 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Cooperate with Unseen Agent via Meta-Reinforcement Learning
Nov 05, 2021
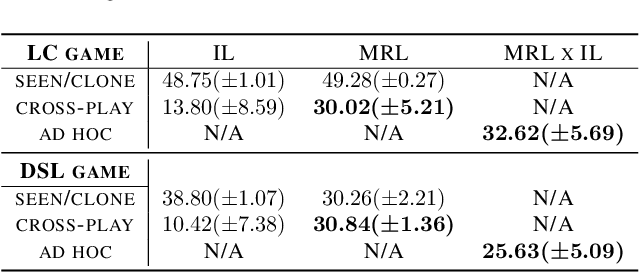

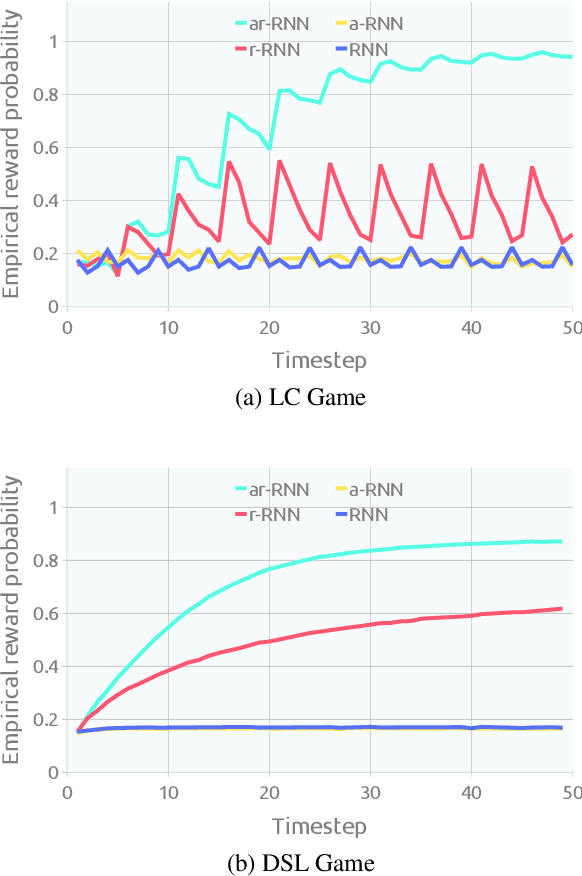
Ad hoc teamwork problem describes situations where an agent has to cooperate with previously unseen agents to achieve a common goal. For an agent to be successful in these scenarios, it has to have a suitable cooperative skill. One could implement cooperative skills into an agent by using domain knowledge to design the agent's behavior. However, in complex domains, domain knowledge might not be available. Therefore, it is worthwhile to explore how to directly learn cooperative skills from data. In this work, we apply meta-reinforcement learning (meta-RL) formulation in the context of the ad hoc teamwork problem. Our empirical results show that such a method could produce robust cooperative agents in two cooperative environments with different cooperative circumstances: social compliance and language interpretation. (This is a full paper of the extended abstract version.)
Deep Reinforcement Learning Models Predict Visual Responses in the Brain: A Preliminary Result
Jun 18, 2021
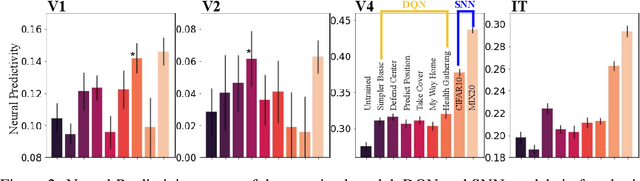
Supervised deep convolutional neural networks (DCNNs) are currently one of the best computational models that can explain how the primate ventral visual stream solves object recognition. However, embodied cognition has not been considered in the existing visual processing models. From the ecological standpoint, humans learn to recognize objects by interacting with them, allowing better classification, specialization, and generalization. Here, we ask if computational models under the embodied learning framework can explain mechanisms underlying object recognition in the primate visual system better than the existing supervised models? To address this question, we use reinforcement learning to train neural network models to play a 3D computer game and we find that these reinforcement learning models achieve neural response prediction accuracy scores in the early visual areas (e.g., V1 and V2) in the levels that are comparable to those accomplished by the supervised neural network model. In contrast, the supervised neural network models yield better neural response predictions in the higher visual areas, compared to the reinforcement learning models. Our preliminary results suggest the future direction of visual neuroscience in which deep reinforcement learning should be included to fill the missing embodiment concept.
