 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning retrosynthetic planning through self-play
Jan 19, 2019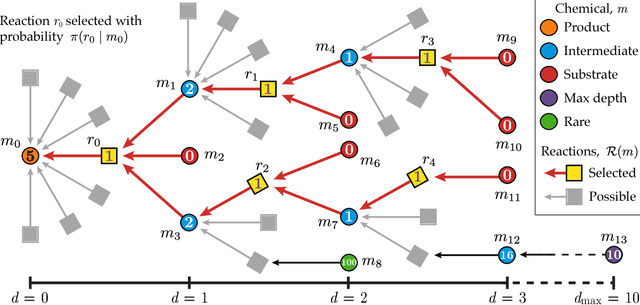
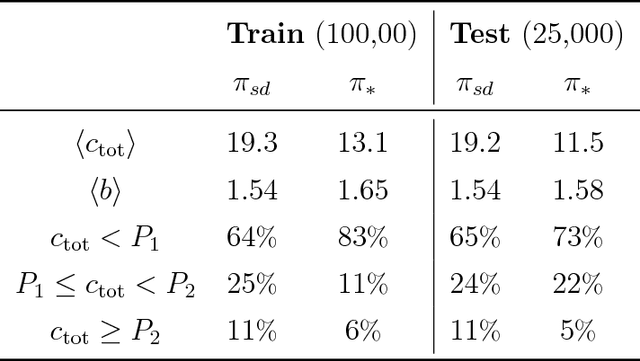
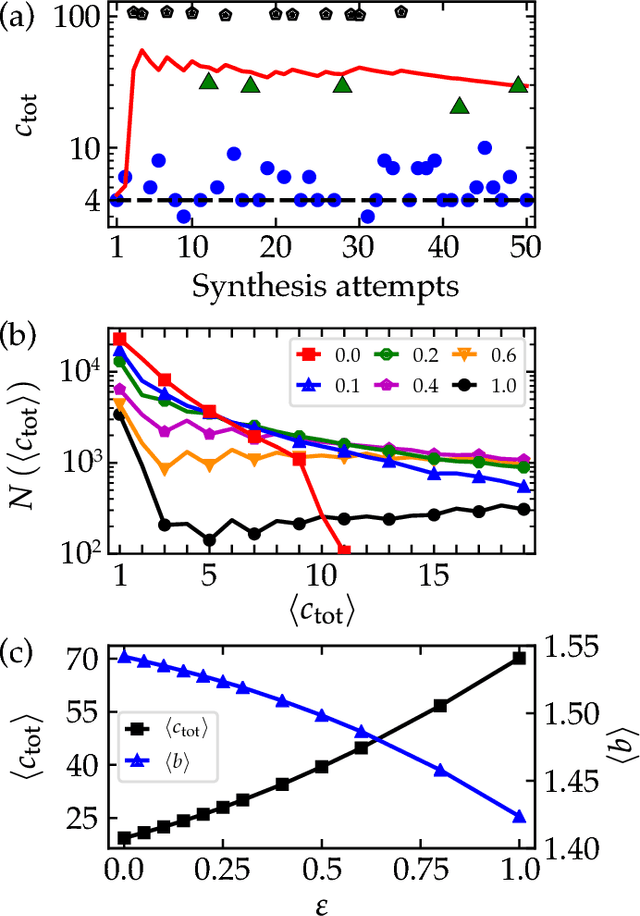

The problem of retrosynthetic planning can be framed as one player game, in which the chemist (or a computer program) works backwards from a molecular target to simpler starting materials though a series of choices regarding which reactions to perform. This game is challenging as the combinatorial space of possible choices is astronomical, and the value of each choice remains uncertain until the synthesis plan is completed and its cost evaluated. Here, we address this problem using deep reinforcement learning to identify policies that make (near) optimal reaction choices during each step of retrosynthetic planning. Using simulated experience or self-play, we train neural networks to estimate the expected synthesis cost or value of any given molecule based on a representation of its molecular structure. We show that learned policies based on this value network outperform heuristic approaches in synthesizing unfamiliar molecules from available starting materials using the fewest number of reactions. We discuss how the learned policies described here can be incorporated into existing synthesis planning tools and how they can be adapted to changes in the synthesis cost objective or material availability.