 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Extraction based on Named Entity for Tourism Corpus
Jan 03, 2020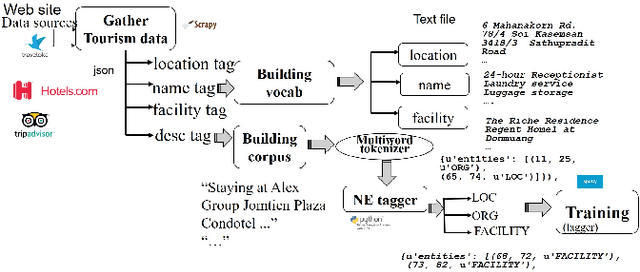
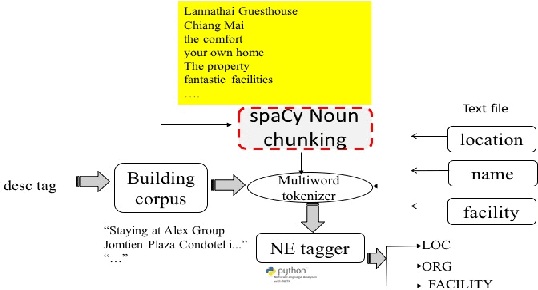
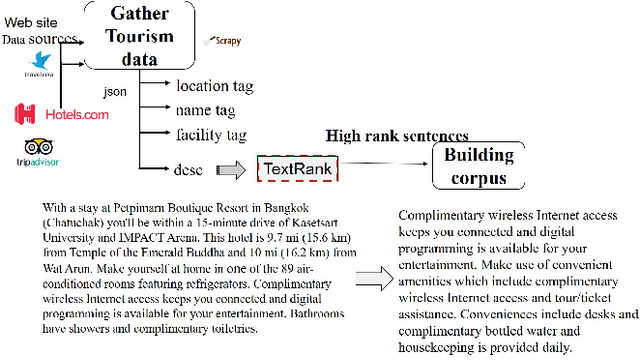
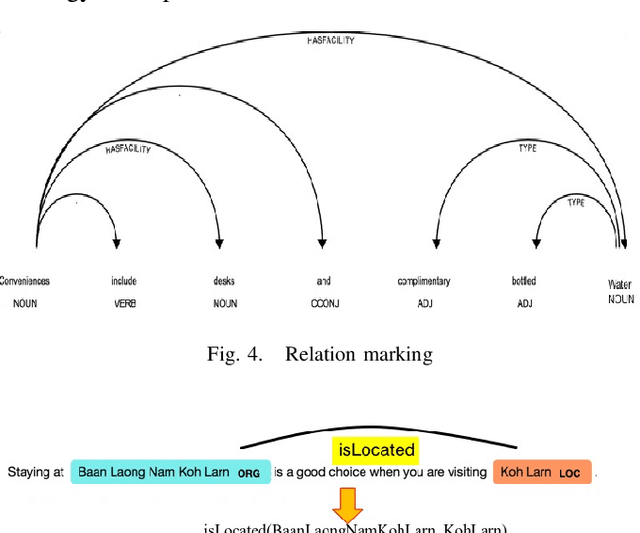
Tourism information is scattered around nowadays. To search for the information, it is usually time consuming to browse through the results from search engine, select and view the details of each accommodation. In this paper, we present a methodology to extract particular information from full text returned from the search engine to facilitate the users. Then, the users can specifically look to the desired relevant information. The approach can be used for the same task in other domains. The main steps are 1) building training data and 2) building recognition model. First, the tourism data is gathered and the vocabularies are built. The raw corpus is used to train for creating vocabulary embedding. Also, it is used for creating annotated data. The process of creating named entity annotation is presented. Then, the recognition model of a given entity type can be built. From the experiments, given hotel description, the model can extract the desired entity,i.e, name, location, facility. The extracted data can further be stored as a structured information, e.g., in the ontology format, for future querying and inference. The model for automatic named entity identification, based on machine learning, yields the error ranging 8%-25%.
* 6 pages, 9 figures