 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixNet: Joining Force of Classical and Modern Approaches Toward the Comprehensive Pipeline in Motor Imagery EEG Classification
Sep 06, 2024



Recent advances in deep learning (DL) have significantly impacted motor imagery (MI)-based brain-computer interface (BCI) systems, enhancing the decoding of electroencephalography (EEG) signals. However, most studies struggle to identify discriminative patterns across subjects during MI tasks, limiting MI classification performance. In this article, we propose MixNet, a novel classification framework designed to overcome this limitation by utilizing spectral-spatial signals from MI data, along with a multitask learning architecture named MIN2Net, for classification. Here, the spectral-spatial signals are generated using the filter-bank common spatial patterns (FBCSPs) method on MI data. Since the multitask learning architecture is used for the classification task, the learning in each task may exhibit different generalization rates and potential overfitting across tasks. To address this issue, we implement adaptive gradient blending, simultaneously regulating multiple loss weights and adjusting the learning pace for each task based on its generalization/overfitting tendencies. Experimental results on six benchmark data sets of different data sizes demonstrate that MixNet consistently outperforms all state-of-the-art algorithms in subject-dependent and -independent settings. Finally, the low-density EEG MI classification results show that MixNet outperforms all state-of-the-art algorithms, offering promising implications for Internet of Thing (IoT) applications, such as lightweight and portable EEG wearable devices based on low-density montages.
* Supplementary materials and source codes are available on-line at https://github.com/Max-Phairot-A/MixNet
Combining EEG and NLP Features for Predicting Students' Lecture Comprehension using Ensemble Classification
Nov 18, 2023



Electroencephalography (EEG) and Natural Language Processing (NLP) can be applied for education to measure students' comprehension in classroom lectures; currently, the two measures have been used separately. In this work, we propose a classification framework for predicting students' lecture comprehension in two tasks: (i) students' confusion after listening to the simulated lecture and (ii) the correctness of students' responses to the post-lecture assessment. The proposed framework includes EEG and NLP feature extraction, processing, and classification. EEG and NLP features are extracted to construct integrated features obtained from recorded EEG signals and sentence-level syntactic analysis, which provide information about specific biomarkers and sentence structures. An ensemble stacking classification method -- a combination of multiple individual models that produces an enhanced predictive model -- is studied to learn from the features to make predictions accurately. Furthermore, we also utilized subjective confusion ratings as another integrated feature to enhance classification performance. By doing so, experiment results show that this framework performs better than the baselines, which achieved F1 up to 0.65 for predicting confusion and 0.78 for predicting correctness, highlighting that utilizing this has helped improve the classification performance.
PseudoCell: Hard Negative Mining as Pseudo Labeling for Deep Learning-Based Centroblast Cell Detection
Jul 06, 2023Patch classification models based on deep learning have been utilized in whole-slide images (WSI) of H&E-stained tissue samples to assist pathologists in grading follicular lymphoma patients. However, these approaches still require pathologists to manually identify centroblast cells and provide refined labels for optimal performance. To address this, we propose PseudoCell, an object detection framework to automate centroblast detection in WSI (source code is available at https://github.com/IoBT-VISTEC/PseudoCell.git). This framework incorporates centroblast labels from pathologists and combines them with pseudo-negative labels obtained from undersampled false-positive predictions using the cell's morphological features. By employing PseudoCell, pathologists' workload can be reduced as it accurately narrows down the areas requiring their attention during examining tissue. Depending on the confidence threshold, PseudoCell can eliminate 58.18-99.35% of non-centroblasts tissue areas on WSI. This study presents a practical centroblast prescreening method that does not require pathologists' refined labels for improvement. Detailed guidance on the practical implementation of PseudoCell is provided in the discussion section.
ApSense: Data-driven Algorithm in PPG-based Sleep Apnea Sensing
Jun 19, 2023In this paper, we utilized obstructive sleep apnea and cardiovascular disease-related photoplethysmography (PPG) features in constructing the input to deep learning (DL). The features are pulse wave amplitude (PWA), beat-to-beat or RR interval, a derivative of PWA, a derivative of RR interval, systolic phase duration, diastolic phase duration, and pulse area. Then, we develop DL architectures to evaluate the proposed features' usefulness. Eventually, we demonstrate that in human-machine settings where the medical staff only needs to label 20% of the PPG recording length, our proposed features with the developed DL architectures achieve 79.95% and 73.81% recognition accuracy in MESA and HeartBEAT datasets. This simplifies the labelling task of the medical staff during the sleep test yet provides accurate apnea event recognition.