MIN2Net: End-to-End Multi-Task Learning for Subject-Independent Motor Imagery EEG Classification
Feb 07, 2021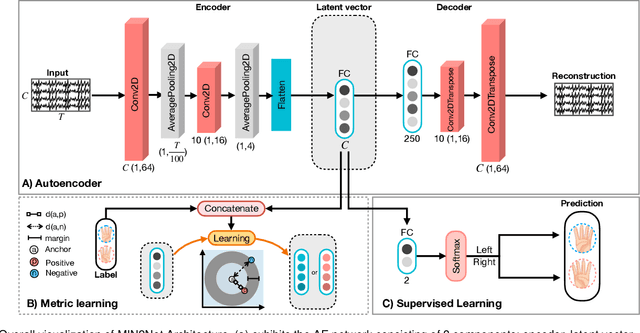
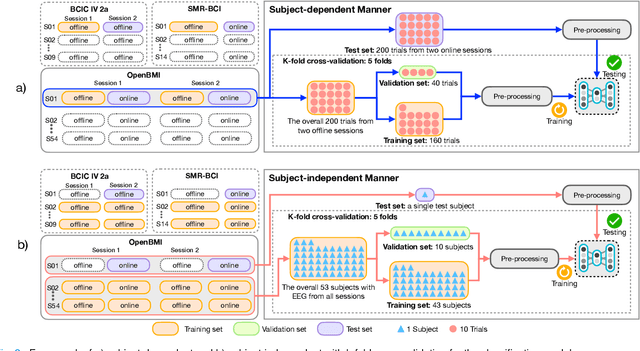
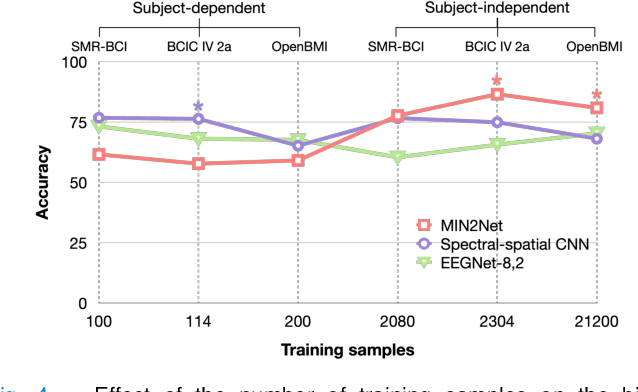
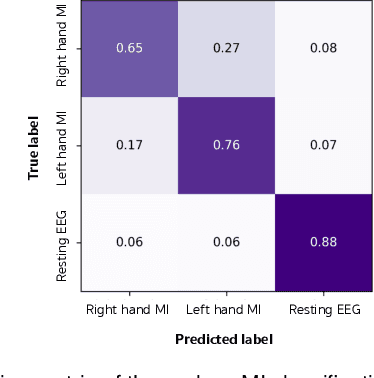
Advances in the motor imagery (MI)-based brain-computer interfaces (BCIs) allow control of several applications by decoding neurophysiological phenomena, which are usually recorded by electroencephalography (EEG) using a non-invasive technique. Despite great advances in MI-based BCI, EEG rhythms are specific to a subject and various changes over time. These issues point to significant challenges to enhance the classification performance, especially in a subject-independent manner. To overcome these challenges, we propose MIN2Net, a novel end-to-end multi-task learning to tackle this task. We integrate deep metric learning into a multi-task autoencoder to learn a compact and discriminative latent representation from EEG and perform classification simultaneously. This approach reduces the complexity in pre-processing, results in significant performance improvement on EEG classification. Experimental results in a subject-independent manner show that MIN2Net outperforms the state-of-the-art techniques, achieving an accuracy improvement of 11.65%, 1.03%, and 10.53% on the BCI competition IV 2a, SMR-BCI, and OpenBMI datasets, respectively. We demonstrate that MIN2Net improves discriminative information in the latent representation. This study indicates the possibility and practicality of using this model to develop MI-based BCI applications for new users without the need for calibration.
