Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurricula for Learning Robust Policies over Factored State Representations in Changing Environments
Paper and Code
Sep 13, 2024

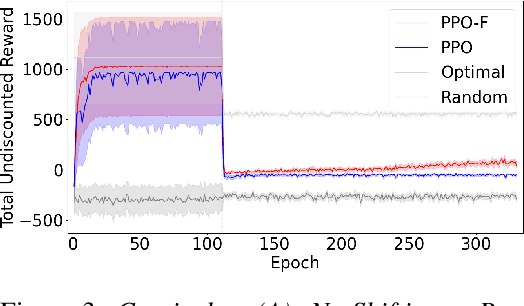

Robust policies enable reinforcement learning agents to effectively adapt to and operate in unpredictable, dynamic, and ever-changing real-world environments. Factored representations, which break down complex state and action spaces into distinct components, can improve generalization and sample efficiency in policy learning. In this paper, we explore how the curriculum of an agent using a factored state representation affects the robustness of the learned policy. We experimentally demonstrate three simple curricula, such as varying only the variable of highest regret between episodes, that can significantly enhance policy robustness, offering practical insights for reinforcement learning in complex environments.
* 17th European Workshop on Reinforcement Learning (EWRL 2024)
View paper on