 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynBench: A Benchmark for Differentially Private Text Generation
Sep 18, 2025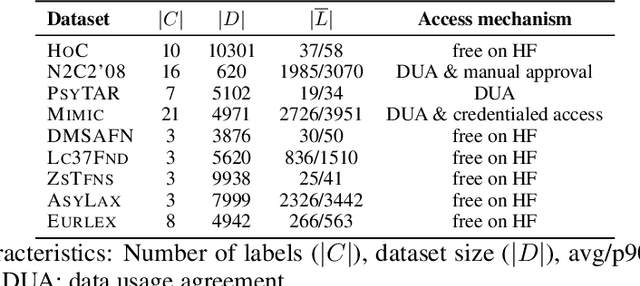
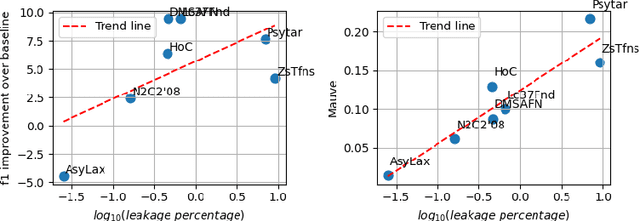
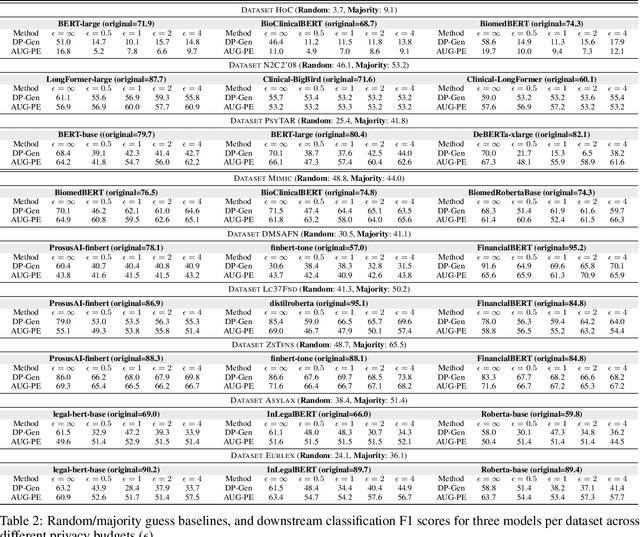
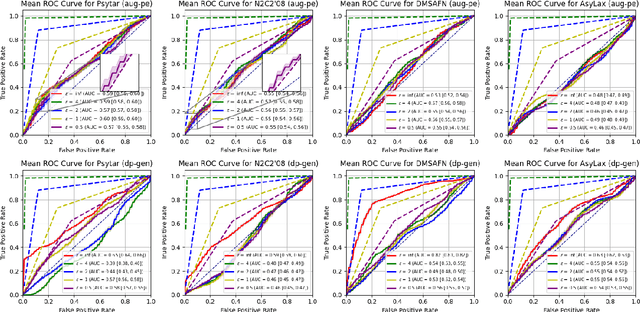
Data-driven decision support in high-stakes domains like healthcare and finance faces significant barriers to data sharing due to regulatory, institutional, and privacy concerns. While recent generative AI models, such as large language models, have shown impressive performance in open-domain tasks, their adoption in sensitive environments remains limited by unpredictable behaviors and insufficient privacy-preserving datasets for benchmarking. Existing anonymization methods are often inadequate, especially for unstructured text, as redaction and masking can still allow re-identification. Differential Privacy (DP) offers a principled alternative, enabling the generation of synthetic data with formal privacy assurances. In this work, we address these challenges through three key contributions. First, we introduce a comprehensive evaluation framework with standardized utility and fidelity metrics, encompassing nine curated datasets that capture domain-specific complexities such as technical jargon, long-context dependencies, and specialized document structures. Second, we conduct a large-scale empirical study benchmarking state-of-the-art DP text generation methods and LLMs of varying sizes and different fine-tuning strategies, revealing that high-quality domain-specific synthetic data generation under DP constraints remains an unsolved challenge, with performance degrading as domain complexity increases. Third, we develop a membership inference attack (MIA) methodology tailored for synthetic text, providing first empirical evidence that the use of public datasets - potentially present in pre-training corpora - can invalidate claimed privacy guarantees. Our findings underscore the urgent need for rigorous privacy auditing and highlight persistent gaps between open-domain and specialist evaluations, informing responsible deployment of generative AI in privacy-sensitive, high-stakes settings.
High-resolution 3D Maps of Left Atrial Displacements using an Unsupervised Image Registration Neural Network
Sep 05, 2023

