 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Probabilistic Forecasting with Stochastic Decomposition Layers
Dec 21, 2025AI weather prediction ensembles with latent noise injection and optimized with the continuous ranked probability score (CRPS) have produced both accurate and well-calibrated predictions with far less computational cost compared with diffusion-based methods. However, current CRPS ensemble approaches vary in their training strategies and noise injection mechanisms, with most injecting noise globally throughout the network via conditional normalization. This structure increases training expense and limits the physical interpretability of the stochastic perturbations. We introduce Stochastic Decomposition Layers (SDL) for converting deterministic machine learning weather models into probabilistic ensemble systems. Adapted from StyleGAN's hierarchical noise injection, SDL applies learned perturbations at three decoder scales through latent-driven modulation, per-pixel noise, and channel scaling. When applied to WXFormer via transfer learning, SDL requires less than 2\% of the computational cost needed to train the baseline model. Each ensemble member is generated from a compact latent tensor (5 MB), enabling perfect reproducibility and post-inference spread adjustment through latent rescaling. Evaluation on 2022 ERA5 reanalysis shows ensembles with spread-skill ratios approaching unity and rank histograms that progressively flatten toward uniformity through medium-range forecasts, achieving calibration competitive with operational IFS-ENS. Multi-scale experiments reveal hierarchical uncertainty: coarse layers modulate synoptic patterns while fine layers control mesoscale variability. The explicit latent parameterization provides interpretable uncertainty quantification for operational forecasting and climate applications.
Reinforcement Learning (RL) Meets Urban Climate Modeling: Investigating the Efficacy and Impacts of RL-Based HVAC Control
May 11, 2025Reinforcement learning (RL)-based heating, ventilation, and air conditioning (HVAC) control has emerged as a promising technology for reducing building energy consumption while maintaining indoor thermal comfort. However, the efficacy of such strategies is influenced by the background climate and their implementation may potentially alter both the indoor climate and local urban climate. This study proposes an integrated framework combining RL with an urban climate model that incorporates a building energy model, aiming to evaluate the efficacy of RL-based HVAC control across different background climates, impacts of RL strategies on indoor climate and local urban climate, and the transferability of RL strategies across cities. Our findings reveal that the reward (defined as a weighted combination of energy consumption and thermal comfort) and the impacts of RL strategies on indoor climate and local urban climate exhibit marked variability across cities with different background climates. The sensitivity of reward weights and the transferability of RL strategies are also strongly influenced by the background climate. Cities in hot climates tend to achieve higher rewards across most reward weight configurations that balance energy consumption and thermal comfort, and those cities with more varying atmospheric temperatures demonstrate greater RL strategy transferability. These findings underscore the importance of thoroughly evaluating RL-based HVAC control strategies in diverse climatic contexts. This study also provides a new insight that city-to-city learning will potentially aid the deployment of RL-based HVAC control.
Evidential Deep Learning: Enhancing Predictive Uncertainty Estimation for Earth System Science Applications
Sep 22, 2023Robust quantification of predictive uncertainty is critical for understanding factors that drive weather and climate outcomes. Ensembles provide predictive uncertainty estimates and can be decomposed physically, but both physics and machine learning ensembles are computationally expensive. Parametric deep learning can estimate uncertainty with one model by predicting the parameters of a probability distribution but do not account for epistemic uncertainty.. Evidential deep learning, a technique that extends parametric deep learning to higher-order distributions, can account for both aleatoric and epistemic uncertainty with one model. This study compares the uncertainty derived from evidential neural networks to those obtained from ensembles. Through applications of classification of winter precipitation type and regression of surface layer fluxes, we show evidential deep learning models attaining predictive accuracy rivaling standard methods, while robustly quantifying both sources of uncertainty. We evaluate the uncertainty in terms of how well the predictions are calibrated and how well the uncertainty correlates with prediction error. Analyses of uncertainty in the context of the inputs reveal sensitivities to underlying meteorological processes, facilitating interpretation of the models. The conceptual simplicity, interpretability, and computational efficiency of evidential neural networks make them highly extensible, offering a promising approach for reliable and practical uncertainty quantification in Earth system science modeling. In order to encourage broader adoption of evidential deep learning in Earth System Science, we have developed a new Python package, MILES-GUESS (https://github.com/ai2es/miles-guess), that enables users to train and evaluate both evidential and ensemble deep learning.