MetaSleepLearner: Fast Adaptation of Bio-signals-Based Sleep Stage Classifier to New Individual Subject Using Meta-Learning
Apr 14, 2020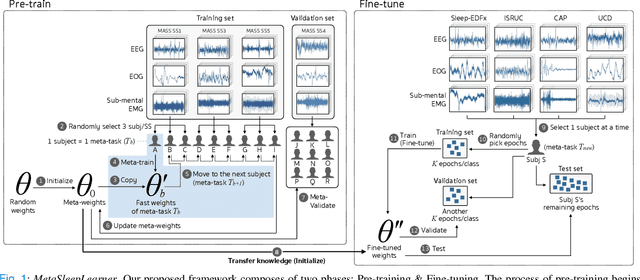
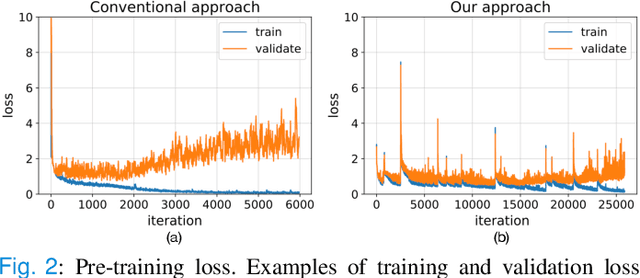
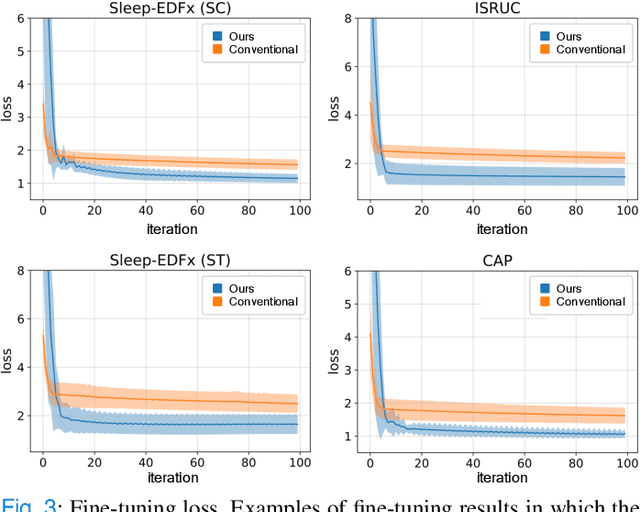
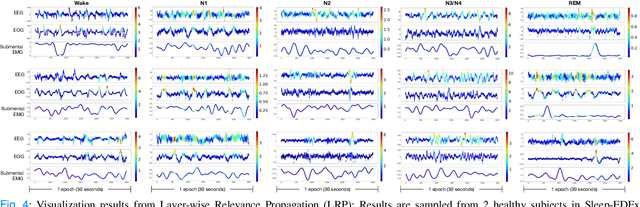
Objective: Identifying bio-signals based-sleep stages requires time-consuming and tedious labor of skilled clinicians. Deep learning approaches have been introduced in order to challenge the automatic sleep stage classification conundrum. However, disadvantages can be posed in replacing the clinicians with the automatic system. Thus, we aim to develop a framework, capable of assisting the clinicians and lessening the workload. Methods: We proposed the transfer learning framework entitled MetaSleepLearner, using a Model Agnostic Meta-Learning (MAML), in order to transfer the acquired sleep staging knowledge from a large dataset to new individual subject. The capability of MAML was elicited for this task by allowing clinicians to label for a few samples and let the rest be handled by the system. Layer-wise Relevance Propagation (LRP) was also applied to understand the learning course of our approach. Results: In all acquired datasets, in comparison to the conventional approach, MetaSleepLearner achieved a range of 6.15 % to 12.12 % improvement with statistical difference in the mean of both approaches. The illustration of the model interpretation after the adaptation to each subject also confirmed that the performance was directed towards reasonable learning. Conclusion: MetaSleepLearner outperformed the conventional approach as a result from the fine-tuning using the recordings of both healthy subjects and patients. Significance: This is the first paper that investigated a non-conventional pre-training method, MAML, in this task, resulting in a framework for human-machine collaboration in sleep stage classification, easing the burden of the clinicians in labelling the sleep stages through only several epochs rather than an entire recording.
