 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan General-Purpose Large Language Models Generalize to English-Thai Machine Translation ?
Oct 22, 2024


Large language models (LLMs) perform well on common tasks but struggle with generalization in low-resource and low-computation settings. We examine this limitation by testing various LLMs and specialized translation models on English-Thai machine translation and code-switching datasets. Our findings reveal that under more strict computational constraints, such as 4-bit quantization, LLMs fail to translate effectively. In contrast, specialized models, with comparable or lower computational requirements, consistently outperform LLMs. This underscores the importance of specialized models for maintaining performance under resource constraints.
On Creating an English-Thai Code-switched Machine Translation in Medical Domain
Oct 21, 2024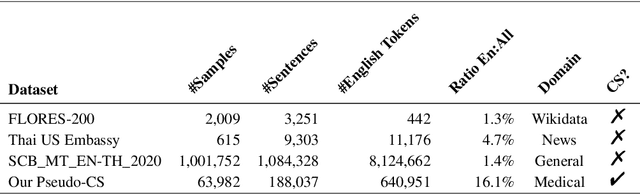

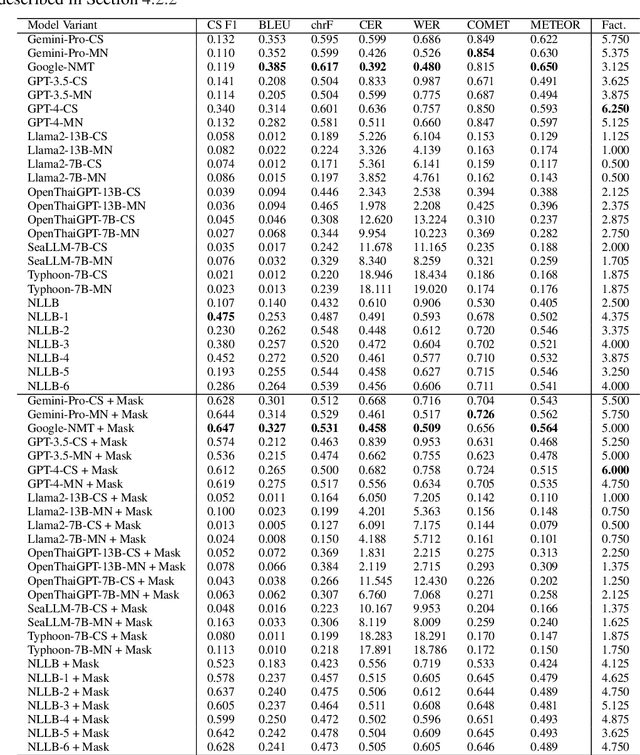
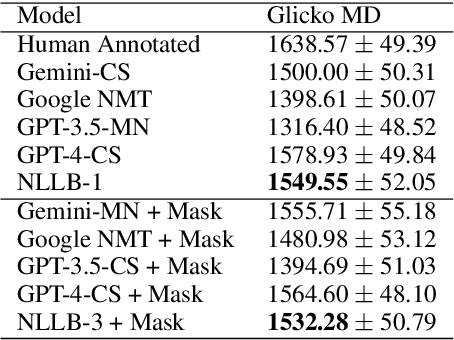
Machine translation (MT) in the medical domain plays a pivotal role in enhancing healthcare quality and disseminating medical knowledge. Despite advancements in English-Thai MT technology, common MT approaches often underperform in the medical field due to their inability to precisely translate medical terminologies. Our research prioritizes not merely improving translation accuracy but also maintaining medical terminology in English within the translated text through code-switched (CS) translation. We developed a method to produce CS medical translation data, fine-tuned a CS translation model with this data, and evaluated its performance against strong baselines, such as Google Neural Machine Translation (NMT) and GPT-3.5/GPT-4. Our model demonstrated competitive performance in automatic metrics and was highly favored in human preference evaluations. Our evaluation result also shows that medical professionals significantly prefer CS translations that maintain critical English terms accurately, even if it slightly compromises fluency. Our code and test set are publicly available https://github.com/preceptorai-org/NLLB_CS_EM_NLP2024.
PACMAN: a framework for pulse oximeter digit detection and reading in a low-resource setting
Dec 09, 2022