Functional analysis of the left atrium (LA) plays an increasingly important role in the prognosis and diagnosis of cardiovascular diseases. Echocardiography-based measurements of LA dimensions and strains are useful biomarkers, but they provide an incomplete picture of atrial deformations. High-resolution dynamic magnetic resonance images (Cine MRI) offer the opportunity to examine LA motion and deformation in 3D, at higher spatial resolution and with full LA coverage. However, there are no dedicated tools to automatically characterise LA motion in 3D. Thus, we propose a tool that automatically segments the LA and extracts the displacement fields across the cardiac cycle. The pipeline is able to accurately track the LA wall across the cardiac cycle with an average Hausdorff distance of $2.51 \pm 1.3~mm$ and Dice score of $0.96 \pm 0.02$.
Diversity-based Trajectory and Goal Selection with Hindsight Experience Replay
Aug 17, 2021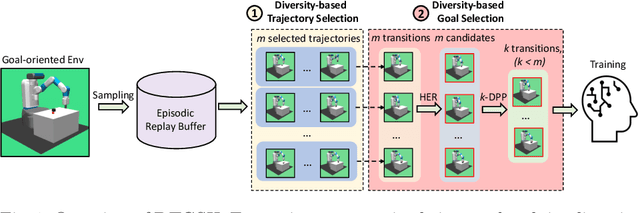
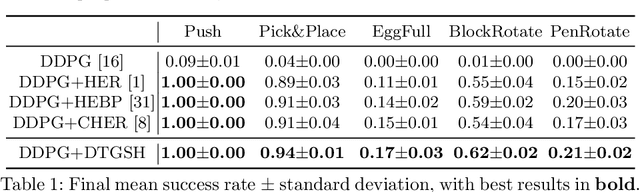
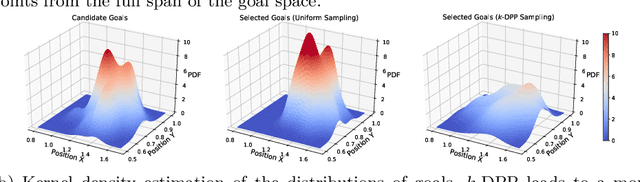

Hindsight experience replay (HER) is a goal relabelling technique typically used with off-policy deep reinforcement learning algorithms to solve goal-oriented tasks; it is well suited to robotic manipulation tasks that deliver only sparse rewards. In HER, both trajectories and transitions are sampled uniformly for training. However, not all of the agent's experiences contribute equally to training, and so naive uniform sampling may lead to inefficient learning. In this paper, we propose diversity-based trajectory and goal selection with HER (DTGSH). Firstly, trajectories are sampled according to the diversity of the goal states as modelled by determinantal point processes (DPPs). Secondly, transitions with diverse goal states are selected from the trajectories by using k-DPPs. We evaluate DTGSH on five challenging robotic manipulation tasks in simulated robot environments, where we show that our method can learn more quickly and reach higher performance than other state-of-the-art approaches on all tasks.
Episodic Self-Imitation Learning with Hindsight
Nov 26, 2020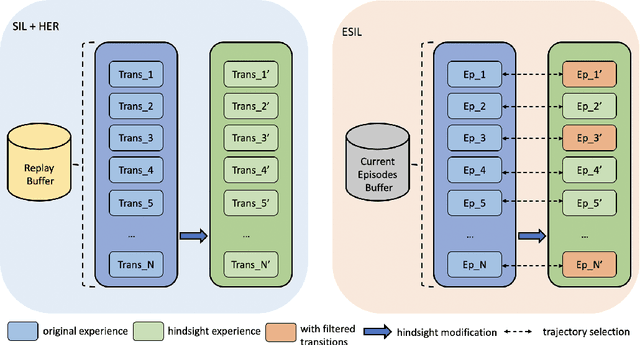
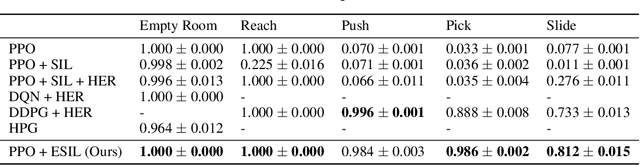
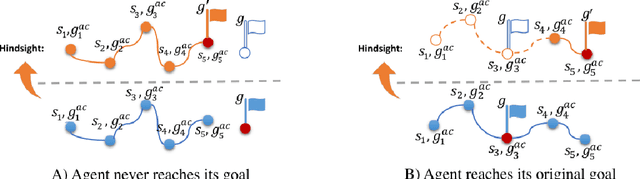