Machine Learning and VIIRS Satellite Retrievals for Skillful Fuel Moisture Content Monitoring in Wildfire Management
May 17, 2023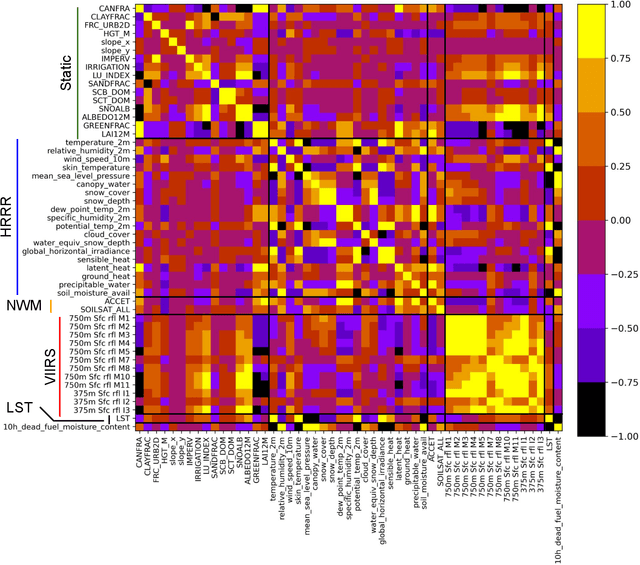
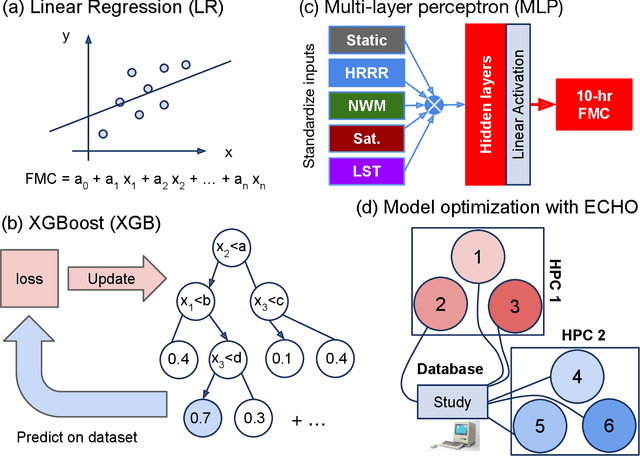
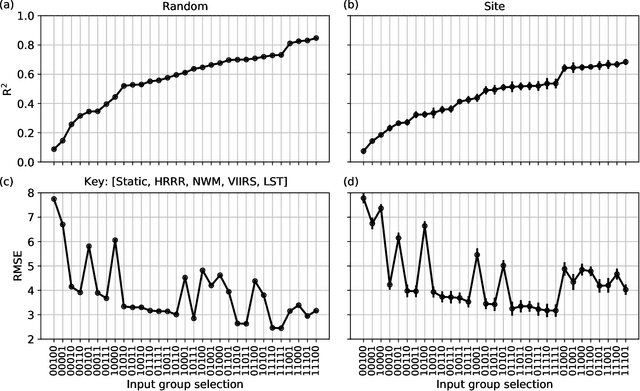
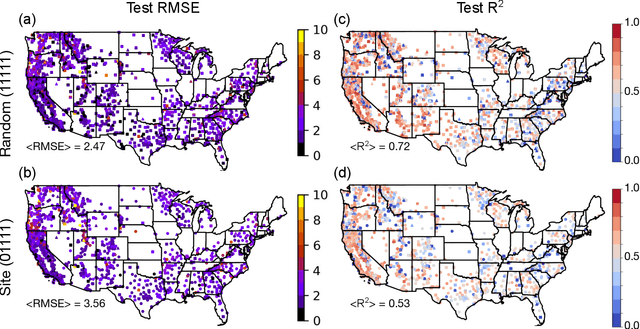
Monitoring the fuel moisture content (FMC) of vegetation is crucial for managing and mitigating the impact of wildland fires. The combination of in situ FMC observations with numerical weather prediction (NWP) models and satellite retrievals has enabled the development of machine learning (ML) models to estimate dead FMC retrievals over the contiguous US (CONUS). In this study, ML models were trained using variables from the National Water Model and the High-Resolution Rapid Refresh (HRRR) NWP models, and static variables characterizing the surface properties, as well as surface reflectances and land surface temperature (LST) retrievals from the VIIRS instrument on board the Suomi-NPP satellite system. Extensive hyper-parameter optimization yielded skillful FMC models compared to a daily climatography RMSE (+44\%) and to an hourly climatography RMSE (+24\%). Furthermore, VIIRS retrievals were important predictors for estimating FMC, contributing significantly as a group due to their high band-correlation. In contrast, individual predictors in the HRRR group had relatively high importance according to the explainability techniques used. When both HRRR and VIIRS retrievals were not used as model inputs, the performance dropped significantly. If VIIRS retrievals were not used, the RMSE performance was worse. This highlights the importance of VIIRS retrievals in modeling FMC, which yielded better models compared to MODIS. Overall, the importance of the VIIRS group of predictors corroborates the dynamic relationship between the 10-h fuel and the atmosphere and soil moisture. These findings emphasize the significance of selecting appropriate data sources for predicting FMC with ML models, with VIIRS retrievals and selected HRRR variables being critical components in producing skillful FMC estimates.
