 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Regularized Natural Gradients
Jan 26, 2026Gradient regularization (GR) has been shown to improve the generalizability of trained models. While Natural Gradient Descent has been shown to accelerate optimization in the initial phase of training, little attention has been paid to how the training dynamics of second-order optimizers can benefit from GR. In this work, we propose Gradient-Regularized Natural Gradients (GRNG), a family of scalable second-order optimizers that integrate explicit gradient regularization with natural gradient updates. Our framework provides two complementary algorithms: a frequentist variant that avoids explicit inversion of the Fisher Information Matrix (FIM) via structured approximations, and a Bayesian variant based on a Regularized-Kalman formulation that eliminates the need for FIM inversion entirely. We establish convergence guarantees for GRNG, showing that gradient regularization improves stability and enables convergence to global minima. Empirically, we demonstrate that GRNG consistently enhances both optimization speed and generalization compared to first-order methods (SGD, AdamW) and second-order baselines (K-FAC, Sophia), with strong results on vision and language benchmarks. Our findings highlight gradient regularization as a principled and practical tool to unlock the robustness of natural gradient methods for large-scale deep learning.
Rank-1 Approximation of Inverse Fisher for Natural Policy Gradients in Deep Reinforcement Learning
Jan 26, 2026Natural gradients have long been studied in deep reinforcement learning due to their fast convergence properties and covariant weight updates. However, computing natural gradients requires inversion of the Fisher Information Matrix (FIM) at each iteration, which is computationally prohibitive in nature. In this paper, we present an efficient and scalable natural policy optimization technique that leverages a rank-1 approximation to full inverse-FIM. We theoretically show that under certain conditions, a rank-1 approximation to inverse-FIM converges faster than policy gradients and, under some conditions, enjoys the same sample complexity as stochastic policy gradient methods. We benchmark our method on a diverse set of environments and show that it achieves superior performance to standard actor-critic and trust-region baselines.
Softly Constrained Denoisers for Diffusion Models
Dec 20, 2025
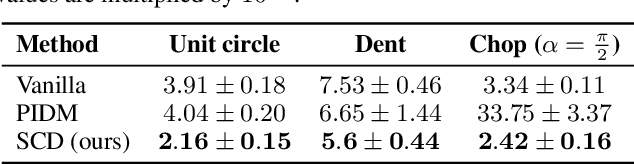
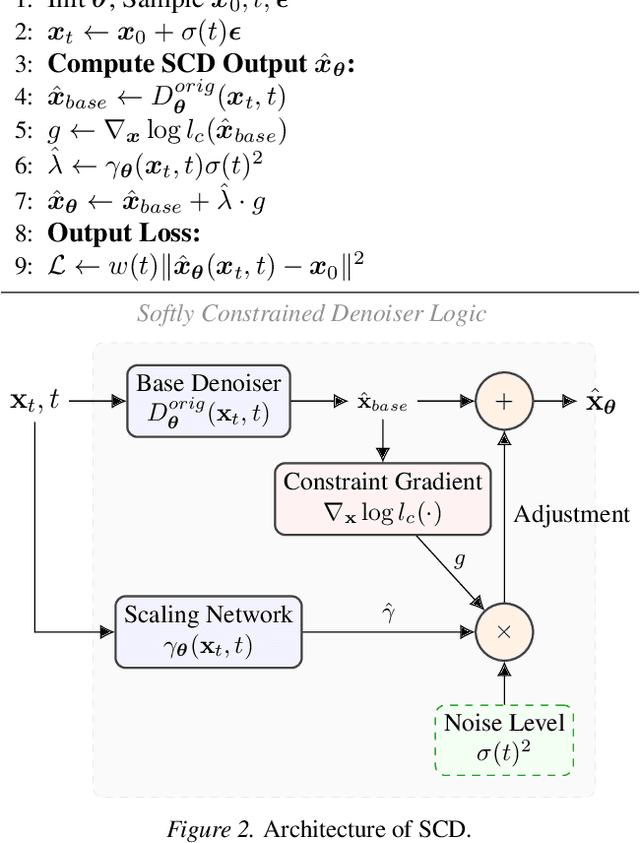

Diffusion models struggle to produce samples that respect constraints, a common requirement in scientific applications. Recent approaches have introduced regularization terms in the loss or guidance methods during sampling to enforce such constraints, but they bias the generative model away from the true data distribution. This is a problem, especially when the constraint is misspecified, a common issue when formulating constraints on scientific data. In this paper, instead of changing the loss or the sampling loop, we integrate a guidance-inspired adjustment into the denoiser itself, giving it a soft inductive bias towards constraint-compliant samples. We show that these softly constrained denoisers exploit constraint knowledge to improve compliance over standard denoisers, and maintain enough flexibility to deviate from it when there is misspecification with observed data.