Episodic self-imitation learning, a novel self-imitation algorithm with a trajectory selection module and an adaptive loss function, is proposed to speed up reinforcement learning. Compared to the original self-imitation learning algorithm, which samples good state-action pairs from the experience replay buffer, our agent leverages entire episodes with hindsight to aid self-imitation learning. A selection module is introduced to filter uninformative samples from each episode of the update. The proposed method overcomes the limitations of the standard self-imitation learning algorithm, a transitions-based method which performs poorly in handling continuous control environments with sparse rewards. From the experiments, episodic self-imitation learning is shown to perform better than baseline on-policy algorithms, achieving comparable performance to state-of-the-art off-policy algorithms in several simulated robot control tasks. The trajectory selection module is shown to prevent the agent learning undesirable hindsight experiences. With the capability of solving sparse reward problems in continuous control settings, episodic self-imitation learning has the potential to be applied to real-world problems that have continuous action spaces, such as robot guidance and manipulation.
Analysing Deep Reinforcement Learning Agents Trained with Domain Randomisation
Dec 18, 2019


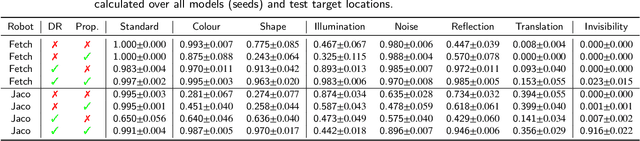
Deep reinforcement learning has the potential to train robots to perform complex tasks in the real world without requiring accurate models of the robot or its environment. A practical approach is to train agents in simulation, and then transfer them to the real world. One of the most popular methods for achieving this is to use domain randomisation, which involves randomly perturbing various aspects of a simulated environment in order to make trained agents robust to the reality gap between the simulator and the real world. However, less work has gone into understanding such agents-which are deployed in the real world-beyond task performance. In this work we examine such agents, through qualitative and quantitative comparisons between agents trained with and without visual domain randomisation, in order to provide a better understanding of how they function. In this work, we train agents for Fetch and Jaco robots on a visuomotor control task, and evaluate how well they generalise using different unit tests. We tie this with interpretability techniques, providing both quantitative and qualitative data. Finally, we investigate the internals of the trained agents by examining their weights and activations. Our results show that the primary outcome of domain randomisation is more redundant, entangled representations, accompanied with significant statistical/structural changes in the weights; moreover, the types of changes are heavily influenced by the task setup and presence of additional proprioceptive inputs. Furthermore, even with an improved saliency method introduced in this work, we show that qualitative studies may not always correspond with quantitative measures, necessitating the use of a wide suite of inspection tools in order to provide sufficient insights into the behaviour of trained agents.
Sample-Efficient Reinforcement Learning with Maximum Entropy Mellowmax Episodic Control
Nov 21, 2019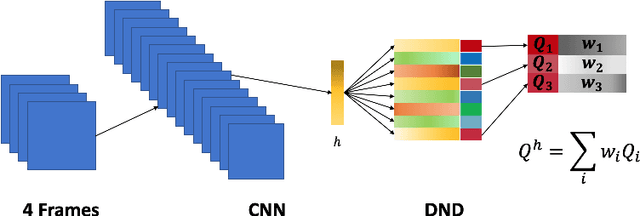
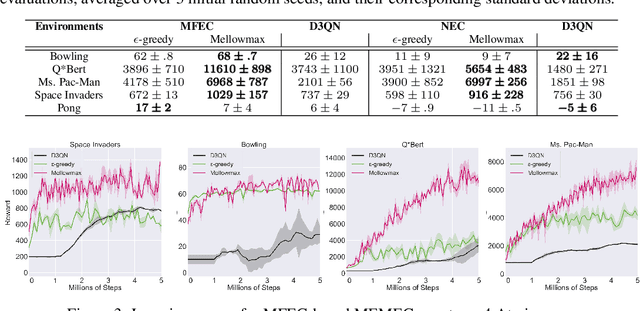