Mimicking non-ideal instrument behavior for hologram processing using neural style translation
Jan 07, 2023Holographic cloud probes provide unprecedented information on cloud particle density, size and position. Each laser shot captures particles within a large volume, where images can be computationally refocused to determine particle size and shape. However, processing these holograms, either with standard methods or with machine learning (ML) models, requires considerable computational resources, time and occasional human intervention. ML models are trained on simulated holograms obtained from the physical model of the probe since real holograms have no absolute truth labels. Using another processing method to produce labels would be subject to errors that the ML model would subsequently inherit. Models perform well on real holograms only when image corruption is performed on the simulated images during training, thereby mimicking non-ideal conditions in the actual probe (Schreck et. al, 2022). Optimizing image corruption requires a cumbersome manual labeling effort. Here we demonstrate the application of the neural style translation approach (Gatys et. al, 2016) to the simulated holograms. With a pre-trained convolutional neural network (VGG-19), the simulated holograms are ``stylized'' to resemble the real ones obtained from the probe, while at the same time preserving the simulated image ``content'' (e.g. the particle locations and sizes). Two image similarity metrics concur that the stylized images are more like real holograms than the synthetic ones. With an ML model trained to predict particle locations and shapes on the stylized data sets, we observed comparable performance on both simulated and real holograms, obviating the need to perform manual labeling. The described approach is not specific to hologram images and could be applied in other domains for capturing noise and imperfections in observational instruments to make simulated data more like real world observations.
Neural network processing of holographic images
Mar 18, 2022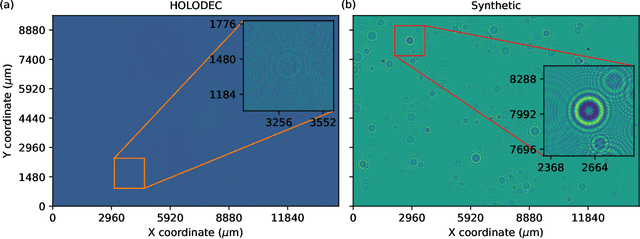
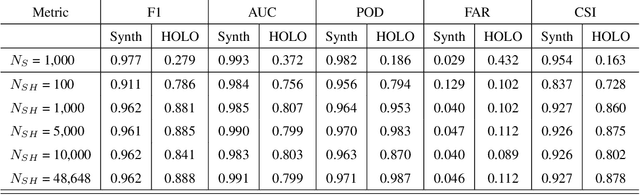
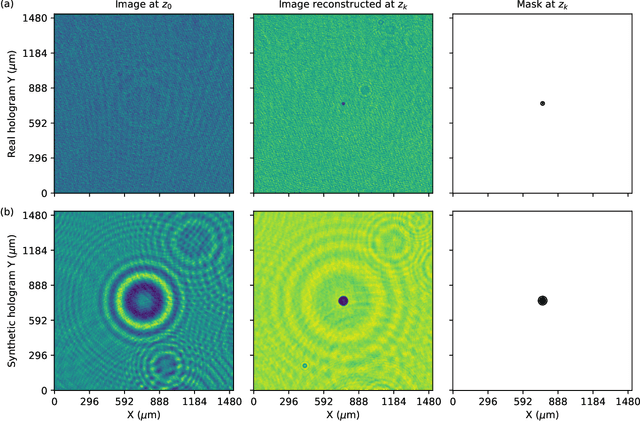
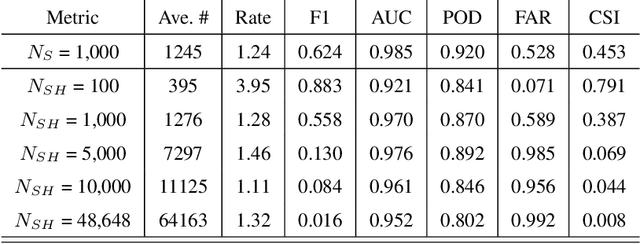
HOLODEC, an airborne cloud particle imager, captures holographic images of a fixed volume of cloud to characterize the types and sizes of cloud particles, such as water droplets and ice crystals. Cloud particle properties include position, diameter, and shape. We present a hologram processing algorithm, HolodecML, that utilizes a neural segmentation model, GPUs, and computational parallelization. HolodecML is trained using synthetically generated holograms based on a model of the instrument, and predicts masks around particles found within reconstructed images. From these masks, the position and size of the detected particles can be characterized in three dimensions. In order to successfully process real holograms, we find we must apply a series of image corrupting transformations and noise to the synthetic images used in training. In this evaluation, HolodecML had comparable position and size estimation performance to the standard processing method, but improved particle detection by nearly 20\% on several thousand manually labeled HOLODEC images. However, the improvement only occurred when image corruption was performed on the simulated images during training, thereby mimicking non-ideal conditions in the actual probe. The trained model also learned to differentiate artifacts and other impurities in the HOLODEC images from the particles, even though no such objects were present in the training data set, while the standard processing method struggled to separate particles from artifacts. The novelty of the training approach, which leveraged noise as a means for parameterizing non-ideal aspects of the HOLODEC detector, could be applied in other domains where the theoretical model is incapable of fully describing the real-world operation of the instrument and accurate truth data required for supervised learning cannot be obtained from real-world observations.
