 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCTAve: 2D en face Optical Coherence Tomography Angiography Vessel Segmentation in Weakly-Supervised Learning with Locality Augmentation
Jul 25, 2022
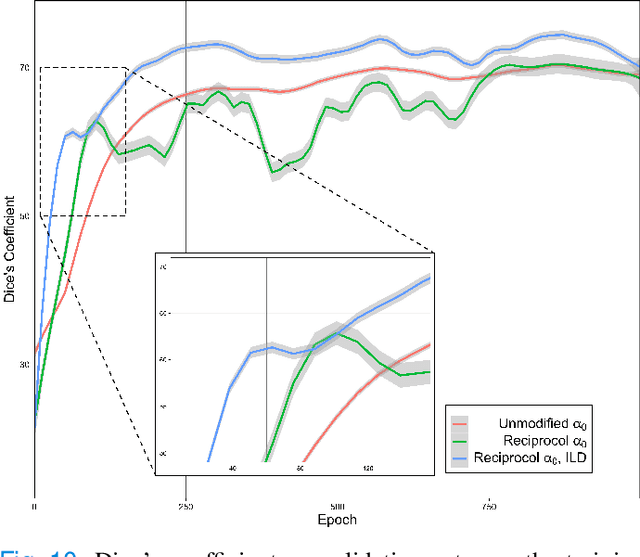

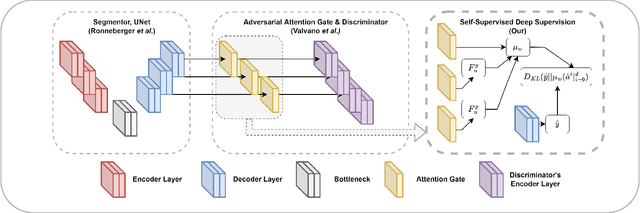
While there have been increased researches using deep learning techniques for the extraction of vascular structure from the 2D en face OCTA, for such approach, it is known that the data annotation process on the curvilinear structure like the retinal vasculature is very costly and time consuming, albeit few tried to address the annotation problem. In this work, we propose the application of the scribble-base weakly-supervised learning method to automate the pixel-level annotation. The proposed method, called OCTAve, combines the weakly-supervised learning using scribble-annotated ground truth augmented with an adversarial and a novel self-supervised deep supervision. Our novel mechanism is designed to utilize the discriminative outputs from the discrimination layer of a UNet-like architecture where the Kullback-Liebler Divergence between the aggregate discriminative outputs and the segmentation map predicate is minimized during the training. This combined method leads to the better localization of the vascular structure as shown in our experiments. We validate our proposed method on the large public datasets i.e., ROSE, OCTA-500. The segmentation performance is compared against both state-of-the-art fully-supervised and scribble-based weakly-supervised approaches. The implementation of our work used in the experiments is located at [LINK].
Information Extraction based on Named Entity for Tourism Corpus
Jan 03, 2020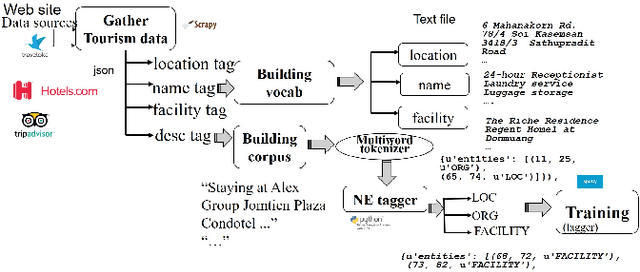
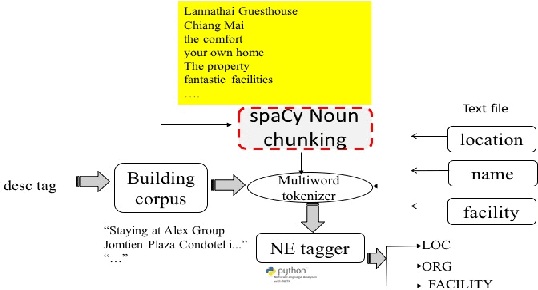
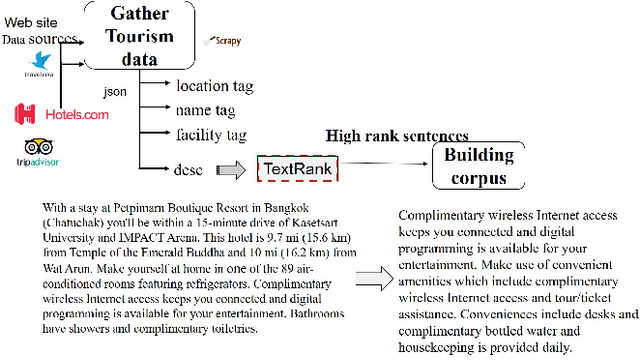
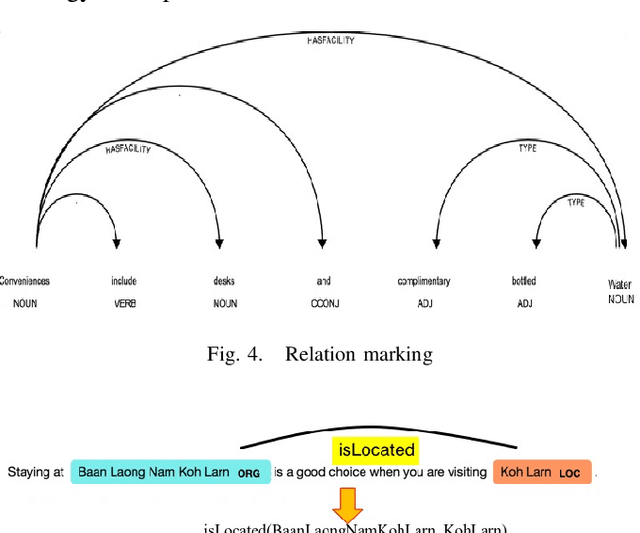
Tourism information is scattered around nowadays. To search for the information, it is usually time consuming to browse through the results from search engine, select and view the details of each accommodation. In this paper, we present a methodology to extract particular information from full text returned from the search engine to facilitate the users. Then, the users can specifically look to the desired relevant information. The approach can be used for the same task in other domains. The main steps are 1) building training data and 2) building recognition model. First, the tourism data is gathered and the vocabularies are built. The raw corpus is used to train for creating vocabulary embedding. Also, it is used for creating annotated data. The process of creating named entity annotation is presented. Then, the recognition model of a given entity type can be built. From the experiments, given hotel description, the model can extract the desired entity,i.e, name, location, facility. The extracted data can further be stored as a structured information, e.g., in the ontology format, for future querying and inference. The model for automatic named entity identification, based on machine learning, yields the error ranging 8%-25%.
* 6 pages, 9 figures