An Explicit Local and Global Representation Disentanglement Framework with Applications in Deep Clustering and Unsupervised Object Detection
Feb 24, 2020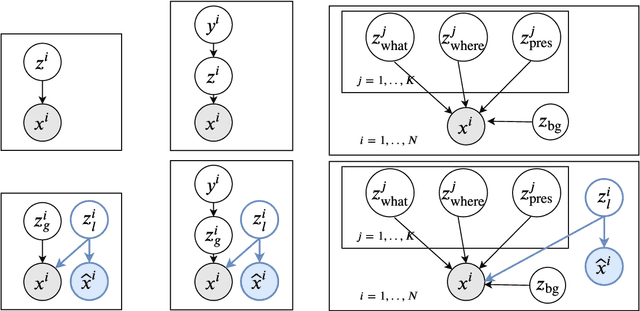

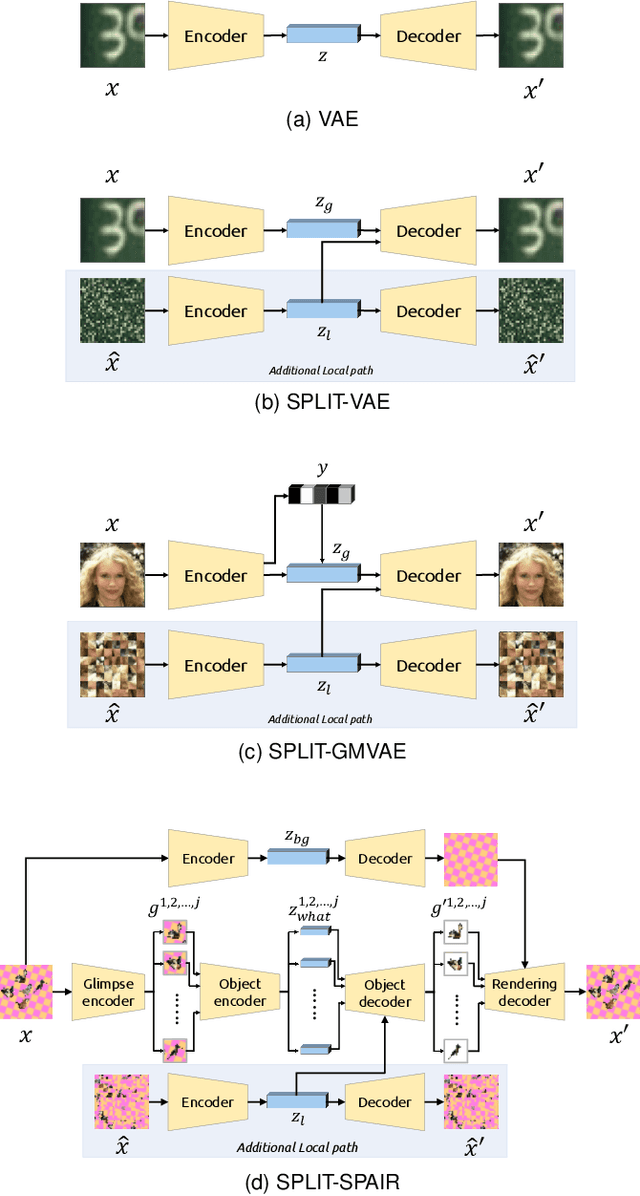
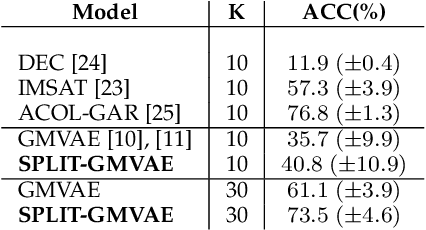
Visual data can be understood at different levels of granularity, where global features correspond to semantic-level information and local features correspond to texture patterns. In this work, we propose a framework, called SPLIT, which allows us to disentangle local and global information into two separate sets of latent variables within the variational autoencoder (VAE) framework. Our framework adds generative assumption to the VAE by requiring a subset of the latent variables to generate an auxiliary set of observable data. This additional generative assumption primes the latent variables to local information and encourages the other latent variables to represent global information. We examine three different flavours of VAEs with different generative assumptions. We show that the framework can effectively disentangle local and global information within these models leads to improved representation, with better clustering and unsupervised object detection benchmarks. Finally, we establish connections between SPLIT and recent research in cognitive neuroscience regarding the disentanglement in human visual perception. The code for our experiments is at https://github.com/51616/split-vae .
