 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAya Vision: Advancing the Frontier of Multilingual Multimodality
May 13, 2025Building multimodal language models is fundamentally challenging: it requires aligning vision and language modalities, curating high-quality instruction data, and avoiding the degradation of existing text-only capabilities once vision is introduced. These difficulties are further magnified in the multilingual setting, where the need for multimodal data in different languages exacerbates existing data scarcity, machine translation often distorts meaning, and catastrophic forgetting is more pronounced. To address the aforementioned challenges, we introduce novel techniques spanning both data and modeling. First, we develop a synthetic annotation framework that curates high-quality, diverse multilingual multimodal instruction data, enabling Aya Vision models to produce natural, human-preferred responses to multimodal inputs across many languages. Complementing this, we propose a cross-modal model merging technique that mitigates catastrophic forgetting, effectively preserving text-only capabilities while simultaneously enhancing multimodal generative performance. Aya-Vision-8B achieves best-in-class performance compared to strong multimodal models such as Qwen-2.5-VL-7B, Pixtral-12B, and even much larger Llama-3.2-90B-Vision. We further scale this approach with Aya-Vision-32B, which outperforms models more than twice its size, such as Molmo-72B and LLaMA-3.2-90B-Vision. Our work advances multilingual progress on the multi-modal frontier, and provides insights into techniques that effectively bend the need for compute while delivering extremely high performance.
Aya Expanse: Combining Research Breakthroughs for a New Multilingual Frontier
Dec 05, 2024



We introduce the Aya Expanse model family, a new generation of 8B and 32B parameter multilingual language models, aiming to address the critical challenge of developing highly performant multilingual models that match or surpass the capabilities of monolingual models. By leveraging several years of research at Cohere For AI and Cohere, including advancements in data arbitrage, multilingual preference training, and model merging, Aya Expanse sets a new state-of-the-art in multilingual performance. Our evaluations on the Arena-Hard-Auto dataset, translated into 23 languages, demonstrate that Aya Expanse 8B and 32B outperform leading open-weight models in their respective parameter classes, including Gemma 2, Qwen 2.5, and Llama 3.1, achieving up to a 76.6% win-rate. Notably, Aya Expanse 32B outperforms Llama 3.1 70B, a model with twice as many parameters, achieving a 54.0% win-rate. In this short technical report, we present extended evaluation results for the Aya Expanse model family and release their open-weights, together with a new multilingual evaluation dataset m-ArenaHard.
Global MMLU: Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation
Dec 04, 2024



Cultural biases in multilingual datasets pose significant challenges for their effectiveness as global benchmarks. These biases stem not only from language but also from the cultural knowledge required to interpret questions, reducing the practical utility of translated datasets like MMLU. Furthermore, translation often introduces artifacts that can distort the meaning or clarity of questions in the target language. A common practice in multilingual evaluation is to rely on machine-translated evaluation sets, but simply translating a dataset is insufficient to address these challenges. In this work, we trace the impact of both of these issues on multilingual evaluations and ensuing model performances. Our large-scale evaluation of state-of-the-art open and proprietary models illustrates that progress on MMLU depends heavily on learning Western-centric concepts, with 28% of all questions requiring culturally sensitive knowledge. Moreover, for questions requiring geographic knowledge, an astounding 84.9% focus on either North American or European regions. Rankings of model evaluations change depending on whether they are evaluated on the full portion or the subset of questions annotated as culturally sensitive, showing the distortion to model rankings when blindly relying on translated MMLU. We release Global-MMLU, an improved MMLU with evaluation coverage across 42 languages -- with improved overall quality by engaging with compensated professional and community annotators to verify translation quality while also rigorously evaluating cultural biases present in the original dataset. This comprehensive Global-MMLU set also includes designated subsets labeled as culturally sensitive and culturally agnostic to allow for more holistic, complete evaluation.
Aya 23: Open Weight Releases to Further Multilingual Progress
May 23, 2024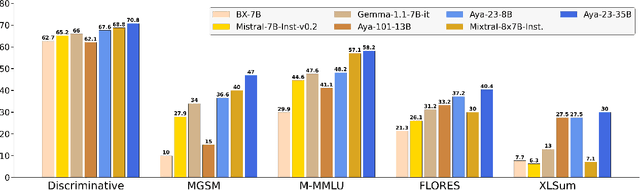

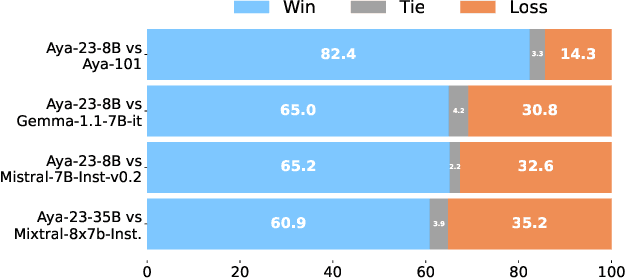

This technical report introduces Aya 23, a family of multilingual language models. Aya 23 builds on the recent release of the Aya model (\"Ust\"un et al., 2024), focusing on pairing a highly performant pre-trained model with the recently released Aya collection (Singh et al., 2024). The result is a powerful multilingual large language model serving 23 languages, expanding state-of-art language modeling capabilities to approximately half of the world's population. The Aya model covered 101 languages whereas Aya 23 is an experiment in depth vs breadth, exploring the impact of allocating more capacity to fewer languages that are included during pre-training. Aya 23 outperforms both previous massively multilingual models like Aya 101 for the languages it covers, as well as widely used models like Gemma, Mistral and Mixtral on an extensive range of discriminative and generative tasks. We release the open weights for both the 8B and 35B models as part of our continued commitment for expanding access to multilingual progress.