Deep networks have enabled reinforcement learning to scale to more complex and challenging domains, but these methods typically require large quantities of training data. An alternative is to use sample-efficient episodic control methods: neuro-inspired algorithms which use non-/semi-parametric models that predict values based on storing and retrieving previously experienced transitions. One way to further improve the sample efficiency of these approaches is to use more principled exploration strategies. In this work, we therefore propose maximum entropy mellowmax episodic control (MEMEC), which samples actions according to a Boltzmann policy with a state-dependent temperature. We demonstrate that MEMEC outperforms other uncertainty- and softmax-based exploration methods on classic reinforcement learning environments and Atari games, achieving both more rapid learning and higher final rewards.
Memory-Efficient Episodic Control Reinforcement Learning with Dynamic Online k-means
Nov 21, 2019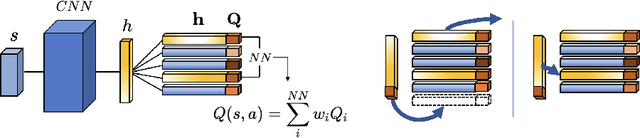



Recently, neuro-inspired episodic control (EC) methods have been developed to overcome the data-inefficiency of standard deep reinforcement learning approaches. Using non-/semi-parametric models to estimate the value function, they learn rapidly, retrieving cached values from similar past states. In realistic scenarios, with limited resources and noisy data, maintaining meaningful representations in memory is essential to speed up the learning and avoid catastrophic forgetting. Unfortunately, EC methods have a large space and time complexity. We investigate different solutions to these problems based on prioritising and ranking stored states, as well as online clustering techniques. We also propose a new dynamic online k-means algorithm that is both computationally-efficient and yields significantly better performance at smaller memory sizes; we validate this approach on classic reinforcement learning environments and Atari games.
Denoising Adversarial Autoencoders
Jan 04, 2018
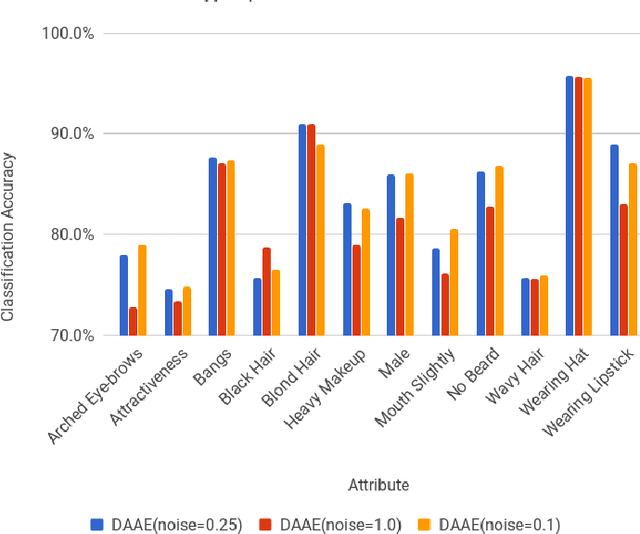


Unsupervised learning is of growing interest because it unlocks the potential held in vast amounts of unlabelled data to learn useful representations for inference. Autoencoders, a form of generative model, may be trained by learning to reconstruct unlabelled input data from a latent representation space. More robust representations may be produced by an autoencoder if it learns to recover clean input samples from corrupted ones. Representations may be further improved by introducing regularisation during training to shape the distribution of the encoded data in latent space. We suggest denoising adversarial autoencoders, which combine denoising and regularisation, shaping the distribution of latent space using adversarial training. We introduce a novel analysis that shows how denoising may be incorporated into the training and sampling of adversarial autoencoders. Experiments are performed to assess the contributions that denoising makes to the learning of representations for classification and sample synthesis. Our results suggest that autoencoders trained using a denoising criterion achieve higher classification performance, and can synthesise samples that are more consistent with the input data than those trained without a corruption process.
A Recursive Bayesian Approach To Describe Retinal Vasculature Geometry
Nov 28, 2017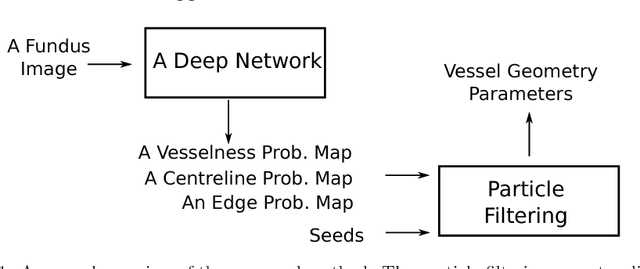