Feature Control as Intrinsic Motivation for Hierarchical Reinforcement Learning
Nov 22, 2017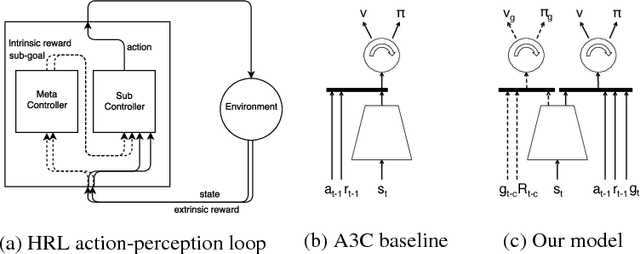
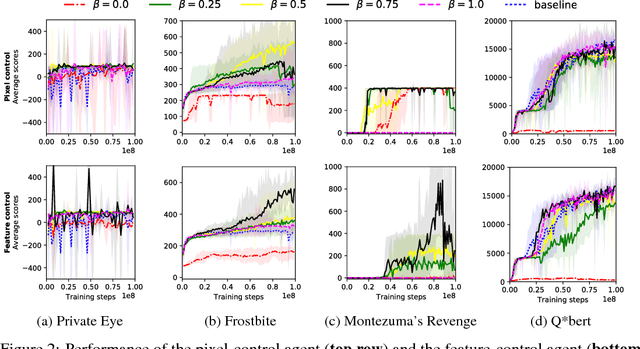
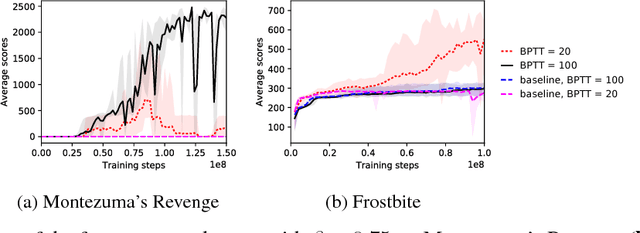
The problem of sparse rewards is one of the hardest challenges in contemporary reinforcement learning. Hierarchical reinforcement learning (HRL) tackles this problem by using a set of temporally-extended actions, or options, each of which has its own subgoal. These subgoals are normally handcrafted for specific tasks. Here, though, we introduce a generic class of subgoals with broad applicability in the visual domain. Underlying our approach (in common with work using "auxiliary tasks") is the hypothesis that the ability to control aspects of the environment is an inherently useful skill to have. We incorporate such subgoals in an end-to-end hierarchical reinforcement learning system and test two variants of our algorithm on a number of games from the Atari suite. We highlight the advantage of our approach in one of the hardest games -- Montezuma's revenge -- for which the ability to handle sparse rewards is key. Our agent learns several times faster than the current state-of-the-art HRL agent in this game, reaching a similar level of performance. UPDATE 22/11/17: We found that a standard A3C agent with a simple shaped reward, i.e. extrinsic reward + feature control intrinsic reward, has comparable performance to our agent in Montezuma Revenge. In light of the new experiments performed, the advantage of our HRL approach can be attributed more to its ability to learn useful features from intrinsic rewards rather than its ability to explore and reuse abstracted skills with hierarchical components. This has led us to a new conclusion about the result.