From Grunts to Grammar: Emergent Language from Cooperative Foraging
May 19, 2025Early cavemen relied on gestures, vocalizations, and simple signals to coordinate, plan, avoid predators, and share resources. Today, humans collaborate using complex languages to achieve remarkable results. What drives this evolution in communication? How does language emerge, adapt, and become vital for teamwork? Understanding the origins of language remains a challenge. A leading hypothesis in linguistics and anthropology posits that language evolved to meet the ecological and social demands of early human cooperation. Language did not arise in isolation, but through shared survival goals. Inspired by this view, we investigate the emergence of language in multi-agent Foraging Games. These environments are designed to reflect the cognitive and ecological constraints believed to have influenced the evolution of communication. Agents operate in a shared grid world with only partial knowledge about other agents and the environment, and must coordinate to complete games like picking up high-value targets or executing temporally ordered actions. Using end-to-end deep reinforcement learning, agents learn both actions and communication strategies from scratch. We find that agents develop communication protocols with hallmark features of natural language: arbitrariness, interchangeability, displacement, cultural transmission, and compositionality. We quantify each property and analyze how different factors, such as population size and temporal dependencies, shape specific aspects of the emergent language. Our framework serves as a platform for studying how language can evolve from partial observability, temporal reasoning, and cooperative goals in embodied multi-agent settings. We will release all data, code, and models publicly.
Reinforcement Learning (RL) Meets Urban Climate Modeling: Investigating the Efficacy and Impacts of RL-Based HVAC Control
May 11, 2025Reinforcement learning (RL)-based heating, ventilation, and air conditioning (HVAC) control has emerged as a promising technology for reducing building energy consumption while maintaining indoor thermal comfort. However, the efficacy of such strategies is influenced by the background climate and their implementation may potentially alter both the indoor climate and local urban climate. This study proposes an integrated framework combining RL with an urban climate model that incorporates a building energy model, aiming to evaluate the efficacy of RL-based HVAC control across different background climates, impacts of RL strategies on indoor climate and local urban climate, and the transferability of RL strategies across cities. Our findings reveal that the reward (defined as a weighted combination of energy consumption and thermal comfort) and the impacts of RL strategies on indoor climate and local urban climate exhibit marked variability across cities with different background climates. The sensitivity of reward weights and the transferability of RL strategies are also strongly influenced by the background climate. Cities in hot climates tend to achieve higher rewards across most reward weight configurations that balance energy consumption and thermal comfort, and those cities with more varying atmospheric temperatures demonstrate greater RL strategy transferability. These findings underscore the importance of thoroughly evaluating RL-based HVAC control strategies in diverse climatic contexts. This study also provides a new insight that city-to-city learning will potentially aid the deployment of RL-based HVAC control.