PACMAN: a framework for pulse oximeter digit detection and reading in a low-resource setting
Dec 09, 2022



In light of the COVID-19 pandemic, patients were required to manually input their daily oxygen saturation (SpO2) and pulse rate (PR) values into a health monitoring system-unfortunately, such a process trend to be an error in typing. Several studies attempted to detect the physiological value from the captured image using optical character recognition (OCR). However, the technology has limited availability with high cost. Thus, this study aimed to propose a novel framework called PACMAN (Pandemic Accelerated Human-Machine Collaboration) with a low-resource deep learning-based computer vision. We compared state-of-the-art object detection algorithms (scaled YOLOv4, YOLOv5, and YOLOR), including the commercial OCR tools for digit recognition on the captured images from pulse oximeter display. All images were derived from crowdsourced data collection with varying quality and alignment. YOLOv5 was the best-performing model against the given model comparison across all datasets, notably the correctly orientated image dataset. We further improved the model performance with the digits auto-orientation algorithm and applied a clustering algorithm to extract SpO2 and PR values. The accuracy performance of YOLOv5 with the implementations was approximately 81.0-89.5%, which was enhanced compared to without any additional implementation. Accordingly, this study highlighted the completion of PACMAN framework to detect and read digits in real-world datasets. The proposed framework has been currently integrated into the patient monitoring system utilized by hospitals nationwide.
ANet: Autoencoder-Based Local Field Potential Feature Extractor for Evaluating An Antidepressant Effect in Mice after Administering Kratom Leaf Extracts
Sep 17, 2022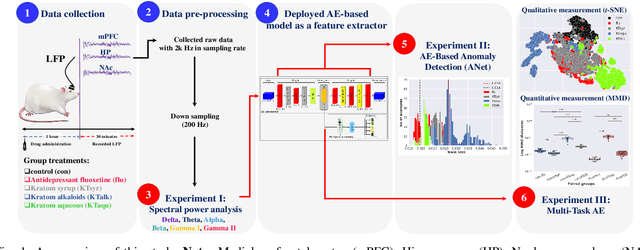
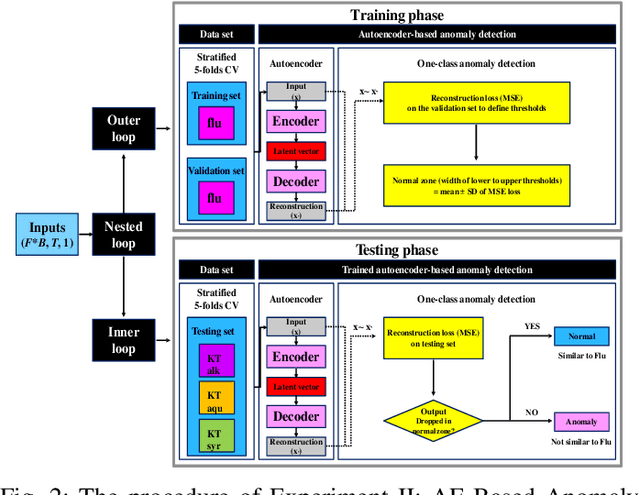

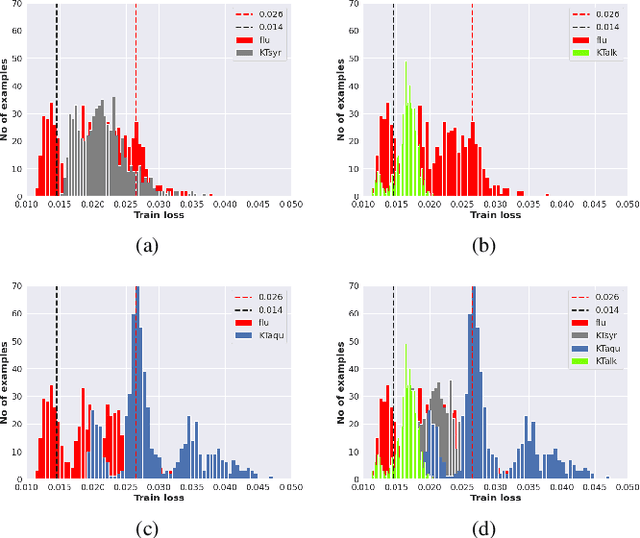