Classifying Options for Deep Reinforcement Learning
Jun 19, 2017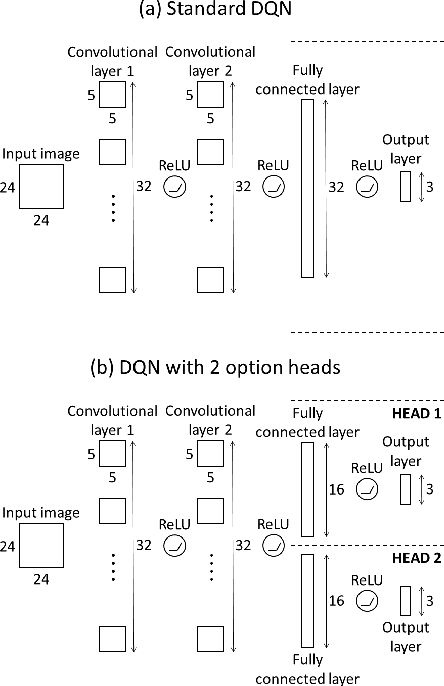

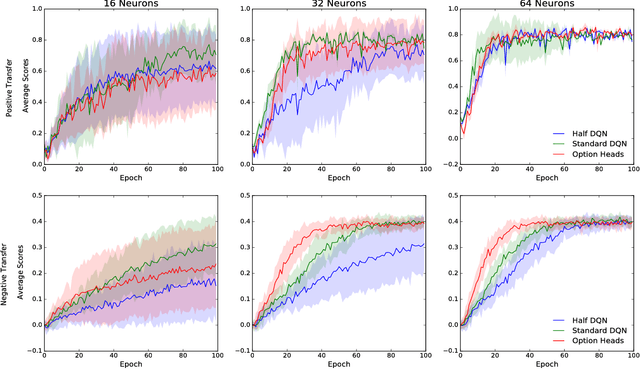
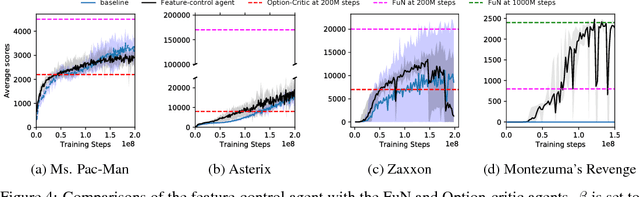
In this paper we combine one method for hierarchical reinforcement learning - the options framework - with deep Q-networks (DQNs) through the use of different "option heads" on the policy network, and a supervisory network for choosing between the different options. We utilise our setup to investigate the effects of architectural constraints in subtasks with positive and negative transfer, across a range of network capacities. We empirically show that our augmented DQN has lower sample complexity when simultaneously learning subtasks with negative transfer, without degrading performance when learning subtasks with positive transfer.
Deep Unsupervised Clustering with Gaussian Mixture Variational Autoencoders
Jan 13, 2017
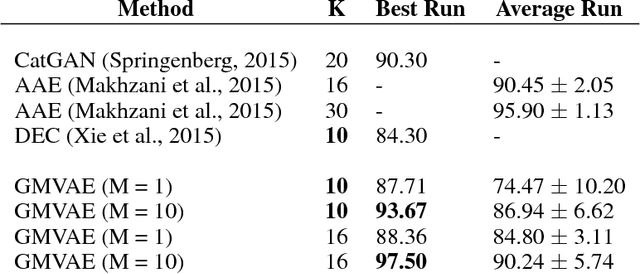
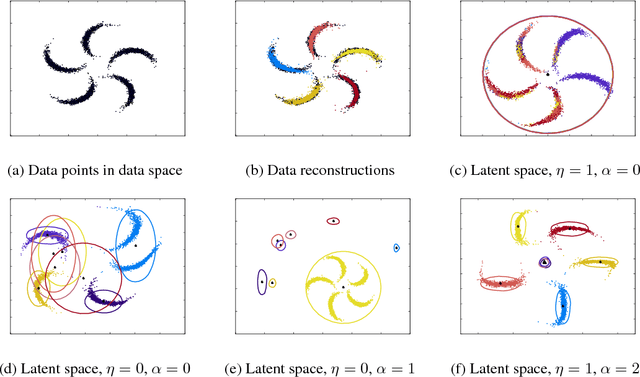

We study a variant of the variational autoencoder model (VAE) with a Gaussian mixture as a prior distribution, with the goal of performing unsupervised clustering through deep generative models. We observe that the known problem of over-regularisation that has been shown to arise in regular VAEs also manifests itself in our model and leads to cluster degeneracy. We show that a heuristic called minimum information constraint that has been shown to mitigate this effect in VAEs can also be applied to improve unsupervised clustering performance with our model. Furthermore we analyse the effect of this heuristic and provide an intuition of the various processes with the help of visualizations. Finally, we demonstrate the performance of our model on synthetic data, MNIST and SVHN, showing that the obtained clusters are distinct, interpretable and result in achieving competitive performance on unsupervised clustering to the state-of-the-art results.