 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient Reinforcement Learning with Maximum Entropy Mellowmax Episodic Control
Nov 21, 2019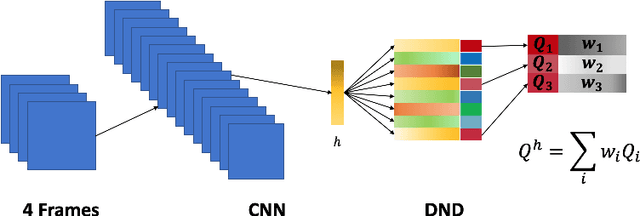
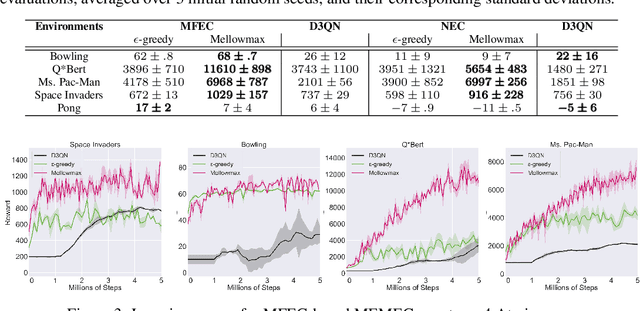

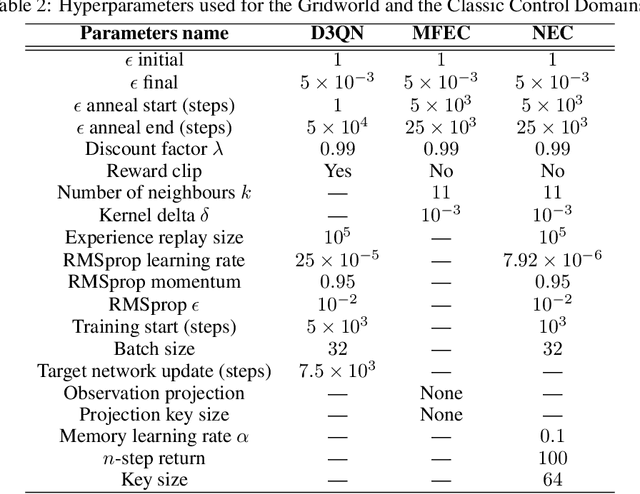
Deep networks have enabled reinforcement learning to scale to more complex and challenging domains, but these methods typically require large quantities of training data. An alternative is to use sample-efficient episodic control methods: neuro-inspired algorithms which use non-/semi-parametric models that predict values based on storing and retrieving previously experienced transitions. One way to further improve the sample efficiency of these approaches is to use more principled exploration strategies. In this work, we therefore propose maximum entropy mellowmax episodic control (MEMEC), which samples actions according to a Boltzmann policy with a state-dependent temperature. We demonstrate that MEMEC outperforms other uncertainty- and softmax-based exploration methods on classic reinforcement learning environments and Atari games, achieving both more rapid learning and higher final rewards.
Memory-Efficient Episodic Control Reinforcement Learning with Dynamic Online k-means
Nov 21, 2019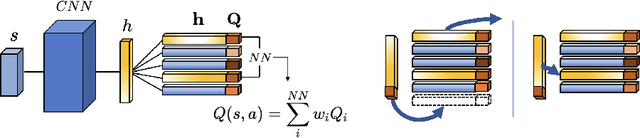



Recently, neuro-inspired episodic control (EC) methods have been developed to overcome the data-inefficiency of standard deep reinforcement learning approaches. Using non-/semi-parametric models to estimate the value function, they learn rapidly, retrieving cached values from similar past states. In realistic scenarios, with limited resources and noisy data, maintaining meaningful representations in memory is essential to speed up the learning and avoid catastrophic forgetting. Unfortunately, EC methods have a large space and time complexity. We investigate different solutions to these problems based on prioritising and ranking stored states, as well as online clustering techniques. We also propose a new dynamic online k-means algorithm that is both computationally-efficient and yields significantly better performance at smaller memory sizes; we validate this approach on classic reinforcement learning environments and Atari games.