Kratom (KT) typically exerts antidepressant (AD) effects. However, evaluating which form of KT extracts possesses AD properties similar to the standard AD fluoxetine (flu) remained challenging. Here, we adopted an autoencoder (AE)-based anomaly detector called ANet to measure the similarity of mice's local field potential (LFP) features that responded to KT leave extracts and AD flu. The features that responded to KT syrup had the highest similarity to those that responded to the AD flu at 85.62 $\pm$ 0.29%. This finding presents the higher feasibility of using KT syrup as an alternative substance for depressant therapy than KT alkaloids and KT aqueous, which are the other candidates in this study. Apart from the similarity measurement, we utilized ANet as a multi-task AE and evaluated the performance in discriminating multi-class LFP responses corresponding to the effect of different KT extracts and AD flu simultaneously. Furthermore, we visualized learned latent features among LFP responses qualitatively and quantitatively as t-SNE projection and maximum mean discrepancy distance, respectively. The classification results reported the accuracy and F1-score of 79.78 $\pm$ 0.39% and 79.53 $\pm$ 0.00%. In summary, the outcomes of this research might help therapeutic design devices for an alternative substance profile evaluation, such as Kratom-based form in real-world applications.
RRWaveNet: A Compact End-to-End Multi-Scale Residual CNN for Robust PPG Respiratory Rate Estimation
Aug 18, 2022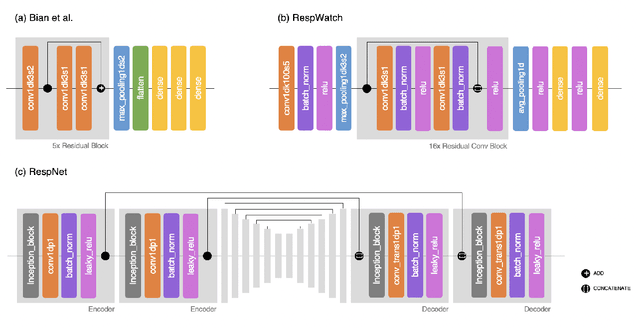
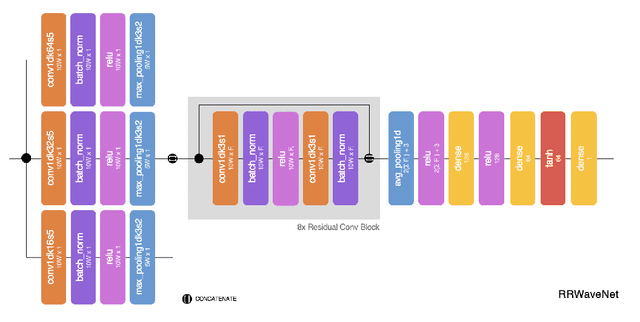
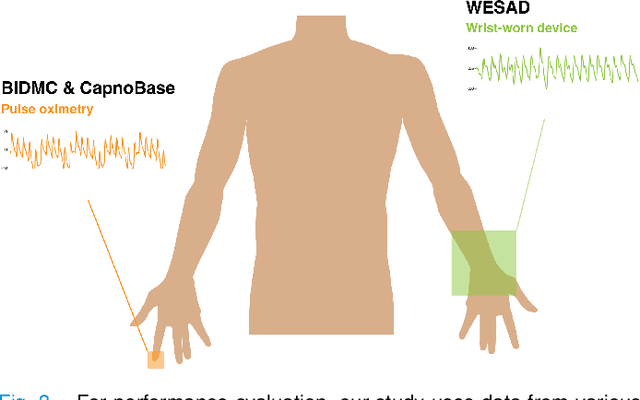
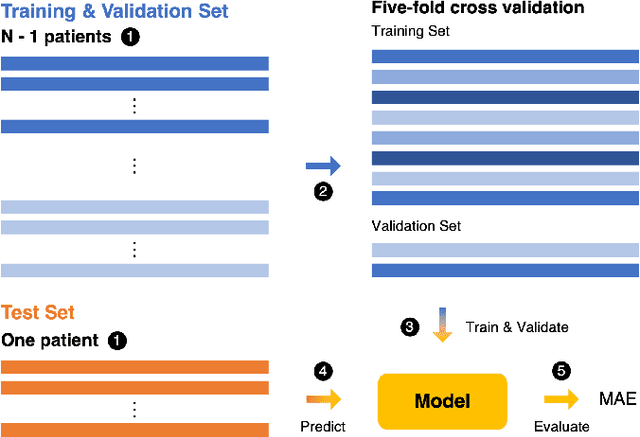
Respiratory rate (RR) is an important biomarker as RR changes can reflect severe medical events such as heart disease, lung disease, and sleep disorders. Unfortunately, however, standard manual RR counting is prone to human error and cannot be performed continuously. This study proposes a method for continuously estimating RR, RRWaveNet. The method is a compact end-to-end deep learning model which does not require feature engineering and can use low-cost raw photoplethysmography (PPG) as input signal. RRWaveNet was tested subject-independently and compared to baseline in three datasets (BIDMC, CapnoBase, and WESAD) and using three window sizes (16, 32, and 64 seconds). RRWaveNet outperformed current state-of-the-art methods with mean absolute errors at