 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAya Vision: Advancing the Frontier of Multilingual Multimodality
May 13, 2025Building multimodal language models is fundamentally challenging: it requires aligning vision and language modalities, curating high-quality instruction data, and avoiding the degradation of existing text-only capabilities once vision is introduced. These difficulties are further magnified in the multilingual setting, where the need for multimodal data in different languages exacerbates existing data scarcity, machine translation often distorts meaning, and catastrophic forgetting is more pronounced. To address the aforementioned challenges, we introduce novel techniques spanning both data and modeling. First, we develop a synthetic annotation framework that curates high-quality, diverse multilingual multimodal instruction data, enabling Aya Vision models to produce natural, human-preferred responses to multimodal inputs across many languages. Complementing this, we propose a cross-modal model merging technique that mitigates catastrophic forgetting, effectively preserving text-only capabilities while simultaneously enhancing multimodal generative performance. Aya-Vision-8B achieves best-in-class performance compared to strong multimodal models such as Qwen-2.5-VL-7B, Pixtral-12B, and even much larger Llama-3.2-90B-Vision. We further scale this approach with Aya-Vision-32B, which outperforms models more than twice its size, such as Molmo-72B and LLaMA-3.2-90B-Vision. Our work advances multilingual progress on the multi-modal frontier, and provides insights into techniques that effectively bend the need for compute while delivering extremely high performance.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Sample-Efficient Reinforcement Learning with Maximum Entropy Mellowmax Episodic Control
Nov 21, 2019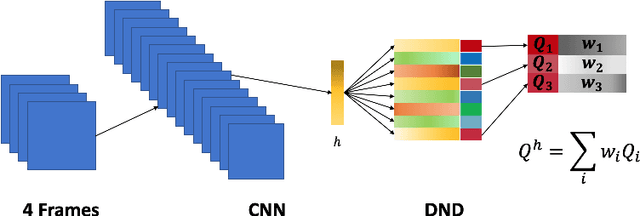
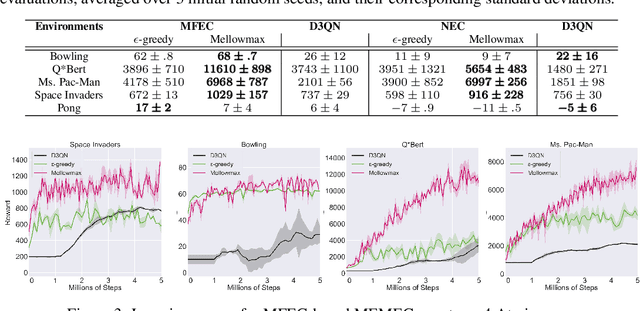

Deep networks have enabled reinforcement learning to scale to more complex and challenging domains, but these methods typically require large quantities of training data. An alternative is to use sample-efficient episodic control methods: neuro-inspired algorithms which use non-/semi-parametric models that predict values based on storing and retrieving previously experienced transitions. One way to further improve the sample efficiency of these approaches is to use more principled exploration strategies. In this work, we therefore propose maximum entropy mellowmax episodic control (MEMEC), which samples actions according to a Boltzmann policy with a state-dependent temperature. We demonstrate that MEMEC outperforms other uncertainty- and softmax-based exploration methods on classic reinforcement learning environments and Atari games, achieving both more rapid learning and higher final rewards.
Memory-Efficient Episodic Control Reinforcement Learning with Dynamic Online k-means
Nov 21, 2019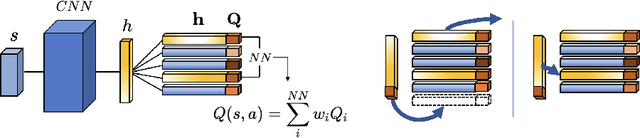



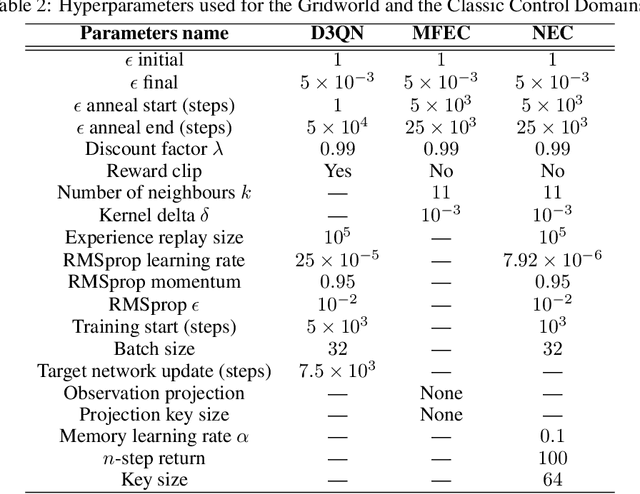
Recently, neuro-inspired episodic control (EC) methods have been developed to overcome the data-inefficiency of standard deep reinforcement learning approaches. Using non-/semi-parametric models to estimate the value function, they learn rapidly, retrieving cached values from similar past states. In realistic scenarios, with limited resources and noisy data, maintaining meaningful representations in memory is essential to speed up the learning and avoid catastrophic forgetting. Unfortunately, EC methods have a large space and time complexity. We investigate different solutions to these problems based on prioritising and ranking stored states, as well as online clustering techniques. We also propose a new dynamic online k-means algorithm that is both computationally-efficient and yields significantly better performance at smaller memory sizes; we validate this approach on classic reinforcement learning environments and Atari games.