Low-Rank Agent-Specific Adaptation (LoRASA) for Multi-Agent Policy Learning
Feb 08, 2025Multi-agent reinforcement learning (MARL) often relies on \emph{parameter sharing (PS)} to scale efficiently. However, purely shared policies can stifle each agent's unique specialization, reducing overall performance in heterogeneous environments. We propose \textbf{Low-Rank Agent-Specific Adaptation (LoRASA)}, a novel approach that treats each agent's policy as a specialized ``task'' fine-tuned from a shared backbone. Drawing inspiration from parameter-efficient transfer methods, LoRASA appends small, low-rank adaptation matrices to each layer of the shared policy, naturally inducing \emph{parameter-space sparsity} that promotes both specialization and scalability. We evaluate LoRASA on challenging benchmarks including the StarCraft Multi-Agent Challenge (SMAC) and Multi-Agent MuJoCo (MAMuJoCo), implementing it atop widely used algorithms such as MAPPO and A2PO. Across diverse tasks, LoRASA matches or outperforms existing baselines \emph{while reducing memory and computational overhead}. Ablation studies on adapter rank, placement, and timing validate the method's flexibility and efficiency. Our results suggest LoRASA's potential to establish a new norm for MARL policy parameterization: combining a shared foundation for coordination with low-rank agent-specific refinements for individual specialization.
$TAR^2$: Temporal-Agent Reward Redistribution for Optimal Policy Preservation in Multi-Agent Reinforcement Learning
Feb 07, 2025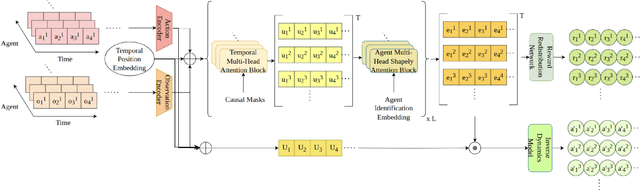

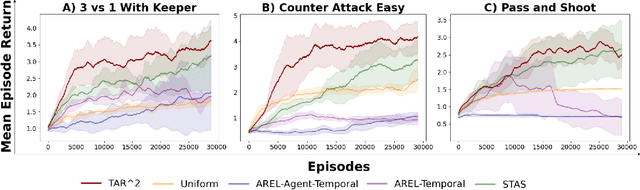

In cooperative multi-agent reinforcement learning (MARL), learning effective policies is challenging when global rewards are sparse and delayed. This difficulty arises from the need to assign credit across both agents and time steps, a problem that existing methods often fail to address in episodic, long-horizon tasks. We propose Temporal-Agent Reward Redistribution $TAR^2$, a novel approach that decomposes sparse global rewards into agent-specific, time-step-specific components, thereby providing more frequent and accurate feedback for policy learning. Theoretically, we show that $TAR^2$ (i) aligns with potential-based reward shaping, preserving the same optimal policies as the original environment, and (ii) maintains policy gradient update directions identical to those under the original sparse reward, ensuring unbiased credit signals. Empirical results on two challenging benchmarks, SMACLite and Google Research Football, demonstrate that $TAR^2$ significantly stabilizes and accelerates convergence, outperforming strong baselines like AREL and STAS in both learning speed and final performance. These findings establish $TAR^2$ as a principled and practical solution for agent-temporal credit assignment in sparse-reward multi-agent systems.
Agent-Temporal Credit Assignment for Optimal Policy Preservation in Sparse Multi-Agent Reinforcement Learning
Dec 19, 2024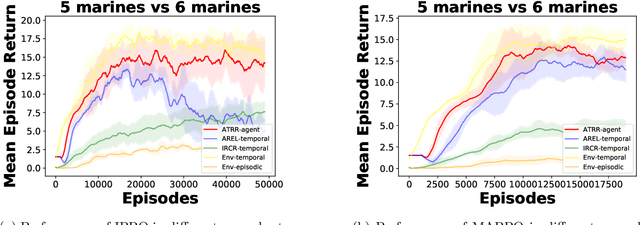
In multi-agent environments, agents often struggle to learn optimal policies due to sparse or delayed global rewards, particularly in long-horizon tasks where it is challenging to evaluate actions at intermediate time steps. We introduce Temporal-Agent Reward Redistribution (TAR$^2$), a novel approach designed to address the agent-temporal credit assignment problem by redistributing sparse rewards both temporally and across agents. TAR$^2$ decomposes sparse global rewards into time-step-specific rewards and calculates agent-specific contributions to these rewards. We theoretically prove that TAR$^2$ is equivalent to potential-based reward shaping, ensuring that the optimal policy remains unchanged. Empirical results demonstrate that TAR$^2$ stabilizes and accelerates the learning process. Additionally, we show that when TAR$^2$ is integrated with single-agent reinforcement learning algorithms, it performs as well as or better than traditional multi-agent reinforcement learning methods.