In light of the COVID-19 pandemic, patients were required to manually input their daily oxygen saturation (SpO2) and pulse rate (PR) values into a health monitoring system-unfortunately, such a process trend to be an error in typing. Several studies attempted to detect the physiological value from the captured image using optical character recognition (OCR). However, the technology has limited availability with high cost. Thus, this study aimed to propose a novel framework called PACMAN (Pandemic Accelerated Human-Machine Collaboration) with a low-resource deep learning-based computer vision. We compared state-of-the-art object detection algorithms (scaled YOLOv4, YOLOv5, and YOLOR), including the commercial OCR tools for digit recognition on the captured images from pulse oximeter display. All images were derived from crowdsourced data collection with varying quality and alignment. YOLOv5 was the best-performing model against the given model comparison across all datasets, notably the correctly orientated image dataset. We further improved the model performance with the digits auto-orientation algorithm and applied a clustering algorithm to extract SpO2 and PR values. The accuracy performance of YOLOv5 with the implementations was approximately 81.0-89.5%, which was enhanced compared to without any additional implementation. Accordingly, this study highlighted the completion of PACMAN framework to detect and read digits in real-world datasets. The proposed framework has been currently integrated into the patient monitoring system utilized by hospitals nationwide.
OCTAve: 2D en face Optical Coherence Tomography Angiography Vessel Segmentation in Weakly-Supervised Learning with Locality Augmentation
Jul 25, 2022
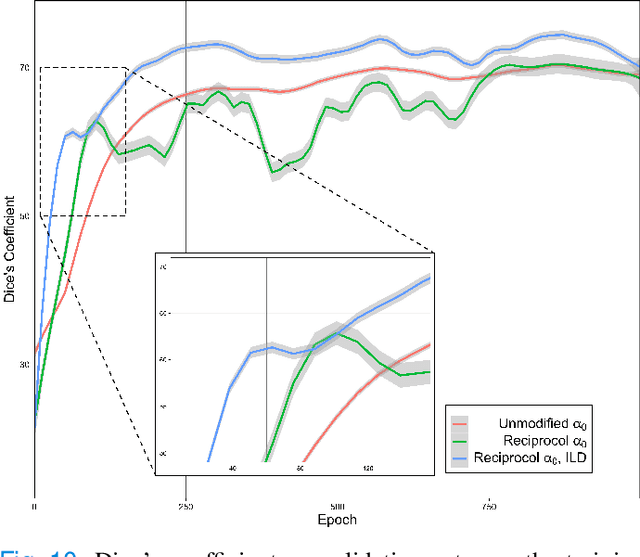

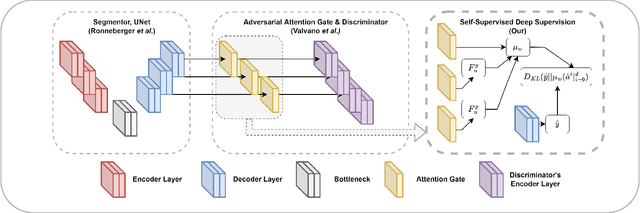
While there have been increased researches using deep learning techniques for the extraction of vascular structure from the 2D en face OCTA, for such approach, it is known that the data annotation process on the curvilinear structure like the retinal vasculature is very costly and time consuming, albeit few tried to address the annotation problem. In this work, we propose the application of the scribble-base weakly-supervised learning method to automate the pixel-level annotation. The proposed method, called OCTAve, combines the weakly-supervised learning using scribble-annotated ground truth augmented with an adversarial and a novel self-supervised deep supervision. Our novel mechanism is designed to utilize the discriminative outputs from the discrimination layer of a UNet-like architecture where the Kullback-Liebler Divergence between the aggregate discriminative outputs and the segmentation map predicate is minimized during the training. This combined method leads to the better localization of the vascular structure as shown in our experiments. We validate our proposed method on the large public datasets i.e., ROSE, OCTA-500. The segmentation performance is compared against both state-of-the-art fully-supervised and scribble-based weakly-supervised approaches. The implementation of our work used in the experiments is located at [LINK].