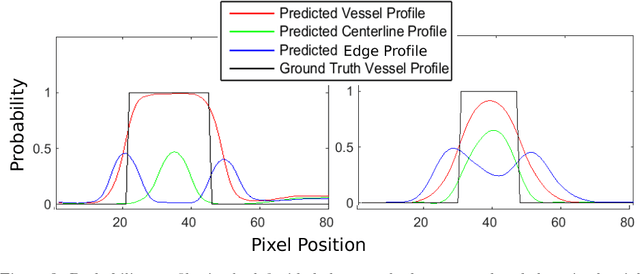
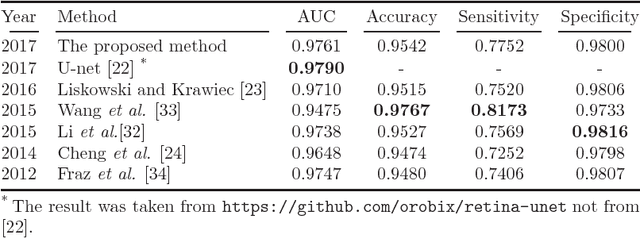
Demographic studies suggest that changes in the retinal vasculature geometry, especially in vessel width, are associated with the incidence or progression of eye-related or systemic diseases. To date, the main information source for width estimation from fundus images has been the intensity profile between vessel edges. However, there are many factors affecting the intensity profile: pathologies, the central light reflex and local illumination levels, to name a few. In this study, we introduce three information sources for width estimation. These are the probability profiles of vessel interior, centreline and edge locations generated by a deep network. The probability profiles provide direct access to vessel geometry and are used in the likelihood calculation for a Bayesian method, particle filtering. We also introduce a geometric model which can handle non-ideal conditions of the probability profiles. Our experiments conducted on the REVIEW dataset yielded consistent estimates of vessel width, even in cases when one of the vessel edges is difficult to identify. Moreover, our results suggest that the method is better than human observers at locating edges of low contrast vessels.
A Brief Survey of Deep Reinforcement Learning
Sep 28, 2017
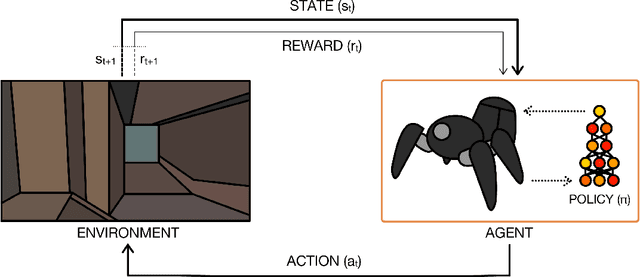

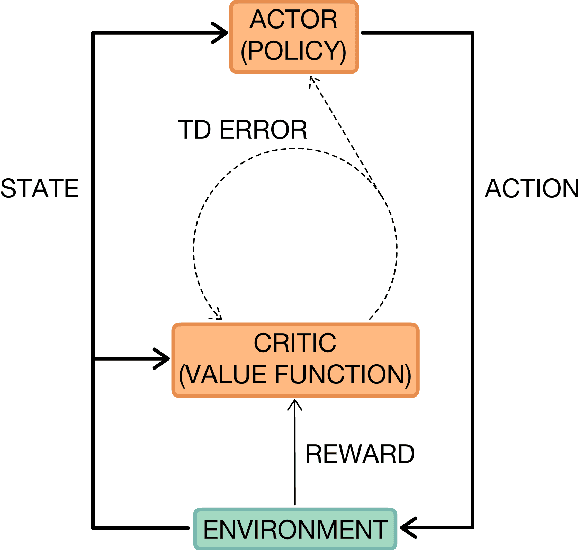
Deep reinforcement learning is poised to revolutionise the field of AI and represents a step towards building autonomous systems with a higher level understanding of the visual world. Currently, deep learning is enabling reinforcement learning to scale to problems that were previously intractable, such as learning to play video games directly from pixels. Deep reinforcement learning algorithms are also applied to robotics, allowing control policies for robots to be learned directly from camera inputs in the real world. In this survey, we begin with an introduction to the general field of reinforcement learning, then progress to the main streams of value-based and policy-based methods. Our survey will cover central algorithms in deep reinforcement learning, including the deep $Q$-network, trust region policy optimisation, and asynchronous advantage actor-critic. In parallel, we highlight the unique advantages of deep neural networks, focusing on visual understanding via reinforcement learning. To conclude, we describe several current areas of research within the field.