 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Grunts to Grammar: Emergent Language from Cooperative Foraging
May 19, 2025Early cavemen relied on gestures, vocalizations, and simple signals to coordinate, plan, avoid predators, and share resources. Today, humans collaborate using complex languages to achieve remarkable results. What drives this evolution in communication? How does language emerge, adapt, and become vital for teamwork? Understanding the origins of language remains a challenge. A leading hypothesis in linguistics and anthropology posits that language evolved to meet the ecological and social demands of early human cooperation. Language did not arise in isolation, but through shared survival goals. Inspired by this view, we investigate the emergence of language in multi-agent Foraging Games. These environments are designed to reflect the cognitive and ecological constraints believed to have influenced the evolution of communication. Agents operate in a shared grid world with only partial knowledge about other agents and the environment, and must coordinate to complete games like picking up high-value targets or executing temporally ordered actions. Using end-to-end deep reinforcement learning, agents learn both actions and communication strategies from scratch. We find that agents develop communication protocols with hallmark features of natural language: arbitrariness, interchangeability, displacement, cultural transmission, and compositionality. We quantify each property and analyze how different factors, such as population size and temporal dependencies, shape specific aspects of the emergent language. Our framework serves as a platform for studying how language can evolve from partial observability, temporal reasoning, and cooperative goals in embodied multi-agent settings. We will release all data, code, and models publicly.
What makes a face looks like a hat: Decoupling low-level and high-level Visual Properties with Image Triplets
Sep 03, 2024



In visual decision making, high-level features, such as object categories, have a strong influence on choice. However, the impact of low-level features on behavior is less understood partly due to the high correlation between high- and low-level features in the stimuli presented (e.g., objects of the same category are more likely to share low-level features). To disentangle these effects, we propose a method that de-correlates low- and high-level visual properties in a novel set of stimuli. Our method uses two Convolutional Neural Networks (CNNs) as candidate models of the ventral visual stream: the CORnet-S that has high neural predictivity in high-level, IT-like responses and the VGG-16 that has high neural predictivity in low-level responses. Triplets (root, image1, image2) of stimuli are parametrized by the level of low- and high-level similarity of images extracted from the different layers. These stimuli are then used in a decision-making task where participants are tasked to choose the most similar-to-the-root image. We found that different networks show differing abilities to predict the effects of low-versus-high-level similarity: while CORnet-S outperforms VGG-16 in explaining human choices based on high-level similarity, VGG-16 outperforms CORnet-S in explaining human choices based on low-level similarity. Using Brain-Score, we observed that the behavioral prediction abilities of different layers of these networks qualitatively corresponded to their ability to explain neural activity at different levels of the visual hierarchy. In summary, our algorithm for stimulus set generation enables the study of how different representations in the visual stream affect high-level cognitive behaviors.
TTA-Nav: Test-time Adaptive Reconstruction for Point-Goal Navigation under Visual Corruptions
Mar 14, 2024Robot navigation under visual corruption presents a formidable challenge. To address this, we propose a Test-time Adaptation (TTA) method, named as TTA-Nav, for point-goal navigation under visual corruptions. Our "plug-and-play" method incorporates a top-down decoder to a pre-trained navigation model. Firstly, the pre-trained navigation model gets a corrupted image and extracts features. Secondly, the top-down decoder produces the reconstruction given the high-level features extracted by the pre-trained model. Then, it feeds the reconstruction of a corrupted image back to the pre-trained model. Finally, the pre-trained model does forward pass again to output action. Despite being trained solely on clean images, the top-down decoder can reconstruct cleaner images from corrupted ones without the need for gradient-based adaptation. The pre-trained navigation model with our top-down decoder significantly enhances navigation performance across almost all visual corruptions in our benchmarks. Our method improves the success rate of point-goal navigation from the state-of-the-art result of 46% to 94% on the most severe corruption. This suggests its potential for broader application in robotic visual navigation. Project page: https://sites.google.com/view/tta-nav
Deep Reinforcement Learning Models Predict Visual Responses in the Brain: A Preliminary Result
Jun 18, 2021
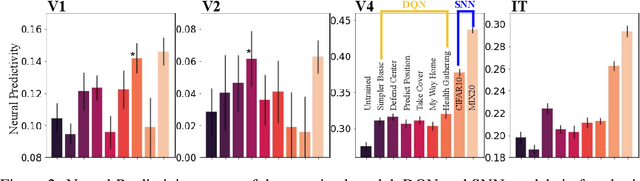
Supervised deep convolutional neural networks (DCNNs) are currently one of the best computational models that can explain how the primate ventral visual stream solves object recognition. However, embodied cognition has not been considered in the existing visual processing models. From the ecological standpoint, humans learn to recognize objects by interacting with them, allowing better classification, specialization, and generalization. Here, we ask if computational models under the embodied learning framework can explain mechanisms underlying object recognition in the primate visual system better than the existing supervised models? To address this question, we use reinforcement learning to train neural network models to play a 3D computer game and we find that these reinforcement learning models achieve neural response prediction accuracy scores in the early visual areas (e.g., V1 and V2) in the levels that are comparable to those accomplished by the supervised neural network model. In contrast, the supervised neural network models yield better neural response predictions in the higher visual areas, compared to the reinforcement learning models. Our preliminary results suggest the future direction of visual neuroscience in which deep reinforcement learning should be included to fill the missing embodiment concept.
