific colour channel. This choice is arbitrary. Additionally, we show how, due to underspecification, the preferences can change when retraining the agents using exactly the same procedure except for using a different random seed for the training run. Finally, we demonstrate the existence of outliers in out-of-distribution behaviour based on training random seed alone.
Creating Multi-Level Skill Hierarchies in Reinforcement Learning
Jun 16, 2023



What is a useful skill hierarchy for an autonomous agent? We propose an answer based on the graphical structure of an agent's interaction with its environment. Our approach uses hierarchical graph partitioning to expose the structure of the graph at varying timescales, producing a skill hierarchy with multiple levels of abstraction. At each level of the hierarchy, skills move the agent between regions of the state space that are well connected within themselves but weakly connected to each other. We illustrate the utility of the proposed skill hierarchy in a wide variety of domains in the context of reinforcement learning.