 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat makes a face looks like a hat: Decoupling low-level and high-level Visual Properties with Image Triplets
Sep 03, 2024



In visual decision making, high-level features, such as object categories, have a strong influence on choice. However, the impact of low-level features on behavior is less understood partly due to the high correlation between high- and low-level features in the stimuli presented (e.g., objects of the same category are more likely to share low-level features). To disentangle these effects, we propose a method that de-correlates low- and high-level visual properties in a novel set of stimuli. Our method uses two Convolutional Neural Networks (CNNs) as candidate models of the ventral visual stream: the CORnet-S that has high neural predictivity in high-level, IT-like responses and the VGG-16 that has high neural predictivity in low-level responses. Triplets (root, image1, image2) of stimuli are parametrized by the level of low- and high-level similarity of images extracted from the different layers. These stimuli are then used in a decision-making task where participants are tasked to choose the most similar-to-the-root image. We found that different networks show differing abilities to predict the effects of low-versus-high-level similarity: while CORnet-S outperforms VGG-16 in explaining human choices based on high-level similarity, VGG-16 outperforms CORnet-S in explaining human choices based on low-level similarity. Using Brain-Score, we observed that the behavioral prediction abilities of different layers of these networks qualitatively corresponded to their ability to explain neural activity at different levels of the visual hierarchy. In summary, our algorithm for stimulus set generation enables the study of how different representations in the visual stream affect high-level cognitive behaviors.
Deep Reinforcement Learning Models Predict Visual Responses in the Brain: A Preliminary Result
Jun 18, 2021
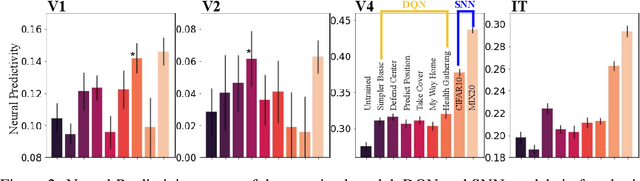
Supervised deep convolutional neural networks (DCNNs) are currently one of the best computational models that can explain how the primate ventral visual stream solves object recognition. However, embodied cognition has not been considered in the existing visual processing models. From the ecological standpoint, humans learn to recognize objects by interacting with them, allowing better classification, specialization, and generalization. Here, we ask if computational models under the embodied learning framework can explain mechanisms underlying object recognition in the primate visual system better than the existing supervised models? To address this question, we use reinforcement learning to train neural network models to play a 3D computer game and we find that these reinforcement learning models achieve neural response prediction accuracy scores in the early visual areas (e.g., V1 and V2) in the levels that are comparable to those accomplished by the supervised neural network model. In contrast, the supervised neural network models yield better neural response predictions in the higher visual areas, compared to the reinforcement learning models. Our preliminary results suggest the future direction of visual neuroscience in which deep reinforcement learning should be included to fill the missing embodiment concept.
An Explicit Local and Global Representation Disentanglement Framework with Applications in Deep Clustering and Unsupervised Object Detection
Feb 24, 2020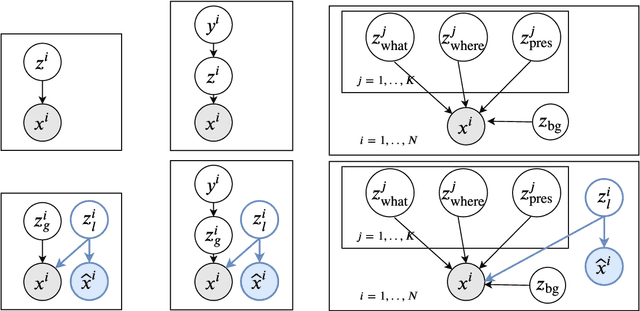

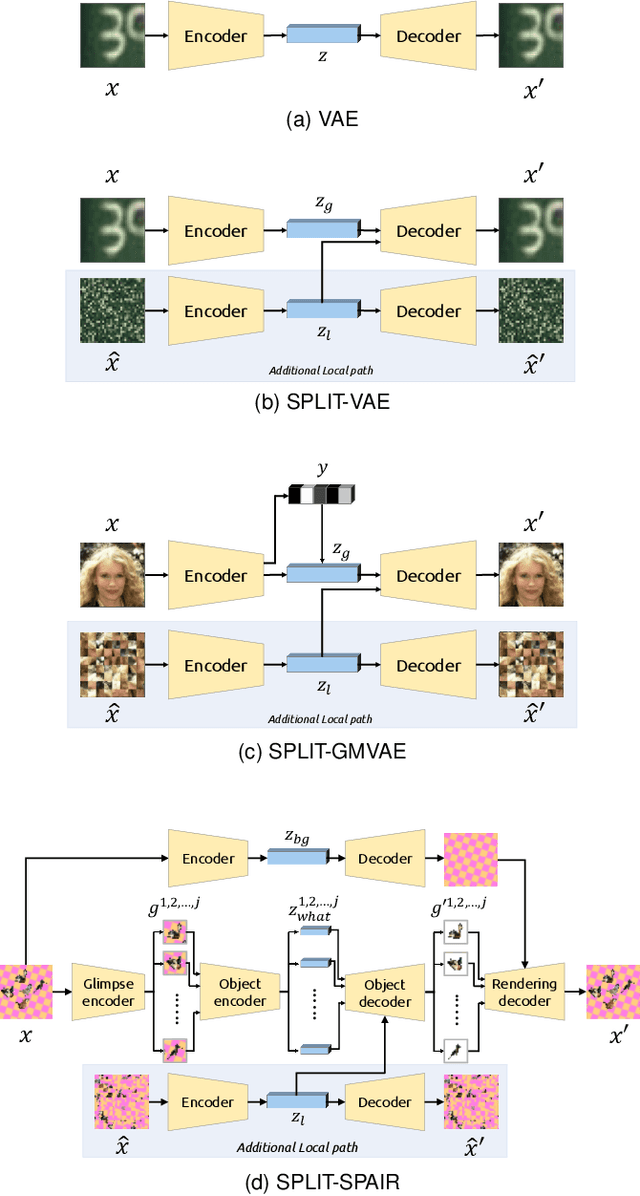
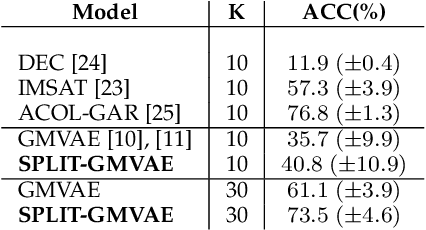
Visual data can be understood at different levels of granularity, where global features correspond to semantic-level information and local features correspond to texture patterns. In this work, we propose a framework, called SPLIT, which allows us to disentangle local and global information into two separate sets of latent variables within the variational autoencoder (VAE) framework. Our framework adds generative assumption to the VAE by requiring a subset of the latent variables to generate an auxiliary set of observable data. This additional generative assumption primes the latent variables to local information and encourages the other latent variables to represent global information. We examine three different flavours of VAEs with different generative assumptions. We show that the framework can effectively disentangle local and global information within these models leads to improved representation, with better clustering and unsupervised object detection benchmarks. Finally, we establish connections between SPLIT and recent research in cognitive neuroscience regarding the disentanglement in human visual perception. The code for our experiments is at https://github.com/51616/split-vae .