 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Explicit Local and Global Representation Disentanglement Framework with Applications in Deep Clustering and Unsupervised Object Detection
Paper and Code
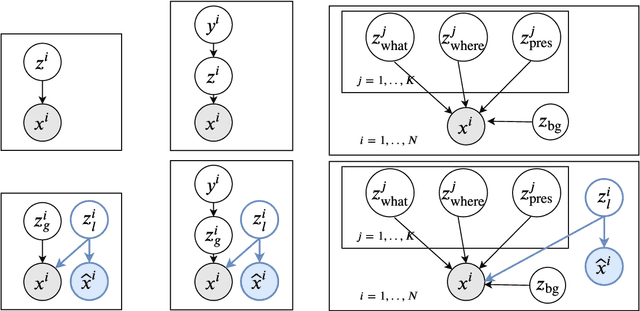

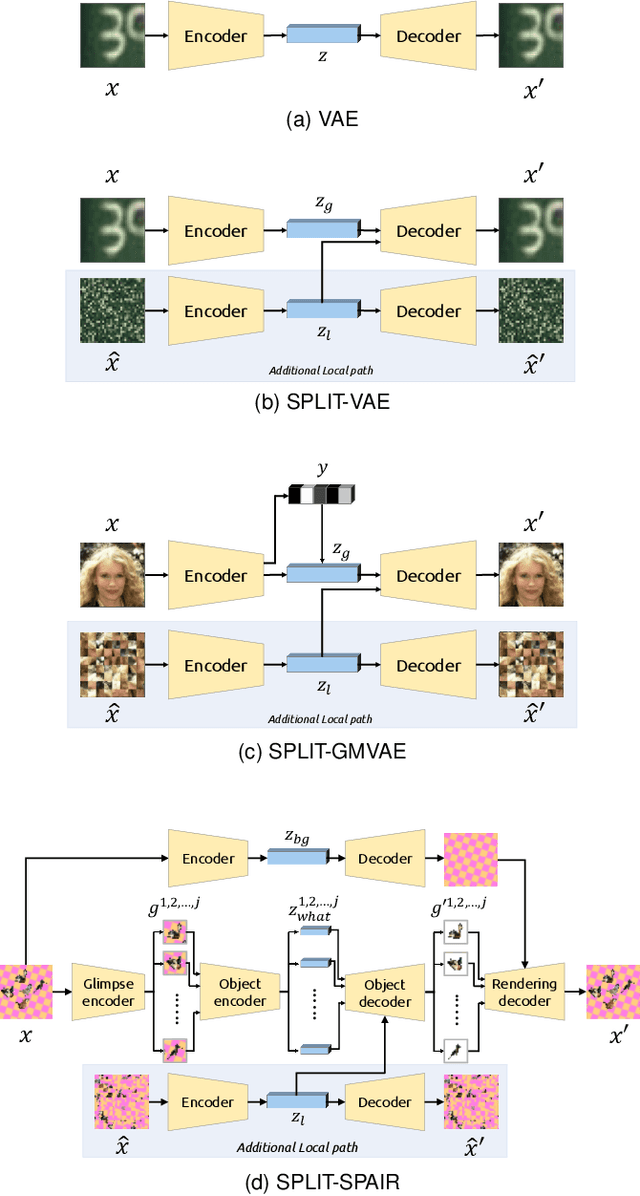
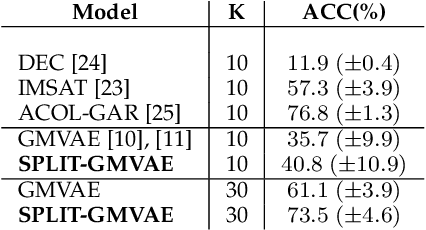
Visual data can be understood at different levels of granularity, where global features correspond to semantic-level information and local features correspond to texture patterns. In this work, we propose a framework, called SPLIT, which allows us to disentangle local and global information into two separate sets of latent variables within the variational autoencoder (VAE) framework. Our framework adds generative assumption to the VAE by requiring a subset of the latent variables to generate an auxiliary set of observable data. This additional generative assumption primes the latent variables to local information and encourages the other latent variables to represent global information. We examine three different flavours of VAEs with different generative assumptions. We show that the framework can effectively disentangle local and global information within these models leads to improved representation, with better clustering and unsupervised object detection benchmarks. Finally, we establish connections between SPLIT and recent research in cognitive neuroscience regarding the disentanglement in human visual perception. The code for our experiments is at https://github.com/51616/split-vae .