Learning retrosynthetic planning through self-play
Jan 19, 2019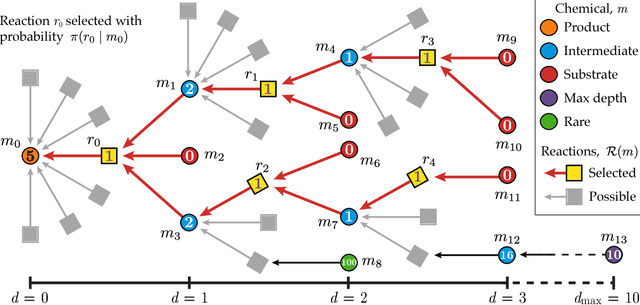
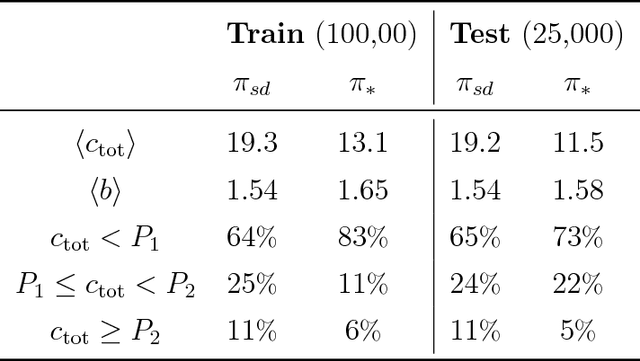
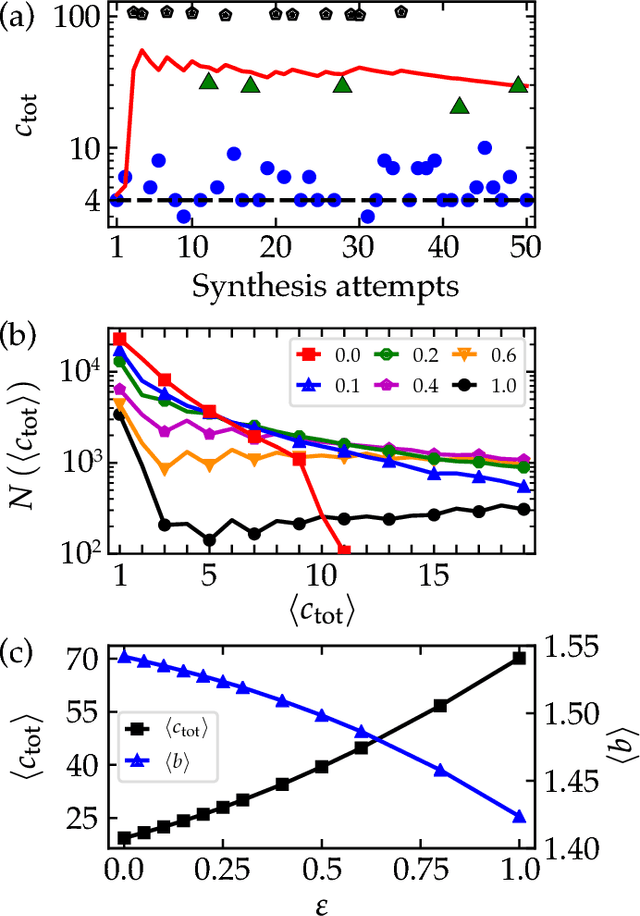

The problem of retrosynthetic planning can be framed as one player game, in which the chemist (or a computer program) works backwards from a molecular target to simpler starting materials though a series of choices regarding which reactions to perform. This game is challenging as the combinatorial space of possible choices is astronomical, and the value of each choice remains uncertain until the synthesis plan is completed and its cost evaluated. Here, we address this problem using deep reinforcement learning to identify policies that make (near) optimal reaction choices during each step of retrosynthetic planning. Using simulated experience or self-play, we train neural networks to estimate the expected synthesis cost or value of any given molecule based on a representation of its molecular structure. We show that learned policies based on this value network outperform heuristic approaches in synthesizing unfamiliar molecules from available starting materials using the fewest number of reactions. We discuss how the learned policies described here can be incorporated into existing synthesis planning tools and how they can be adapted to changes in the synthesis cost objective or material availability.