LoKO: Low-Rank Kalman Optimizer for Online Fine-Tuning of Large Models
Oct 15, 2024



Training large models with millions or even billions of parameters from scratch incurs substantial computational costs. Parameter Efficient Fine-Tuning (PEFT) methods, particularly Low-Rank Adaptation (LoRA), address this challenge by adapting only a reduced number of parameters to specific tasks with gradient-based optimizers. In this paper, we cast PEFT as an optimal filtering/state estimation problem and present Low-Rank Kalman Optimizer (LoKO) to estimate the optimal trainable parameters in an online manner. We leverage the low-rank decomposition in LoRA to significantly reduce matrix sizes in Kalman iterations and further capitalize on a diagonal approximation of the covariance matrix to effectively decrease computational complexity from quadratic to linear in the number of trainable parameters. Moreover, we discovered that the initialization of the covariance matrix within the Kalman algorithm and the accurate estimation of the observation noise covariance are the keys in this formulation, and we propose robust approaches that work well across a vast range of well-established computer vision and language models. Our results show that LoKO converges with fewer iterations and yields better performance models compared to commonly used optimizers with LoRA in both image classifications and language tasks. Our study opens up the possibility of leveraging the Kalman filter as an effective optimizer for the online fine-tuning of large models.
DroneDiffusion: Robust Quadrotor Dynamics Learning with Diffusion Models
Sep 17, 2024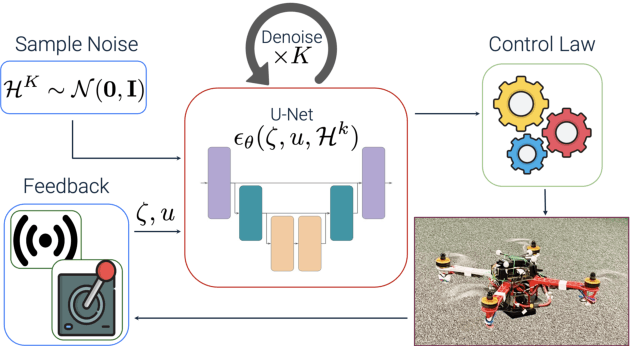
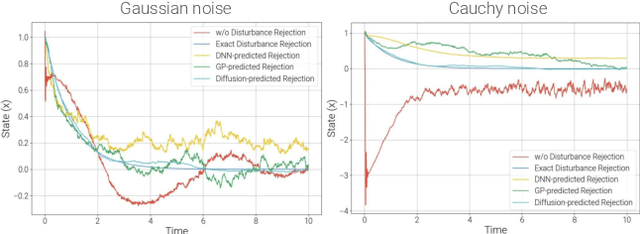
An inherent fragility of quadrotor systems stems from model inaccuracies and external disturbances. These factors hinder performance and compromise the stability of the system, making precise control challenging. Existing model-based approaches either make deterministic assumptions, utilize Gaussian-based representations of uncertainty, or rely on nominal models, all of which often fall short in capturing the complex, multimodal nature of real-world dynamics. This work introduces DroneDiffusion, a novel framework that leverages conditional diffusion models to learn quadrotor dynamics, formulated as a sequence generation task. DroneDiffusion achieves superior generalization to unseen, complex scenarios by capturing the temporal nature of uncertainties and mitigating error propagation. We integrate the learned dynamics with an adaptive controller for trajectory tracking with stability guarantees. Extensive experiments in both simulation and real-world flights demonstrate the robustness of the framework across a range of scenarios, including unfamiliar flight paths and varying payloads, velocities, and wind disturbances.