A Pilot Study on Visually-Stimulated Cognitive Tasks for EEG-Based Dementia Recognition Using Frequency and Time Features
Mar 05, 2021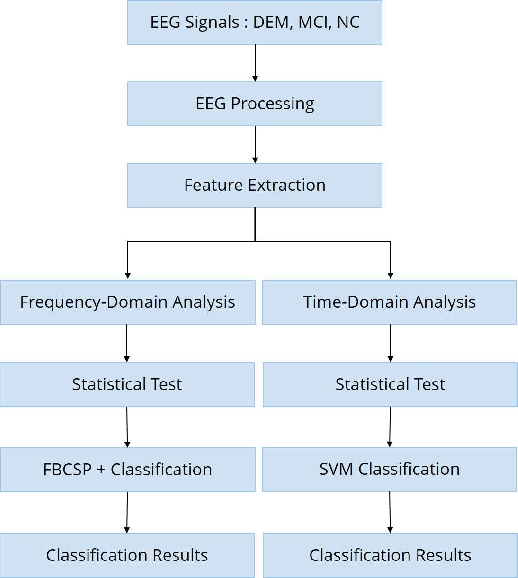
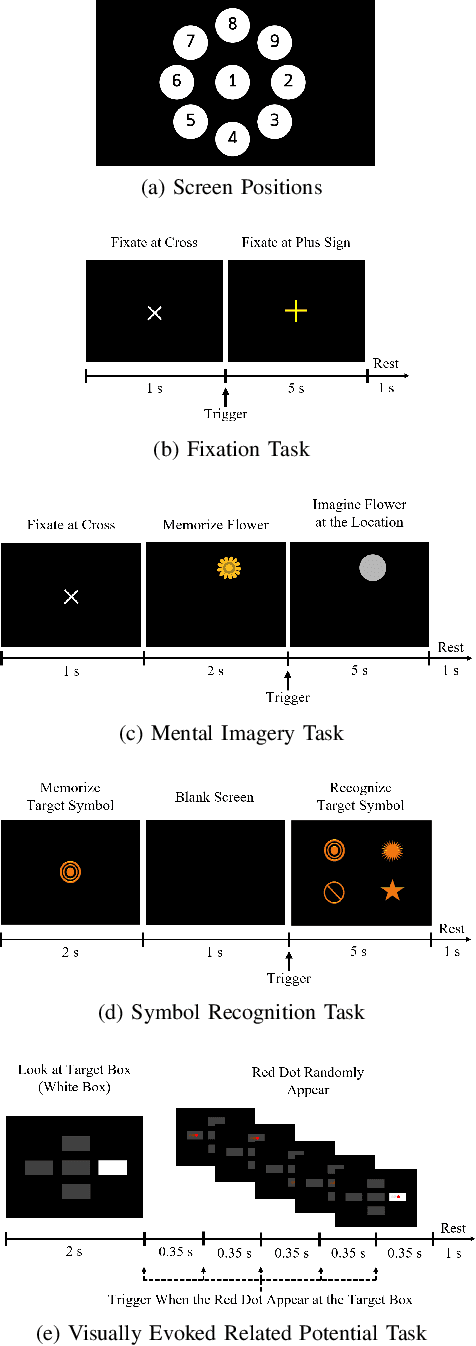
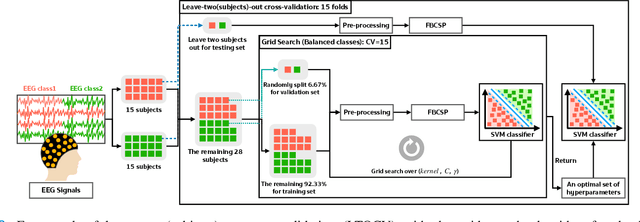
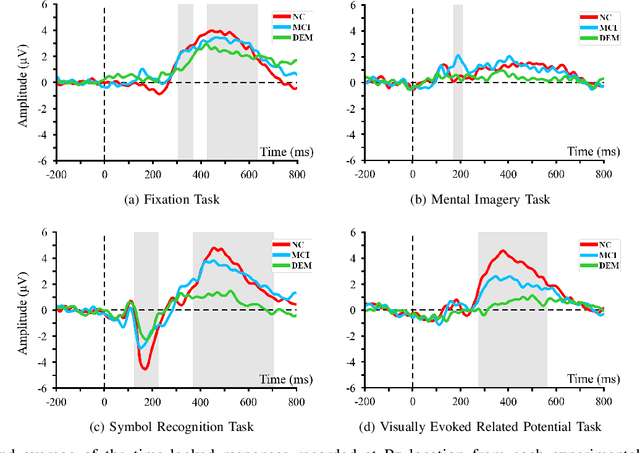
Dementia is one of the main causes of cognitive decline. Since the majority of dementia patients cannot be cured, being able to diagnose them before the onset of the symptoms can prevent the rapid progression of the cognitive impairment. This study aims to investigate the difference in the Electroencephalograph (EEG) signals of three groups of subjects: Normal Control (NC), Mild Cognitive Impairment (MCI), and Dementia (DEM). Unlike previous works that focus on the diagnosis of Alzheimer's disease (AD) from EEG signals, we study the detection of dementia to generalize the classification models to other types of dementia. We have developed a pilot study on machine learning-based dementia diagnosis using EEG signals from four visual stimulation tasks (Fixation, Mental Imagery, Symbol Recognition, and Visually Evoked Related Potential) to identify the most suitable task and method to detect dementia using EEG signals. We extracted both frequency and time domain features from the EEG signals and applied a Support Vector Machine (SVM) for each domain to classify the patients using those extracted features. Additionally, we study the feasibility of the Filter Bank Common Spatial Pattern (FBCSP) algorithm to extract features from the frequency domain to detect dementia. The evaluation of the model shows that the tasks that test the working memory are the most appropriate to detect dementia using EEG signals in both time and frequency domain analysis. However, the best results in both domains are obtained by combining features of all four cognitive tasks.