optimal window size of 1.66 \pm 1.01, 1.59 \pm 1.08, and 1.92 \pm 0.96 breaths per minute for each dataset. In remote monitoring settings, such as in the WESAD dataset, we apply transfer learning to two other ICU datasets, reducing the MAE to 1.52 \pm 0.50 breaths per minute, showing this model allows accurate and practical estimation of RR on affordable and wearable devices. Our study shows feasibility of remote RR monitoring in the context of telemedicine and at home.
EEG-BBNet: a Hybrid Framework for Brain Biometric using Graph Connectivity
Aug 17, 2022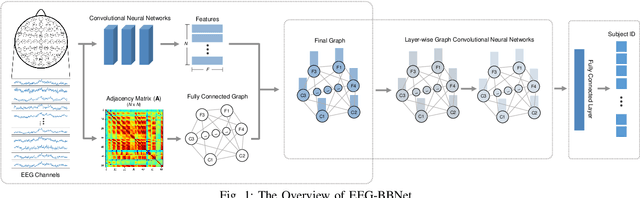
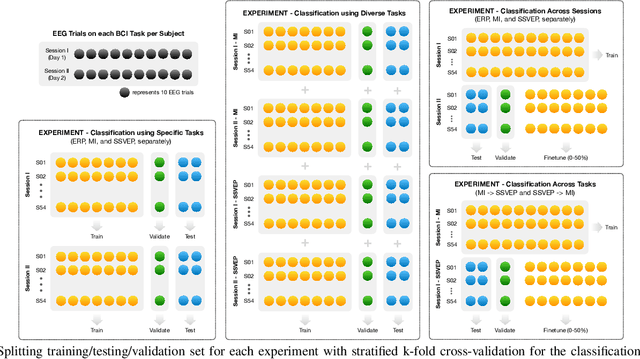
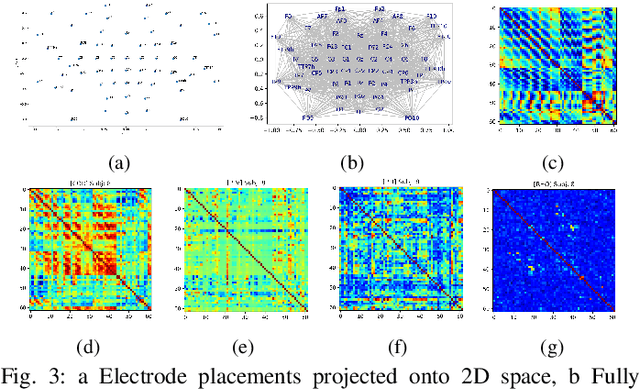
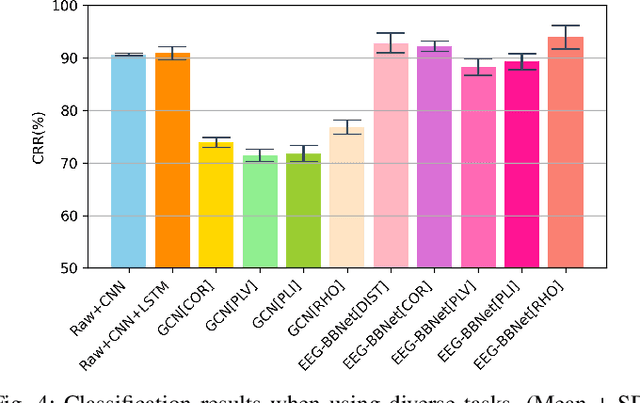
Brain biometrics based on electroencephalography (EEG) have been used increasingly for personal identification. Traditional machine learning techniques as well as modern day deep learning methods have been applied with promising results. In this paper we present EEG-BBNet, a hybrid network which integrates convolutional neural networks (CNN) with graph convolutional neural networks (GCNN). The benefit of the CNN in automatic feature extraction and the capability of GCNN in learning connectivity between EEG electrodes through graph representation are jointly exploited. We examine various connectivity measures, namely the Euclidean distance, Pearson's correlation coefficient, phase-locked value, phase-lag index, and Rho index. The performance of the proposed method is assessed on a benchmark dataset consisting of various brain-computer interface (BCI) tasks and compared to other state-of-the-art approaches. We found that our models outperform all baselines in the event-related potential (ERP) task with an average correct recognition rates up to 99.26% using intra-session data. EEG-BBNet with Pearson's correlation and RHO index provide the best classification results. In addition, our model demonstrates greater adaptability using inter-session and inter-task data. We also investigate the practicality of our proposed model with smaller number of electrodes. Electrode placements over the frontal lobe region appears to be most appropriate with minimal lost in performance.
OCTAve: 2D en face Optical Coherence Tomography Angiography Vessel Segmentation in Weakly-Supervised Learning with Locality Augmentation
Jul 25, 2022

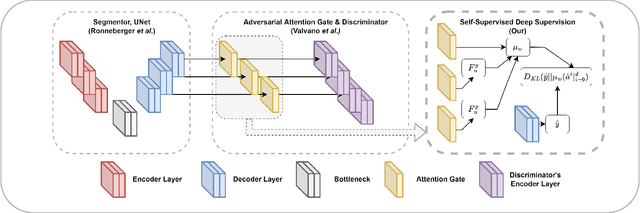
While there have been increased researches using deep learning techniques for the extraction of vascular structure from the 2D en face OCTA, for such approach, it is known that the data annotation process on the curvilinear structure like the retinal vasculature is very costly and time consuming, albeit few tried to address the annotation problem. In this work, we propose the application of the scribble-base weakly-supervised learning method to automate the pixel-level annotation. The proposed method, called OCTAve, combines the weakly-supervised learning using scribble-annotated ground truth augmented with an adversarial and a novel self-supervised deep supervision. Our novel mechanism is designed to utilize the discriminative outputs from the discrimination layer of a UNet-like architecture where the Kullback-Liebler Divergence between the aggregate discriminative outputs and the segmentation map predicate is minimized during the training. This combined method leads to the better localization of the vascular structure as shown in our experiments. We validate our proposed method on the large public datasets i.e., ROSE, OCTA-500. The segmentation performance is compared against both state-of-the-art fully-supervised and scribble-based weakly-supervised approaches. The implementation of our work used in the experiments is located at [LINK].
Deep Reinforcement Learning Models Predict Visual Responses in the Brain: A Preliminary Result
Jun 18, 2021
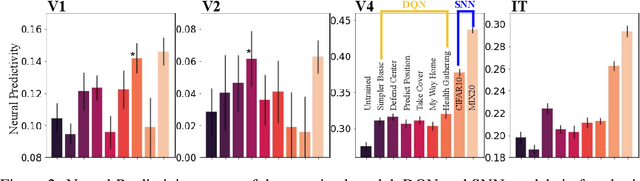
Supervised deep convolutional neural networks (DCNNs) are currently one of the best computational models that can explain how the primate ventral visual stream solves object recognition. However, embodied cognition has not been considered in the existing visual processing models. From the ecological standpoint, humans learn to recognize objects by interacting with them, allowing better classification, specialization, and generalization. Here, we ask if computational models under the embodied learning framework can explain mechanisms underlying object recognition in the primate visual system better than the existing supervised models? To address this question, we use reinforcement learning to train neural network models to play a 3D computer game and we find that these reinforcement learning models achieve neural response prediction accuracy scores in the early visual areas (e.g., V1 and V2) in the levels that are comparable to those accomplished by the supervised neural network model. In contrast, the supervised neural network models yield better neural response predictions in the higher visual areas, compared to the reinforcement learning models. Our preliminary results suggest the future direction of visual neuroscience in which deep reinforcement learning should be included to fill the missing embodiment concept.